World Models Took Some Detours

Might as well just use a digital human.
"Might As Well Just Use a Digital Human"
In my humble opinion, the concept of "world models" has gone through three deeply comical stages.
Stage One: The old guard in Silicon Valley who actually knew what they were doing — people like Yann LeCun and Fei-Fei Li — felt large language models had run out of narrative runway, so they borrowed a new concept from academia to try and leapfrog ahead.
But the problem with these veterans was that they were all off doing their own thing, never bothering to align on definitions. And so the world of world models descended into chaos — ritual and music collapsed, so to speak.
Stage Two: Some video model companies that couldn't quite nail their core business did some "independent thinking" and decided that since real-time generation was now enough to qualify as a world model, they might as well stop building traditional video models entirely. Just build real-time video generation, call themselves a world model company, and be done with it.
And so Aishi, Happy Oyster, and the like all launched with world models as their compulsory side dish — sorry, "groundbreaking debut."
Right? And the general public has no idea what a world model is supposed to look like anyway. Whoever ships something first, even if it's complete garbage, gets to seize the narrative.
Stage Three: Some evil hustle-culture types (like Vivix) started hunting for actual use cases for these real-time video generation models.
Virtual companionship, virtual streaming — suddenly all the other companies riding the world model wave couldn't get by on incomprehensible demos anymore. They all had to start pretending to think about consumer needs, all had to start rebranding themselves as digital human companies.
And in recent months, such companies have emerged in batches, as if by coincidence.
Take Catnip, for instance — the heavily hyped 10-person Gen Z team behind MaineCoon. They claimed to have built "the fastest streaming audio-visual social model in history." I thought, finally, someone not riding the world model buzzword.
Then I clicked into their website. Turns out they'd simply declared they'd invented an entirely new category of world model: the Social World Model.

You people are exhausting yourselves with this terminology. Might as well call them First World Models, Second World Models, and Third World Models from now on.
I looked it up — Catnip's team was still building AI video interactive products at the end of last year (which presumably explains where "social large model" came from), still thinking about how to acquire users cheaply. And now, riding the world model wave this year, they've magically developed model training capabilities?
How did we get to this point where slapping some post-training on an open-source framework lets you call yourself a world model? Who started this trend?
The terminology games aren't even the most god-tier part. They also invented their own benchmark called SocialVideo Bench, then published their own leaderboard and declared themselves number one.
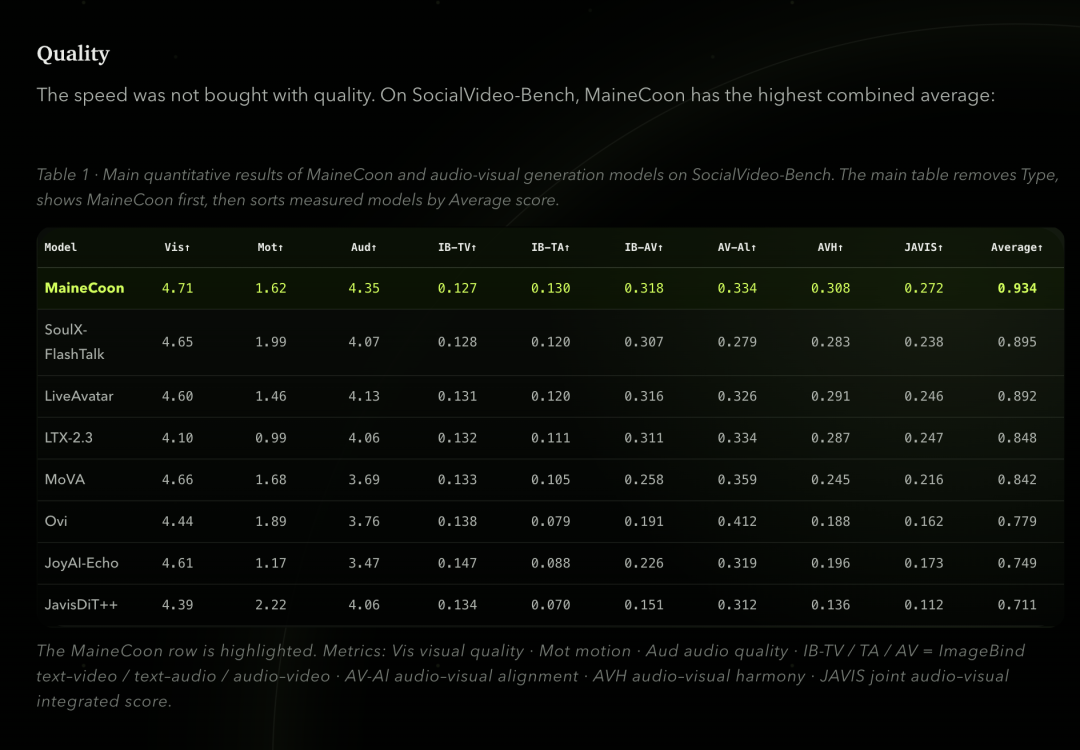
Organizing your own tournament, serving as your own referee, then scoring your own goals. The national men's football team should take notes — host a World Cup next year, why don't you.
