PixVerse Builds World Models Like It's Dreaming

A model with strong agency

"A Model with Serious Main Character Energy"
Has the AI space's vocabulary inflation gotten a little out of hand this past year?
Every other day it's "another DeepSeek moment," every other day it's "ushering in the era of XX." Any product launch or feature update has to send the wheels of history barreling forward.
I'm just here like, time please slow down, stop making me older 🎶
The latest thing pushing me closer to retirement is PixVerse R1.
The moment this product dropped, it was the DeepSeek moment for AI video, the infinite streaming era had begun, and the internet family was once again shocked and thrilled.
So I too followed the crowd and tried out this "world's first general-purpose real-time video generation model supporting up to 1080P resolution."
As for what real-time video generation actually means, we'll get into that later.
After entering the invite code, I found that PixVerse R1 had thoughtfully prepared several world templates for us.
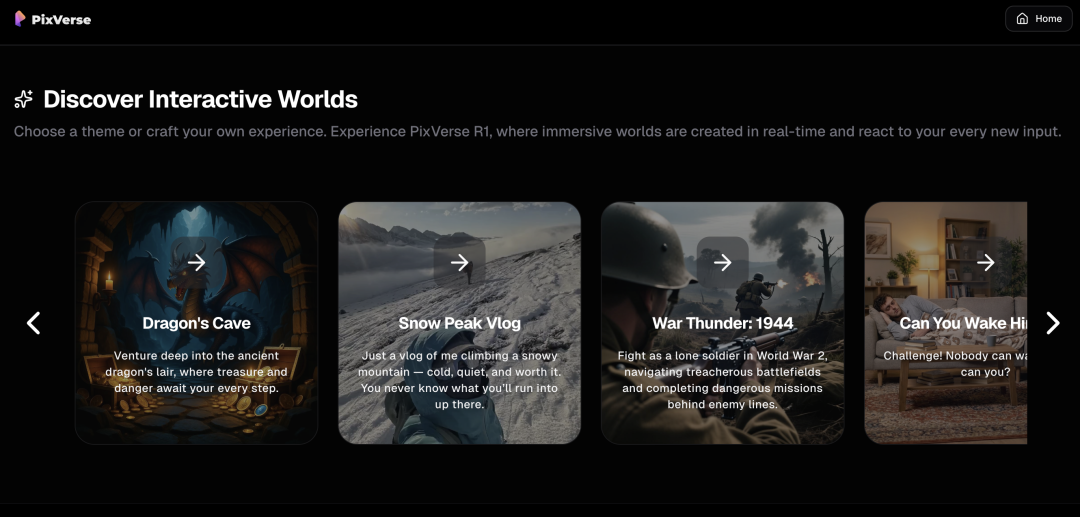
From Dungeons & Dragons to Zelda, from skiing and diving to moonwalking — artsy types, faux middle-class folks, anime enthusiasts, and all manner of niche hobbyists can find their place here.
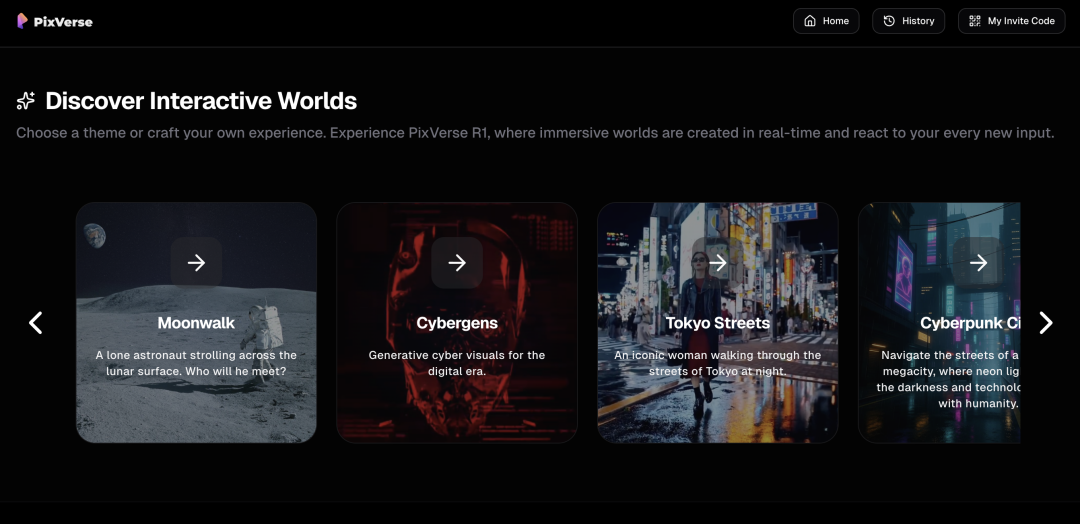
And even if you don't find one, you can input prompts to customize your own world.
You can choose aspect ratio and camera angle too.
I was lazy, so I just clicked on a template called Tokyo Streets and tried strolling around Tokyo.
Hit start, and the video began generating automatically — a woman in black top and red skirt wandering through a bustling crossing.
And she just keeps wandering, the scenery shifting as she moves, with surrounding skyscrapers and passersby all generating in real time.

