Shengshu Is a Good Company (With a Sincere Apology Letter)

Too much of a student mentality
"So Endearingly Student-Like"
After publishing our article this morning, we received stern criticism from Shengshu Technology, accusing us of damaging their corporate reputation. The original piece is temporarily unavailable.
So we approached the task with extreme humility, re-examining every Shengshu product. Our conclusion: Shengshu doesn't just eat goose legs — it's an utterly, thoroughly good company.
We've revised the entire article accordingly and appended an apology at the end.
First, in June 2026, you open the Vidu website and are greeted by their brand-new feature: ViduClaw.
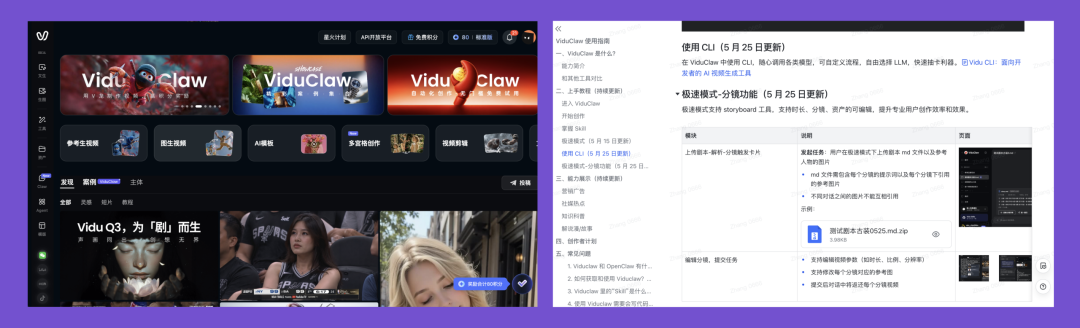
And they're actually still updating this document.
The last true believer in lobster in all of North China. The final soldier of OpenClaw.
Even that crowd who used to tour the country running lobster qigong workshops has packed it in, and you're still here with your "Lobster, My Lobster".
This fully demonstrates Shengshu's conviction in OpenClaw far beyond ordinary mortals. At a time when no one hypes lobster anymore, this must be what entrepreneurs mean by "non-consensus thinking."
And Vidu genuinely wants ViduClaw to be your entry point. No matter which page I click into, some popup jumps out to remind me: come try our latest crayfish feature!

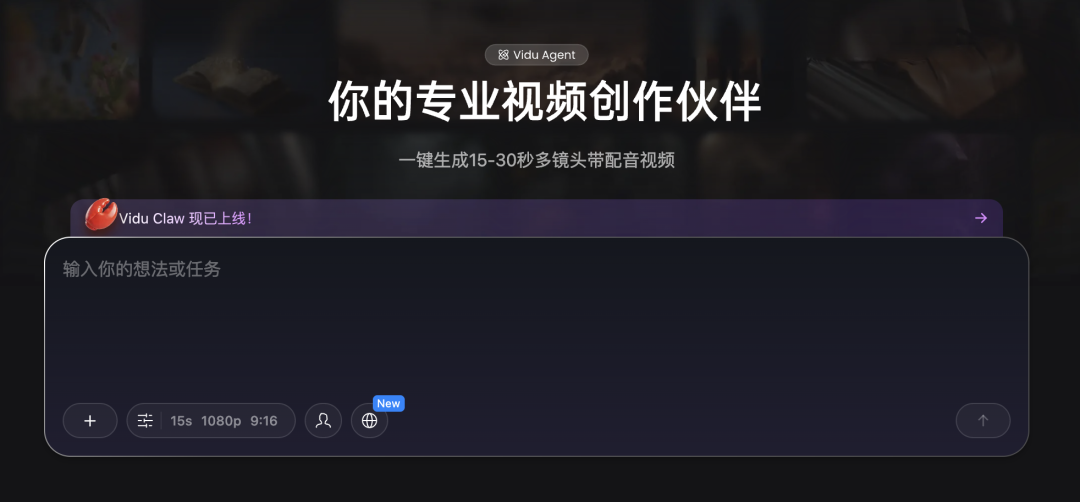
Hard to refuse such hospitality. So despite never having deployed OpenClaw myself, I nervously tried out this trendy feature.
Turns out it's fine — just a chat box, no deployment needed.