This move, actually, our good friend Macaron has pulled before.
Macaron's heavily promoted Macaron-V1-Preview was essentially GLM 5.1 with five LoRAs added in post-training. Conveniently matching the benchmarks they ran one-for-one.
And in the four benchmarks where Macaron declared themselves first, the first two were benchmarks they created themselves.
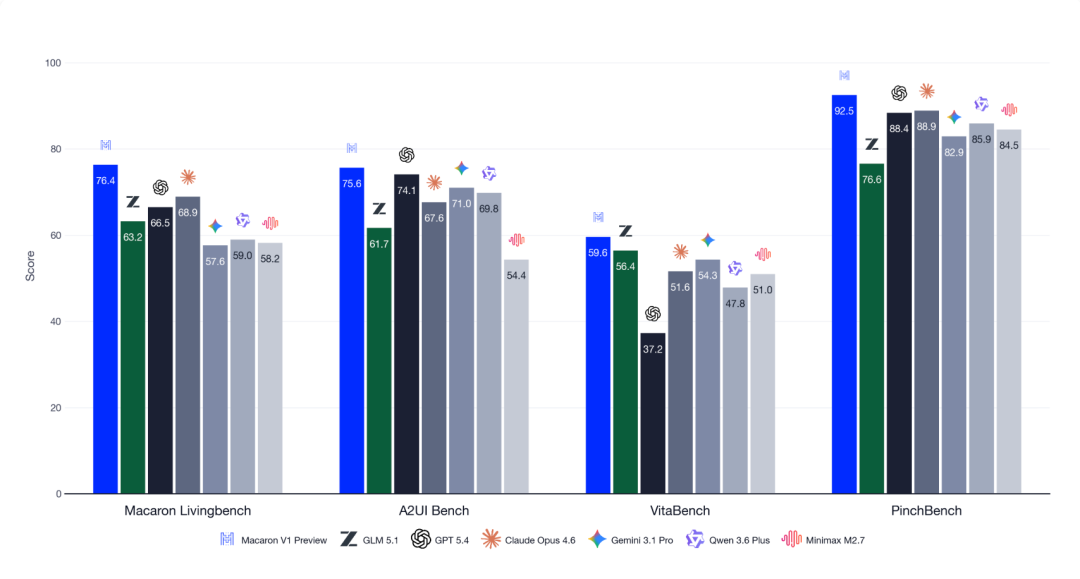
Not sure what to say anymore. So this is what "AI application companies pivoting to models" looks like.
How does that song go again — heard you're still working on something original, but after all this effort it's still more of the same~
But whatever. Zhipu AI is hot right now. Pure white-label OEM work, doing GLM 5.2 post-training for big clients — no doubt they'll rake in serious coin. You know, we've always believed Macaron is incredible ❤️
Back to our protagonist. Let's actually test whether MaineCoon has anything to it.
MaineCoon currently has two main features. First is Instant Video, focused on traditional AI video generation but with speed as its selling point. The team is remarkably confident — they literally slapped a "Fast & SOTA" badge right on this feature.