This is also one of PixVerse R1's marketed highlights: no human intervention needed, the video generates itself in an infinite stream.
Right now it's capped at 5 minutes for the free demo, but technically it could generate forever.
A video model with serious main character energy.
Then, if you too have some Juche ideology, you can input prompts in the dialogue box at the bottom of the page to change the video's direction at any time.
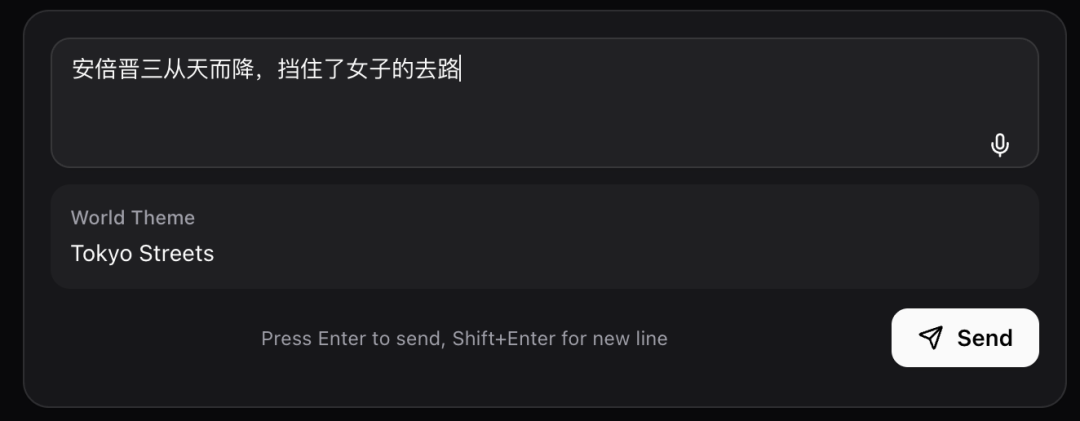
So I cooked up a scenario in my head: the woman pretends to be casually strolling (editor's note: Northeast Chinese slang for hanging out) through Japanese streets, but is actually preparing to carry out righteous justice on Shinzo Abe, before finally being rescued from court by Godzilla.
I ran it through PixVerse R1, and it generated the following masterpiece.
Unlike the currently popular Sora 2 or Veo 3, PixVerse R1 can indeed achieve near-real-time generation.
Within 5 seconds of entering a prompt, the scene changes.
And it's not a hard cut — the footage is continuous.
But I gotta say, there are plenty of problems.
For instance, while the footage is continuous, the transitions aren't smooth. Honestly, I'd say it's worse than a dissolve transition.
In one scene of my short film, I had the female lead take a taxi to the courthouse and enter the building.
The taxi ended up doing a literal phantom tank reveal, and the courthouse building just sprouted from flat ground.

Since when did Japanese infrastructure work this fast?
Another example: add too many people and everything falls apart.
When I assigned the female lead a Tetsuya Yamagami side quest, the entire scene completely collapsed.
I input two prompts:
"Shinzo Abe descends from the sky, blocking the woman's path; the woman pulls out a machine gun and opens fire on Shinzo Abe."
Can anyone make sense of what this generated?

The man appears, the woman disconnects, but in the end the man directly transforms into a woman — there's too much inflammatory content here for me to process.
But overall, this isn't even a question of whether character consistency can be maintained. It's whether the character can even maintain a consistent gender.
And then there's what I understand least: this female lead is forever walking, forever citywalking, forever moved to tears 😭
Whether facing evil public trial:

Or encountering Godzilla suddenly appearing on the road:

Or even after being attacked by nuclear wastewater:

Sis just pretends nothing happened, treating walking as methodology.
And maintains zero interaction with anything that appears, preserving that detached, aloof aesthetic.
Even when I explicitly issued commands, literally begging the female lead to stop, she follows in Hirokazu Kore-eda's footsteps — still walking, forever on the road.