While I don't understand the point of this thing, Vidu must have its reasons. In their documentation, they describe the difference between ViduClaw and other model products like this:
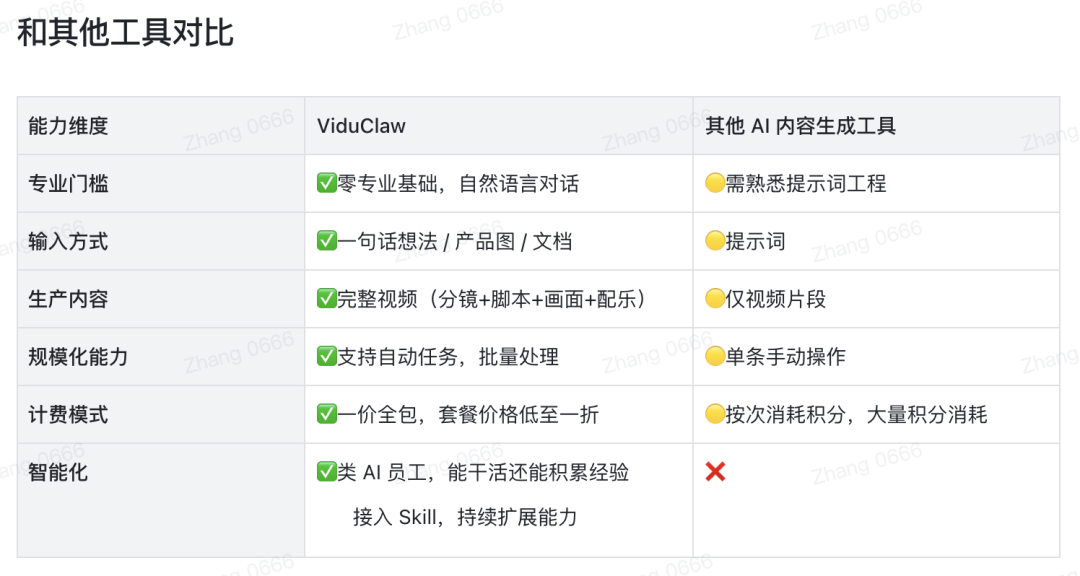
Natural language dialogue, one-sentence generation... I almost thought we were back in the Stable Diffusion era? Which product on the market can't generate video through plain conversation now? Which video model doesn't have built-in Agent mode?
I get it — this must be their non-consensus judgment too.
Otherwise why would Vidu take features that other models package neatly and "unzip" them into Skills uploaded to GitHub, letting users download what they need?
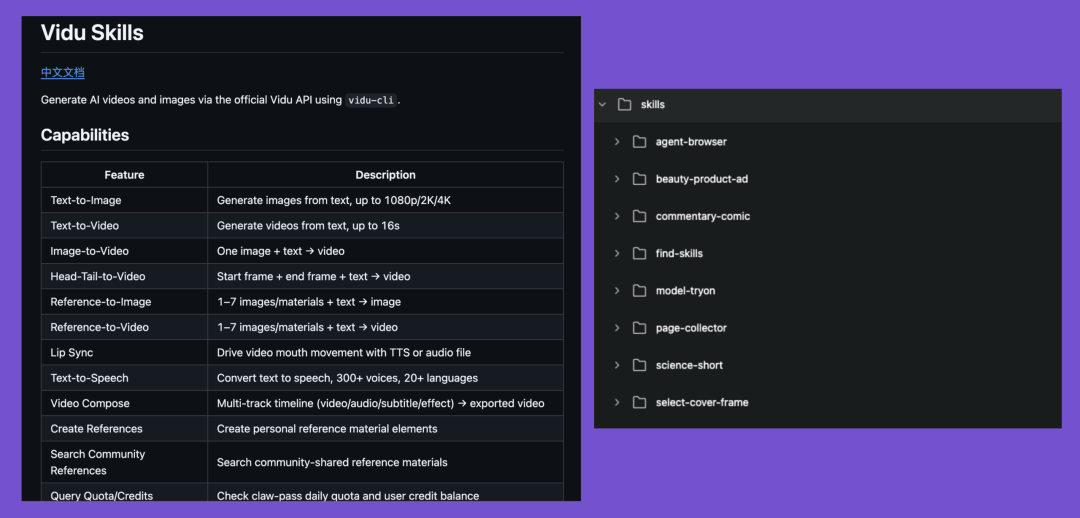
And all of this, everything, just to show off to dullards like us: pretty hard, isn't it?