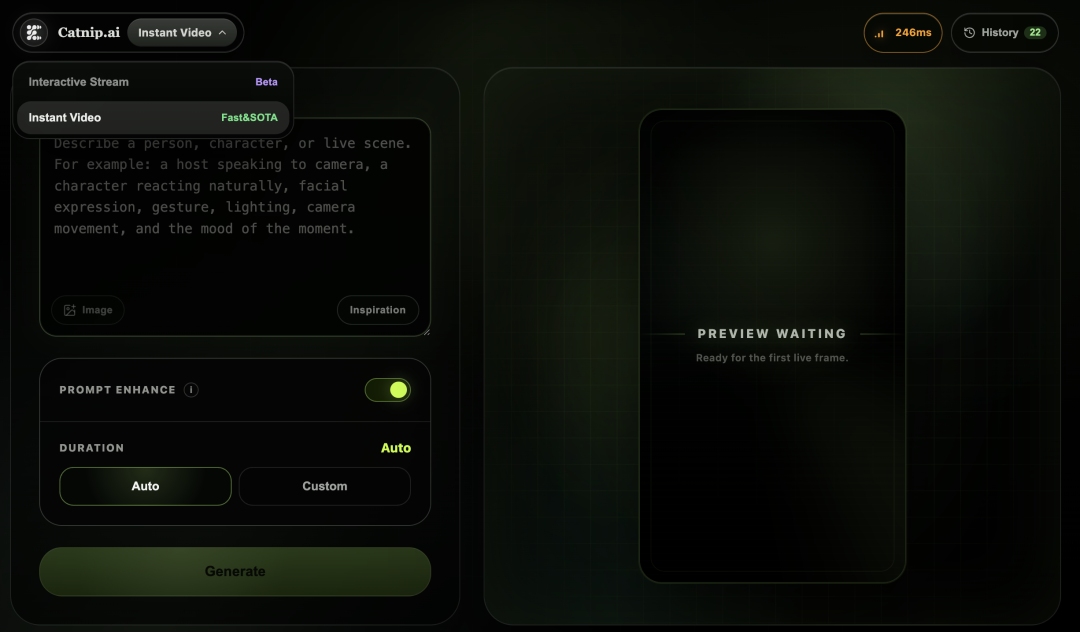
I tried it and it really is fast. Generating a 20-second video takes roughly 8–9 seconds. In the Fast category, it's genuinely SOTA.
But beyond fast, these videos have zero practical value.
For example, I entered this prompt: A World Cup match between Japan and Brazil. A Japanese player in a blue jersey scores a goal. The Brazilian goalkeeper in a flag-patterned shirt clutches his head in tears. In the stands, Japanese fans in kimonos dance and celebrate.
The result below ⬇️
As you can see, MaineCoon has clearly been mainlining Tarkovsky — only knows long takes, no concept of cutting. The main subject barely moves, just vibes. And it's all atmosphere, no action.
Plus, only the protagonist is relatively clear. Everyone in the background has been quantum-entangled into pixel soup. You'd think the Trisolarans had arrived early. Terrifying.
So as a video model, MaineCoon has nothing worth discussing. It's fast, but fast doesn't pay the bills.
But it has a second feature: streaming video generation, currently in Beta. The workflow is similar to Pixverse and 7verse that I tested before — generate a scene first, then use prompts to change the visuals in real time.
