The user wants me to translate a Chinese headline: "马卡龙用AI短剧崩老头" Let me break this down: - 马卡龙 (Mǎkǎlóng) - This is Macron (French president Emmanuel Macron), or it could be someone's nickname/handle. In Chinese internet context, this could refer to Emmanuel Macron given the phonetic similarity. But it could also be a creator's handle. Given this is about AI short dramas, it's likely a creator or account name. Actually, looking at Chinese tech/VC context, this might be a specific creator. But without terminology table, I should use pinyin or the most recognizable form. "Macaron" is also possible. Actually, in Chinese internet slang, 马卡龙 could be a person's handle/name. Let me think... In the context of AI short dramas (AI短剧), this is likely a creator account name. I'll use "Macaron" or keep as "Makalong" if it's a handle. Actually, given this is a headline style, it's probably

"Pulling oneself up by one's own bootstraps" — a self-perpetuating cycle that defies gravity.
"Pulling Yourself Up by Your Bootstraps"
Macaron is out hyping its latest funding round again, and I have to say, I'm genuinely sad about it 😭
Because Macaron — oh wait, they call themselves Mindverse now, self-identifying as a Neo Lab, aka a frontier lab building agent models — their hype game has been declining. They've sunk so low they can't even come up with fresh stories anymore. Instead they're resorting to obscure technical jargon to bamboozle clueless investors.
These past couple days, my WeChat has been flooded with Macaron. Everyone's been forwarding the glorious funding news from the great agent model lab Mindverse.
I laughed so hard I nearly spit out my drink. Who could keep a straight face reading this press release?
Sure, a $200 million valuation with $50 million raised across several rounds isn't that outrageous in today's frothy VC market.
But it's June 2026, and someone's out here saying they want to use LoRA to achieve continual model learning — and Meituan's strategic investment team actually ponied up the cash to support this dream.
I need to call out Meituan's strategic investment team here. Delivery drivers bust their asses for pennies per order, even less these past couple years, and this is how you're pissing away their hard-earned money on some Neo Lab.
Look at Meituan Longzhu next door — they went big on Kimi at the top, investing in actual frontier models. Their financial investment team clearly has better taste than strategic investment. Meituan should just dissolve the strategic team already. Financial investment > strategic investment, apparently.
Back to the main topic. Let me explain how Macaron is pulling off its "stairway to heaven."
Macaron claims that agents need large models that can continually learn from real tasks, and "the key to achieving continuous evolution lies in LoRA technology."
The first half is obviously true. But I lost it when I saw LoRA, because I've actually used this thing. I actually know what it does.
LoRA is one of several techniques used in the post-training phase of large models — what we more commonly call fine-tuning. Its most popular use case is slapping filters on image models, like bypassing restrictions to generate NSFW content 🥵
That's basically it.
The principle, in one sentence: LoRA is a skill pack you mount onto a large model. You train a small set of parameter patches on limited data, and without re-pretraining the whole model, you can give it specific skills or styles.
One engineer buddy put it this way: "Nobody really researches LoRA anymore. Back in '23-'24 when model capabilities were terrible, fine-tuning made sense. Now you just use prompts to steer models — there's zero need for fine-tuning."
In fact, the easiest way to experience the complete LoRA workflow is to spend ¥169 on a Liblib premium membership 😘
Yes, you read that right. Training LoRAs is a legacy feature of image generation sites. When I told my Liblib contact I'd been burned by this thing, their first reaction was: "That's ancient, why'd you even think of it?"
Of course, it was all for the love of Macaron.
Training a LoRA for image models is simple. I uploaded 80+ Zang AI cover images and selected Qwen Image. Since LoRA modifies localized model weights, users can only use it on open-source models.
Then Liblib spent about ten minutes spitting out a LoRA plugin. I tested generating a few images. Despite the prompt containing zero mention of "retro pixel art style," it generated images in exactly that style.