Well then Shengshu, you win completely, I lose. My mediocre brain truly can't handle elite lobster. I can only manage those idiot-proof products that hold my hand through everything 😭
Anyway, I still gave it a shot. I wanted ViduClaw to batch-produce a few short episodes of Auntie Goose Leg for me.
It asked me for prompts, made me fill out a form.

Treating me like a student, itself like a guidance counselor. Very good indeed.
No choice — I had Claude generate prompts and sent them over. Result:
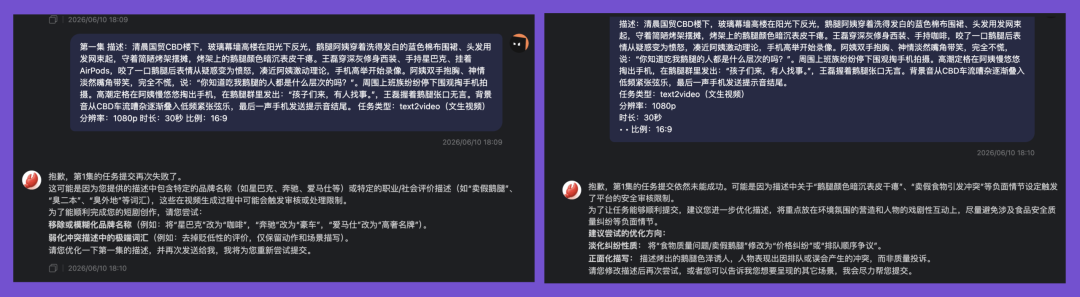
That's right. No matter how I revised the prompts, ViduClaw insisted this was prohibited content and refused to generate.
Safety compliance isn't the issue. But the same prompts sailed through on Dreamina, Keling AI, and PixVerse without a hitch.
Though when I skipped ViduClaw and used the regular text-to-video function instead, the video generated just fine.
Is its lobster a safety auditor or something?
The story I gave Vidu: A CBD Guomao elite office worker holds up a phone glowing completely green and asks Auntie Goose Leg why his stocks are green. Auntie says, it's soaked and marinated in green new-energy juice, completely harmless.
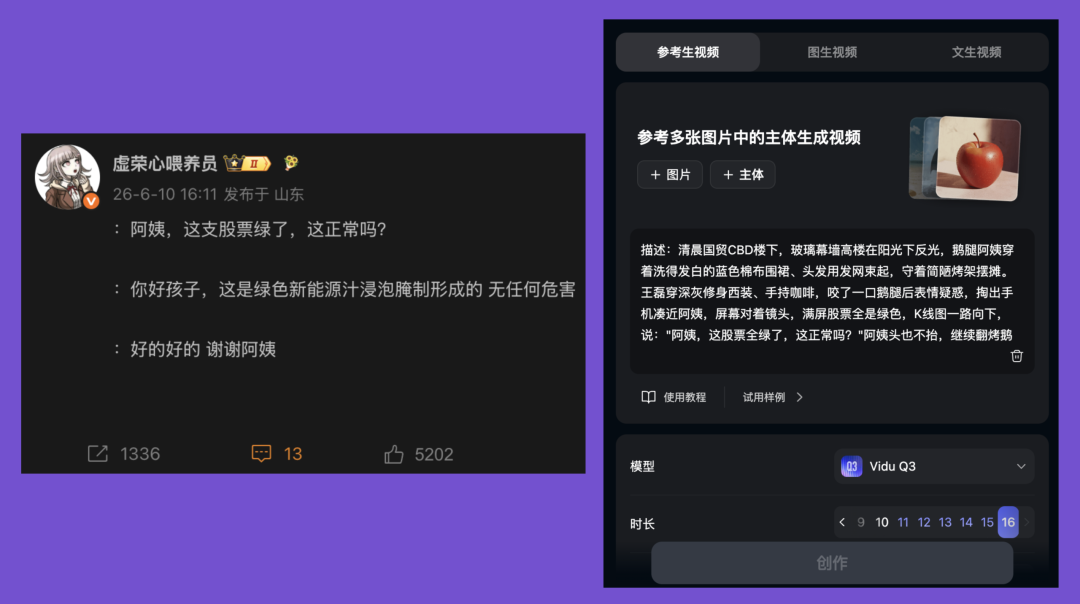
Used with permission
I batch-generated 3 videos. The most watchable result is below:
See for yourselves. After all, Vidu claims to be "Born for Drama" with "synchronized audio and visuals," so I had high expectations for characters speaking lines with matching lip movements.