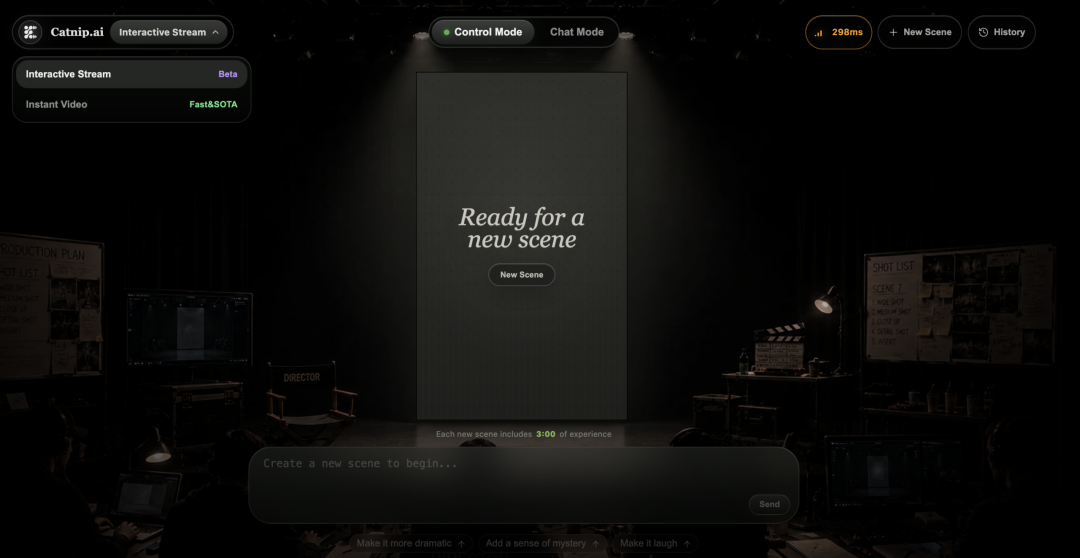
Two modes: Control Mode and Chat Mode
Control Mode means you're the director. Chat Mode means you're looking for company. I first used Control Mode to generate a food delivery driver running deliveries, then mid-scene had him hit by a car, beaten by the driver, arrested by police, and finally eating dumplings together. The result below ⬇️
Image quality has the same problems as video generation — all quantum people, all particle effects, like being in a dream.
On reaction speed: after entering a command, the scene changes roughly 10 seconds later. Pretty much standard for world models I've tested, middle of the pack.
However, in MaineCoon's generated world, characters do show some logical consistency — they change their scene, behavior, and dialogue based on events. This is genuinely better than previous world models with seven-second memories.
Finally I tested Chat Mode, generating a young werewolf hunk to romance me, making up for a certain otome game removing a certain male lead.
The result nearly scared me to death at midnight ⬇️
For some reason, MaineCoon's generated character keeps slowly inching toward the screen, presumably trying to kiss me. The face just keeps getting bigger, the mouth keeps multiplying. Junji Ito himself would need to call in a spiritual medium to calm down.
But this is indeed the most commercially imaginable of MaineCoon's three features:
Instant Video is fast, but Seedance has a mini version now too;
Control Mode is more watchable than other real-time video projects, but can this really help with embodiment or future prediction?
Only Chat Mode — despite generating characters that rival horror movie bosses — well, what if some people's tastes aren't human?
Divine. These streaming video generations might as well be called Liu-style generation videos. Either way, they're competing with Liu Yu for business.
Of course, picking the tallest from the shorties, MaineCoon is already one of the more successful hype plays in this space recently. Let's look at its competition:
That's right — the great Shengshu, after sending us their apology letter, has finally moved on from lobster people to study proper furries.
This real-time interactive model, at any other company, would definitely be called a world model too. But Shengshu has already started building physics-oriented world model Motus, so perhaps no need to chase clout here too.
I chatted with their homepage character "Fox Demon Yubao." Edited result below ⬇️
Where Shengshu beats MaineCoon: you can turn on your camera and talk face-to-face with the character, no typing needed, just speak.
And the character on screen can actually see your movements, like:
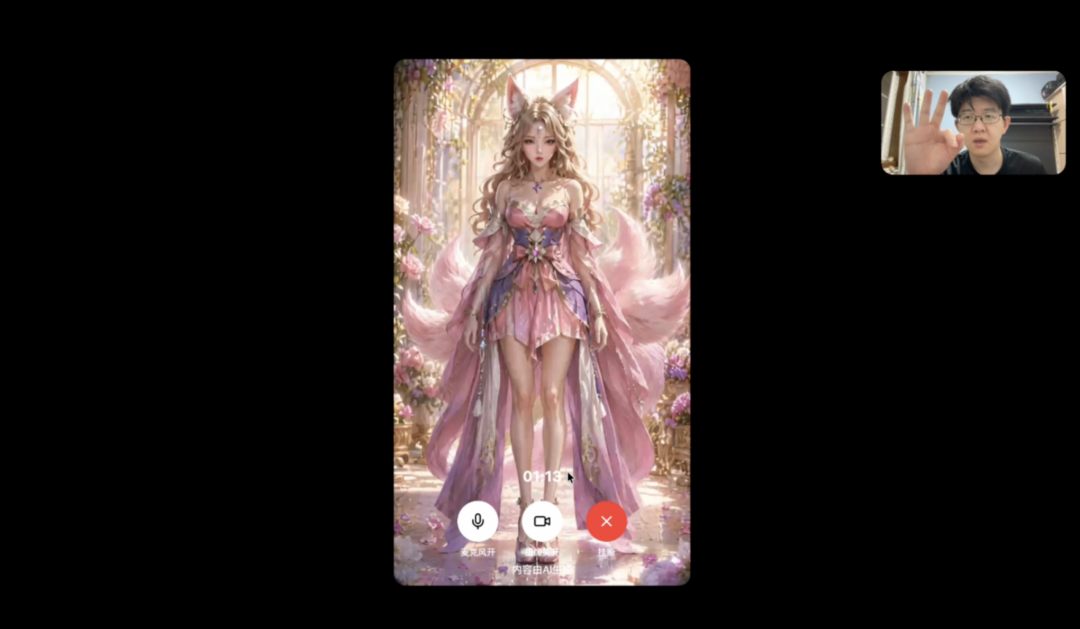
I asked her what number this was. She said three.