Like she's Lost in Translation or something.
This got me thinking: If your real-time generation just throws elements in like stickers, with no interaction with characters and no plot advancement, what meaning does this actually have for video?
Because I've seen many bloggers say this PixVerse R1 enables infinite exploration, can be used for tabletop RPGs — I sincerely ask, how exactly are you running campaigns with this?
The protagonist just keeps walking, sees NPCs but doesn't talk, encounters companions but doesn't recruit, learns skills but doesn't use them, finally meets the boss but doesn't fight, and the boss doesn't fight back either — just keeps walking. More walking than actual walkthroughs.
Fam, this isn't a tabletop RPG, this is a power-walking club.
As for character distortion, garbled text, I figure these are just early-stage product issues that will definitely get optimized over time.
But those three points above genuinely made for a painful user experience.
Now someone might say: judging PixVerse R1 by traditional AI video standards is highlighting its weaknesses while ignoring strengths, is unsportsmanlike sneak attacks.
Because, you see, our PixVerse R1 isn't simply an AI video model — it's a W · O · R · L · D · M · O · D · E · L.
What's a world model? Honestly I hadn't looked into it carefully before. After searching, I found the term is in a discourse battle phase, with every camp having their own definitions and products.
Fei-Fei Li's Marble and Google's Genie 3, for instance, generate expandable, manipulable 3D worlds.
NVIDIA's world model belongs to their Cosmos project, generating video for robots to watch, used for training self-driving cars and such.
PixVerse R1, meanwhile, is more in the vein of Odyssey-2: first define a theme, then generate infinite continuous video, with the ability to input prompts mid-stream to make changes.

The Odyssey-2 interface
I tried Odyssey-2 too and found that as video generates, the angle keeps tilting upward, characters keep getting bigger, and the footage gets increasingly unhinged — like a dream.
They probably know this themselves, so on their official site they proactively cover for it by saying their product is designed to simulate your real-time dreams.
Users just punch cotton. If it's all a dream, what can I even say? Same world model, same dream.
But this problem where Odyssey-2's video gets increasingly unwatchable is a common ailment of real-time interactive video products.
As video keeps generating, initially minor issues and prediction errors continuously accumulate, causing longer videos to increasingly deform.
PixVerse R1's image quality is notably better than Odyssey-2's, but it hasn't improved on this problem.
I opened a template called Moonwalk, attempting to shatter the lie of the US moon landing.
At first the footage was pretty smooth and natural.

By the three- or four-minute mark, the background stars had pixelated,疑似地球流浪了黑客帝国情景再现了。

This issue of things getting increasingly unwatchable, PixVerse's own report does acknowledge.

To minimize this impact, PixVerse R1 appears to have used a massive memory wipe on itself.
Specifically, whatever you have the protagonist do — run or jump, change clothes or remove glasses, gender swap or shapeshape — within 5 seconds, it reverts to original form.

And whenever I tried adding any people, animals, terrain, or buildings to the scene, they would indeed generate, but within 5 seconds would all disappear too.

Then return to the starting point, beginning aimless walking, waiting for the next command.
How to put it — earlier I mentioned several schools of world models. Though their outputs differ, their core principle is unified: they must enable real-time interaction while maintaining logical continuity.
Or at least strive in that direction, otherwise how can you call it a world?
PixVerse R1 does perform well on real-time interaction.
But on continuity, it bypasses the problem entirely by forcibly returning to the starting point.
Right? It's not that we didn't generate this or that for you, or that later events have no impact — they just disappear on their own, we don't know why either, but our model is continuously infinite-streaming all the way to doomsday.
That's cheating, bro.
Aren't you just forcing yourself into the world model concept, trying to overtake on the curve and save the nation through exploiting the information gap with users?
Looking at the current state of universal praise across the internet, this move seems to be working.
Finally, let me be fair: PixVerse R1 does have its strengths.
For example, it genuinely is fun. Using other video models always carries this work mentality of needing to generate some masterpiece. With PixVerse R1 it's pure generation — furious, unbridled, not caring about results, just entertaining yourself. Pretty amusing.
And if it insists on calling itself a world model, it's still a rare world model that ordinary folks can actually get their hands on. Now that's true world unity.
But when video generation capability is still at the NPC stage of ranking from solid to terrible, is starting to mess with world models a case of trying to run before learning to walk, trying to hype before properly running?
(Cover image generated by ChatGPT, text 100% human-written)