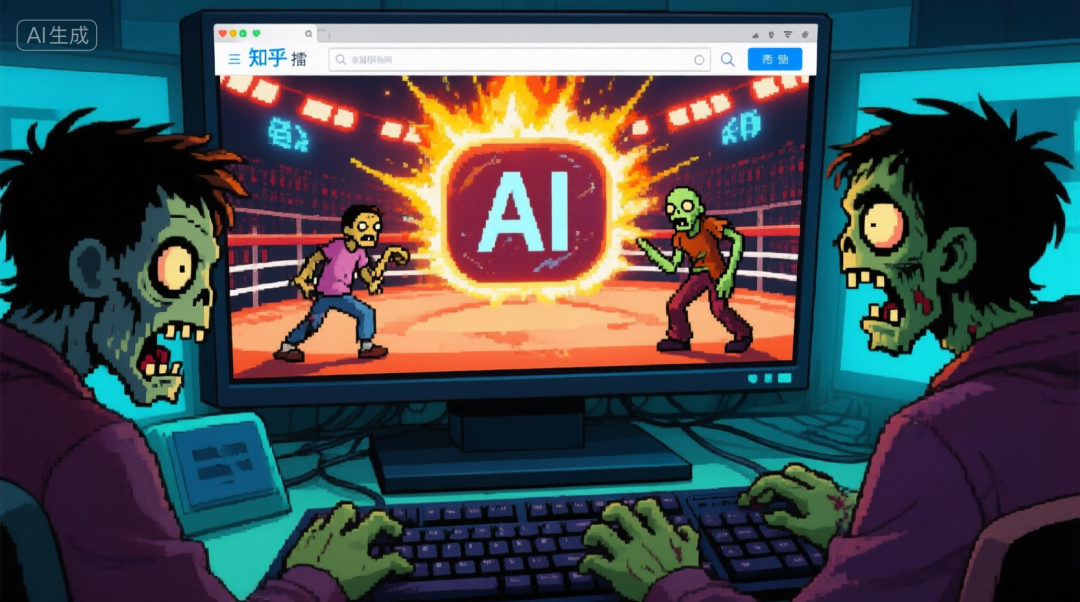
As shown above, LoRA ≈ slapping a filter on a model.
As a control, I sent the same prompt to plain Qwen Image. The generated images naturally lacked Zang AI's specific style, be like ⬇️
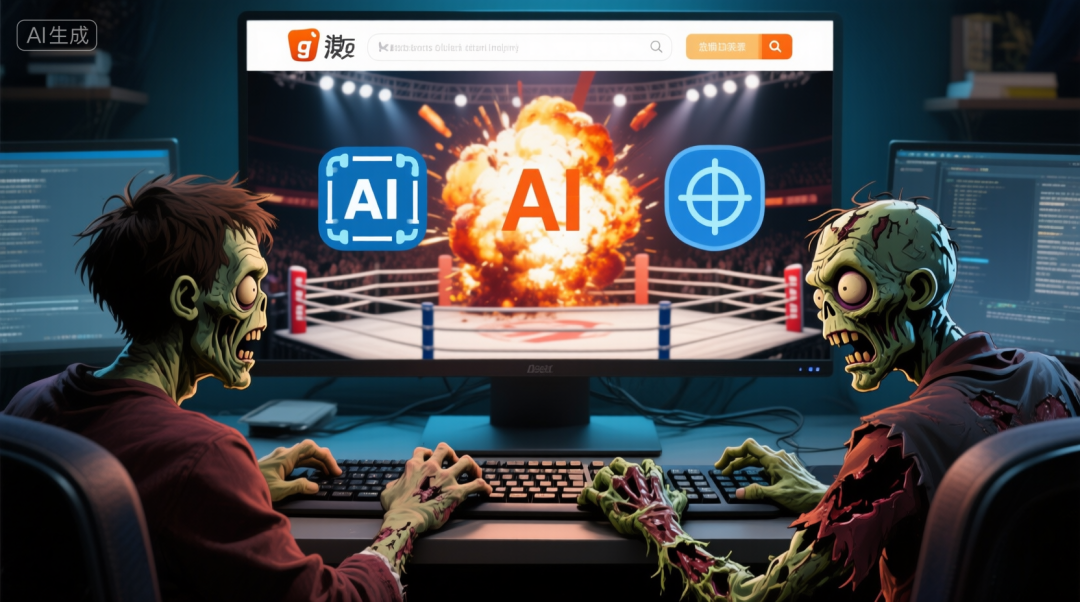
A more practical use case: most image models restrict sexual content. For open-source models, you can train a specialized LoRA plugin to bypass these restrictions. (We absolutely do not condone this evil use case.)
But that's about it. I genuinely don't know what other practical applications LoRA has.
I asked several agent product founders and engineers — not a single one had seen LoRA used in actual text model production. If anyone out there is using LoRA in production, please teach us in the comments 💗
Of course, Macaron claims their LoRA is different from your average image filter. Theirs is an advanced LoRA skill pack that lets large models load thousands or tens of thousands at once.
They even coined a new term: "mixture of LoRA." Meaning they're also building a LoRA routing layer, so the large model can activate relevant LoRAs during inference.