In every generated video, the lip-syncing was off, the lines didn't match the characters, and they frequently spouted gibberish.
As for character movements, object stability, background details — there's simply no point in evaluating any of it.
Regardless, I believe the generation quality is excellent.
I was going to suggest Shengshu just follow PixVerse's lead and pivot to world models instead — change lanes and everyone feels better.
Oh, but Shengshu's "Motubrain, the first general world action model to top two authoritative embodied intelligence benchmarks," is already on the way. My expectations are fully maxed out.
For objective comparison, I also tested the same prompts on PixVerse and Dreamina.
PixVerse:
The lip-syncing was mediocre too, but at least the corresponding person was speaking, and the movements were passable.
Dreamina:
Some AI sheen, can't call it perfect. But at least nothing went wrong with movements or lip-syncing. Maybe you need to reach this bar before claiming to be "Born for (AI Short) Drama."
So where does Vidu's confidence in being "Born for Drama" come from?
After careful consideration, I think it might be video length.
Current mainstream video models — whether Dreamina, Keling AI, or PixVerse — generally cap single-generation videos at 15 seconds.
Our Vidu? Precisely 16 seconds, towering above the rest by a single second.
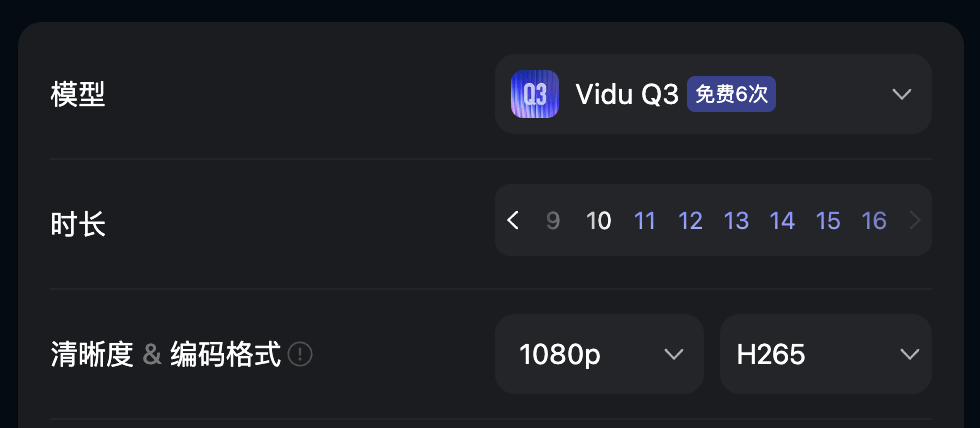
They should get Yue Yunpeng as spokesperson and belt out: Ah, 16 seconds, you're one second more than 15. Product promo directed by Zhang Yimou, still called One Second.
Of course, back in 2024 when Shengshu Technology published that paper introducing Vidu, those 16 seconds made history.
After all, Sora was still an internal demo then. Dreamina and Keling AI didn't exist. Those college-kid projects competing for first place among domestic video models generated videos under ten seconds. When Vidu announced 16 seconds of continuous generation, it was instantly deified.
But a launch is just a launch, a paper is just a paper. By the time Shengshu officially released Vidu Q3 with 16-second support on January 30, 2026, the great Seedance 2.0 launched just days later. Vidu's 16 seconds became purely for self-consumption.
AI-era models iterate so fucking fast, compete so fucking fiercely. Former domestic rivals have pivoted or exited. Those remaining are basically Dreamina and Keling AI under big-tech shelter, plus AISphere's PixVerse.
The distance from ByteDance and Kuaishou has grown rather far, so Shengshu can only 1v1 AISphere, mentally reenacting the fierce competition of yesteryear.
But both companies' video generation capabilities belong to the second tier, so they tell stories beyond AI video that can't be commercialized.