However, this observation of the user requires command triggers. Later, when I said nothing and just danced around, she had zero reaction — dead as a doornail.
And Shengshu, presumably to avoid scaring viewers like MaineCoon's wandering characters, imposed rigid constraints: stand perfectly still, eyes locked on the user.
So when I asked her to dance, she stood there muttering to herself like reciting scripture: "Gently sway shoulders, turn around, wave arms..." — reading the prompt aloud.
So when I asked her to turn around, she said: "I can't, because I have to keep watching you..."
👁️👄👁️ Little sister is watching you 👁️👄👁️
I suggest just rebranding as Uncanny Valley Simulator and launching on Steam.
I think MaineCoon Chat Mode and Vidu S1 have two fatal flaws as virtual companionship products:
First, 10 seconds of latency is a selling point in video generation. But when the user need is casual conversation, it feels prehistoric. We're talking human-AI romance here — who can accept a 10-second response delay?
Second, both products still have half-duplex conversation, like walkie-talkies. You speak, she speaks. You interrupt her, she doesn't shut up. Basically Xiao Ai assistant level — deeply disrespectful to users.
If you don't understand these two points, try calling Doujie. For casual chitchat, it's basically instant listening and response, with interruption anytime.
Doujie has already launched full-duplex with simultaneous listening and speaking. ChatGPT currently supports mid-interruption half-duplex, and has started internal testing of full-duplex too. The trend is irreversible.
Once you've tasted the fine grain of low-latency, fast response, who can stomach the coarse stuff?
Of course, MaineCoon Chat Mode, Vidu S1, and other real-time video generation products have excuses for not achieving this: beyond processing audio, they also have to process video — lip sync, character movement, all of it. Time-consuming, labor-intensive, token-guzzling.
But is it really necessary?
What you're building now — can't move, can't turn around, scene doesn't change — isn't this essentially just a digital human VTuber?
Then why take the streaming video technical path? Just invest in AI 2.5D modeling, make 100 avatars, plug in Doubao's voice model, and do lip sync. Done.
The user experience would absolutely surpass these current "world models."
On a similar track, ByteDance has OmniHuman, Kuaishou has Kling-Avatar, and Haoyu Cai's team even made LPM 1.0, proudly claiming full-duplex infinite streaming capability. Goes to show: as long as you don't force the world model label, everyone can have a bright future.
World models began as no path at all. Enough companies walked it, and a detour formed. Then entrepreneurs all started taking this detour, walking and walking until they forgot that the shortest path between two points is a straight line.
Pathetic.
Finally, a humorous news interlude.
HUYA Inc., with no news for 100 years, suddenly started doing AI recently — churning out a digital human model called VAM 1.0.
Anyone can see this is a somewhat outdated anxiety-alleviation product for upward reporting. But it still has stronger watchability and usability than those streaming-generated digital humans.
What else is there to say? Brothers, turn back before it's too late. You can fool investors, you can fool AI media editors, but don't fool yourselves.
If you truly have ideals about AI companionship, you might as well sell your company now, buy some silicone robots, and figure out how to install Grok in their mouths.
(Cover image generated by ChatGPT, purely human-written. Song request while we're at it.)
⬇️
Subscribe to our Substack: funeralai.substack.com