What a beautiful story. Except this pitch has been recycled 114,514 times already. Clever readers may have noticed: Macaron's LoRA and Skill occupy the exact same niche.
Letting large models load skill packs to complete specific tasks more expertly. These skills can be continuously updated, letting the model learn from real tasks and get smarter.
Wait, isn't this EvoMap's story? Is Macaron also "the world's first AI agent self-evolution and collaboration infrastructure"?
Everyone's running the same playbook, just swapping "Skill" for "genes" and "LoRA." And honestly, I think Skill wins by a mile.
First, Skill is simpler and more user-friendly. You can literally tell an agent in natural language to package historical conversations into a Skill. And Skill already has a mature ecosystem — any agent user can seamlessly adopt it.
LoRA, on the other hand, modifies the model's weight layers. Besides the model makers themselves, users can only use LoRA on open-source models. Claude, GPT, and other closed-source models? No dice.
Most importantly, LoRA has no users. Even image model users barely touch LoRA anymore, let alone anyone using it in production.
Because today's models have improved so dramatically. Open-source models like Qwen, Kimi, and DeepSeek can basically handle all everyday text and coding tasks.
I personally use Opencode with DS V4 Pro and Qwen 3.7 Plus for organizing financial data, English study notes, maintaining the beautiful Zang AI website (funeralai.cc). Costs me under ten yuan a day, and I barely encounter errors.
Then Macaron suddenly announces they're "reviving" LoRA, throwing around buzzwords like "thousands of faces, continuous learning, personalization, atoms and molecules, biology, cell membranes."
My assessment: not as good as EvoMap.
Of course, Macaron's self-identity is "a frontier lab building agent models" — exactly the Neo Lab concept that's been the hottest thing in VC these past couple months.
Since it's a lab, it's perfectly reasonable for Macaron to focus on reviving obscure, niche LoRA technology and wrap it in a super-duper mega beautiful story. After all, we can't disprove that this technical path won't yield great results.
Regardless, best wishes to Macaron on their LoRA revival.
But here's another sad part: Macaron now calls itself Mindverse — not only sharing a name with Fangbo Tao's company, but barely mentioning its original product Macaron anymore.
They even stitched Macaron into a new narrative: Macaron isn't a consumer product, but rather the model's "agent harness," like Claude Code is for Claude.
I'm genuinely sad. When Macaron launched half a year ago, they called it the world's first personal agent, promising various customizable mini-programs to meet users' personalized needs.
At least the founder added: "Macaron now has over 2 million users, more than 100,000 DAU."
Truly unhinged, because I actually know how Macaron got its users.
Search "Macaron ai story code" on TikTok and you'll find a bunch of AI short videos with voiceovers reading web novels, displaying numeric codes on screen, guiding users to download Macaron and enter the code.
Then users can read the complete web novels inside Macaron.
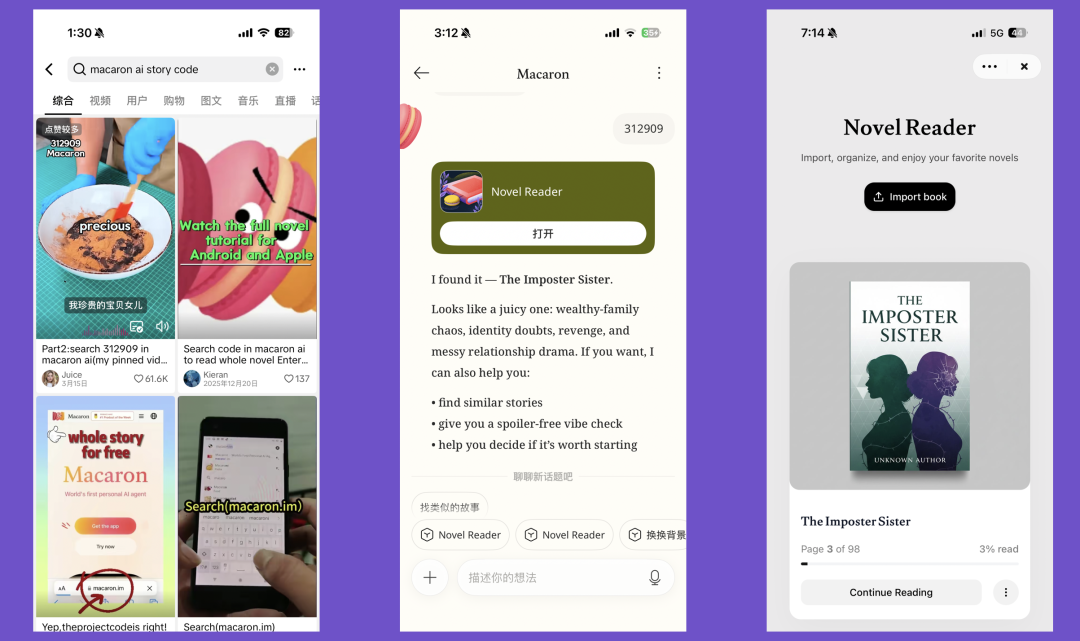
I laughed my ass off the first time I saw this scheme six months ago. How did the Macaron team even come up with this divine strategy?