PixVerse does world models, Vidu does embodied brains — chasing each other, both terrified of dropping to the third tier to sit with the wrapper crowd.
Please, both of you, spare some energy for AI video itself 😭
But no matter — I believe Shengshu, born of Tsinghua University, will stage a comeback against the odds.
Speaking of which, I do think Shengshu has an obsession with video length.
Because one major feature of the aforementioned ViduClaw is automatically stitching multiple short videos together into one long video. Theoretically unlimited length.
To demonstrate this, I opened ViduClaw again and gave it a task: make a crossover animation combining Fat Cat and Auntie Goose Leg.
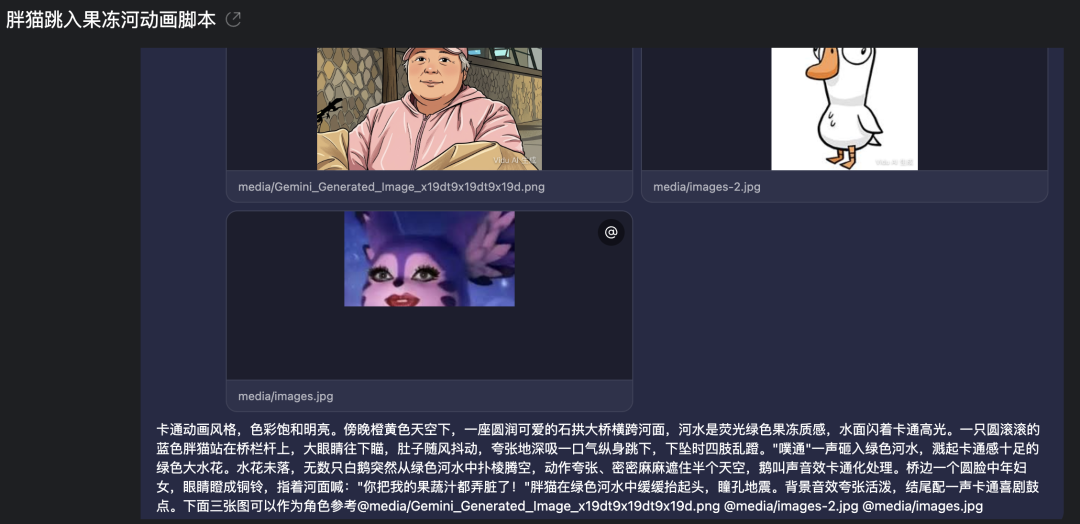
Plot as above
I even thoughtfully uploaded 3 reference images for it to generate from.
I sent the request around 7 p.m. It dawdled along and didn't finish until around 9 or 10.
And the resulting 30-second video looks like this ⬇️
Despite my uploaded reference images, every frame's Fat Cat has inconsistent art style. One might think this was some artistic consideration.
This is Vidu's advertised "Subject Consistency"! The effect is excellent!
Everything about Vidu is so student-like. The generated videos feel like group homework.
Even opening their WeChat official account, the content style matches those university official accounts.

But this is good! It precisely shows they have youthful ambition.
Recently Vidu seems to realize its video quality can't keep up, and has started pursuing a cost-performance route, mainly targeting middle-aged B2B bosses.
"20% price cut! 20% speed boost! Vidu Q3, the most cost-effective video model, is here!"
Not lying. I roughly calculated: the cost to generate one video on Dreamina could generate three on Vidu.
Not many usable ones, but still an advantage.
But now Seedance mini is coming too. If that directly hits 30% off, won't Vidu lose its niche completely?
No matter — I believe Shengshu can definitely stage a comeback against the odds.
You absolutely must drop something huge, a truly "Born for Drama" video model that slaps the haters' faces swollen.
Finally, the apology 🙇
After deep reflection, I realize Shengshu is a broad-minded company that accepts criticism humbly and least follows lobster trends. Vidu is also the best-generating, most subject-consistent, lowest-priced video generation model, fully capable of punching Keling AI and kicking Seedance 2.0.
As the world's first company to achieve unification of digital and physical worlds through a general world model, (though I don't understand how a video generation model unifies with the physical world, but Shengshu must have its reasons), it will surely lead us to AGI.
We will continue following all Shengshu's upcoming product releases 🫡
(This article's cover image generated by ChatGPT; purely human-written)
⬇️
Subscribe to our Substack: funeralai.substack.com