The most hilarious part: the web novels inside Macaron are completely copied from Zhihu's paid Salt Selection stories — direct translations, not a word changed. A quick search and I found the original Zhihu versions.
Wonder if Macaron paid Zhihu for the copyright? If not, Zhihu should absolutely sue.
Some old-school investors are still wondering if they just don't understand young users. No — you don't understand Zhihu Salt Selection. You didn't realize how many overseas users love reading Salt Selection stories in Macaron.

Reading English Salt Selection novels is truly unhinged 😅
Let's review again. The founder said the Macaron app mainly serves to provide the model with "a real, long-term, continuously feedback-generating agent harness and training environment."
I can't even imagine what a real, long-term, continuously feedback-generating web novel app would train. So this is Mindverse's core technology 😭
I suggest Macaron partner with LibTV, integrate the Seedance API, and generate AI short dramas with one click. Primary goal: help Mindverse collect high-quality user feedback data. Secondary goal: probably pull in some users.
Let me wrap this up.
Even with all the god-tier products that emerged in 2025, Macaron remains the most god-tier of them all. First, it's completely useless. Second, it's been copied by a bunch of major companies.
Ant Lingguang follows the exact same playbook as Macaron. I even wrote an article suggesting Ant Group acquire Macaron. Most humorously, Macaron's previous round was indeed invested by Ant.
Even Baidu's Miaoda is still pitching one-sentence mini-program generation today.
I genuinely think if they'd stuck with the Macaron product, they might actually be doing pretty well.
Sure, these past few months everyone's been bearish on applications, all talking Neo Lab, world models, frantically pretending to be model companies to satisfy investors' desperate performance needs.
But market enthusiasm comes in waves. In '23-'24 everyone was talking about the greatness of the model layer. In '25 after Manus popularized agents, we got the AI product wave.
This half-year, Anthropic and OpenAI's valuation performance, plus Zhipu AI and MiniMax's stock market surges, have driven the primary market to re-embrace models. Kimi went from $4 billion to $20 billion. Numerous world models and so-called Neo Labs claiming to build every layer of the model stack are getting valuations that completely surpass application projects.
Last year, an AI application with a $100 million angel valuation was a huge deal — basically Lie Guo tier. This year, a PhD student claiming to build models, founding a Neo Lab with a $100-200 million angel round, has become normal.
I can only say you investors are too extreme. Either extremely bearish or extremely bullish. Seems like the VC industry has some magic that auto-upgrades you to binary thinking upon entry.
As for why there are always so many god-tier projects in the market?
A friend put it well: "There are no natural disasters in the primary market, only man-made ones. Dumb projects getting funded is mostly driven by investors eager to deploy/prove themselves, or internal competition. Internal competition most efficiently produces dumb investments."
Back to Macaron. While the current market wind is blowing toward models, one basic fact remains: AI落地肯定要靠产品,并且模型厂的那一堆生产力产品不可能吃掉大部分市场份额。
Macaron has already proven to be a product format that makes old-school investors FOMO. If they'd kept at it, their valuation might well be much higher than this lab pivot.
I really doubt whether investors chasing Neo Labs have actually thought this through. In the US, Neo Labs are refuges for senior scientists who lost internal power struggles — mainly respecting their seniority and industry standing, with the side bet that they might pull off something big, and if not, get acquired.
But in China, none of this applies. Describing Macaron from results: started with a product, pivoted to Neo Lab shortly after launch. Labs can't be disproven in the short term, investors only care about short-term performance, hard to get blamed.
Even more gloriously, the world's largest Neo Lab, Thinking Machines founded by the OpenAI CTO who lost an internal power struggle, is valued around $50 billion. Macaron is only $200 million — roughly 1/250th.
Everyone's winning big.
Suddenly thought of something: if Vivix's Liu Yu and Zhang Yueguang claimed to be an algorithm lab, would nobody say their product sucks?
(Cover image generated by ChatGPT, purely human-written text)