BioGeometry's Jian Tang: How to Build a "ChatGPT" for Life Sciences | Gaorong Ventures

Generative AI is powering drug discovery.
Generative AI, and especially OpenAI's ChatGPT, has been generating intense discussion lately. At the same time, a technological revolution called "AI for Science" is unfolding across fundamental scientific disciplines, and a group of scientists are asking: Could AI for Science and ChatGPT become the catalyst for leapfrog development in biomedicine?
Recently, Dr. Jian Tang, founder of BioGeometry, associate professor and tenured faculty member at Mila — the Quebec Artificial Intelligence Institute at the University of Montreal — shared his vision and experiments for applying generative AI to the life sciences at the Future Science Forum, and sought to answer: Is it possible to build a ChatGPT-like model in this domain?
Dr. Tang is among the earliest researchers internationally to apply deep learning to graph-structured data. As early as 2018, he recognized during his work on graph representation learning that the most killer application might emerge in biomedicine.
In 2021, Dr. Tang founded BioGeometry, dedicated to developing next-generation AI technologies including geometric deep learning and deep generative models for large-molecule drug discovery. "Our long-term vision is to develop programmable large-molecule drugs." Gaorong Ventures invested millions of dollars in BioGeometry's angel round in 2022.

The following is Dr. Tang's presentation (edited and condensed):

We are living in the best era for research, because we are simultaneously experiencing dual technological revolutions in artificial intelligence and biotechnology.
First, AI has been advancing rapidly over the past decade, beginning with the 2012 ImageNet breakthrough, during which many important technological revolutions have occurred. Since then, we've seen reinforcement learning represented by AlphaGo; the rapid development of generative models in recent years, such as large-scale language models like GPT-3 and ChatGPT, and diffusion generative models like DALL-E 2 and Stable Diffusion; and significant progress in graph representation learning and geometric deep learning, most classically exemplified by the AlphaFold2 protein structure prediction model.
At the same time, data in biology is growing rapidly, and growing faster than Moore's Law. First, high-throughput gene synthesis, gene editing, and gene sequencing have given us access to massive amounts of sequence data, such as the protein sequence database UniProt. Additionally, high-throughput wet-lab platforms enable sequencing of AI-designed protein or antibody sequences to obtain experimental data on activity. This also includes structural analysis techniques represented by cryo-EM, which — especially combined with AI — can rapidly resolve protein structures and functions. Today the PDB (Protein Data Bank) contains hundreds of thousands of datasets, which was also a crucial reason for AlphaFold2's success.

What is the core idea behind the generative AI everyone is discussing? Essentially, it is trained on massive amounts of text, image, and code data from the internet to generate entirely new and realistic text, images, and code.
Taking ChatGPT as an example, every response it gives is freshly generated by AI. The training process mainly consists of three steps:
The first step is large-scale pre-training of language models, based on massive amounts of text and code data from the internet, enabling the model to understand text and code;
The second step is further optimizing the model with labeled data, such as providing human Q&A data for specific scenarios, enabling it to perform dialogue tasks;
The third step is having the model interact with humans, iteratively improving based on feedback — essentially a reinforcement learning process that makes the model increasingly intelligent.
Applying ChatGPT's core concepts to biomedicine, we can see: ChatGPT's pre-training requires massive amounts of data, and today we already possess extensive protein sequence, antibody sequence, and structural data, sufficient to pre-train a protein generative model; just as ChatGPT optimizes its model through interaction with humans, models in biomedicine can interact with wet-lab platforms to obtain feedback — for example, synthesizing, expressing, purifying, and testing generated protein sequences on wet-lab platforms to obtain activity and functional data, which then helps further optimize the model.
Therefore, an extremely exciting opportunity lies before us: generative AI has enormous potential in drug discovery, particularly in protein design, and is fully capable of developing ChatGPT-like generative models to create and generate entirely new proteins and molecules, helping us find better drugs.
For example, when we want to design an antibody in the future, the process through a generative model might work like this: the user poses a query to ChatGPT — here, the query could be the antigen's sequence and structure; the AI model also provides an answer — an AI-generated antibody sequence; then through testing the sequence on a wet-lab platform, feedback is obtained and returned to the AI model, and after several rounds of interaction, we may find the molecule we want.

To date, BioGeometry has conducted some explorations around the application of generative AI in biomedicine, encompassing tasks from small-molecule 3D structure prediction to large-molecule protein design.
Application 1: Molecular 3D Conformation Prediction
For small-molecule 3D structure prediction, we primarily model this using diffusion generative models (GeoDiff).
The recently popular AI art tools are powered by diffusion generative models, which work by learning the information decay caused by noise, then using the learned patterns to generate images.
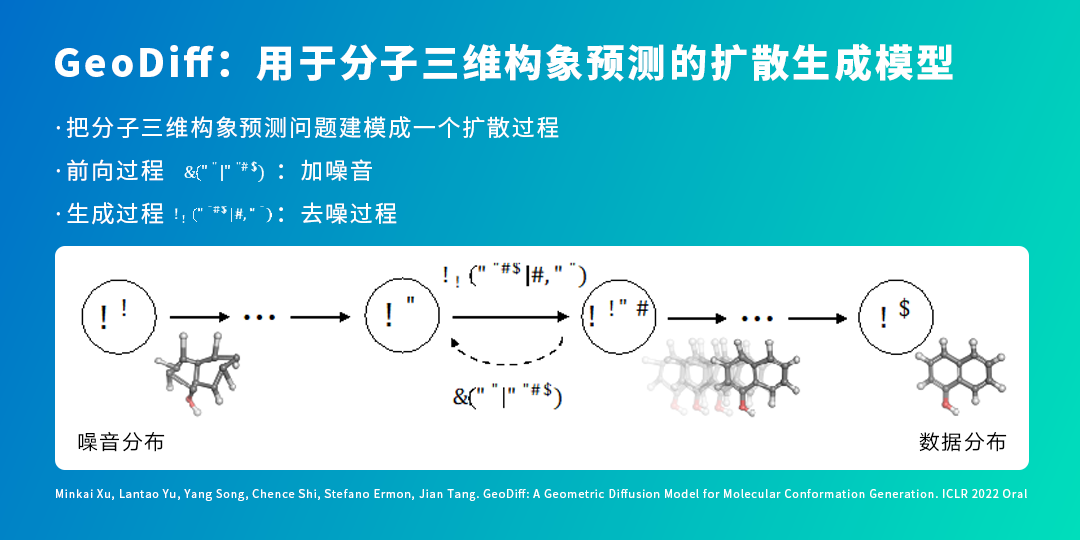
We also model the molecular 3D conformation prediction problem as a diffusion process, including a forward process — adding noise, performing multi-step random perturbations on atomic coordinates in the molecular graph structure, degrading the molecular conformation into a random process; then through a generative process, i.e., denoising, ultimately obtaining a stable molecular structure.
The most important component of this model is the denoising network, whose principle is that the neural network learns the forces acting on each atom (Force Field), thereby adjusting atomic positions and gradually converging to a stable structure. Since forces on atoms are equivariant to rotation and translation — meaning if the input structure is rotated, the forces acting on the atoms must also rotate correspondingly — our neural network is specially designed to ensure that the generation process is equivariant to rotation and translation.
The figure below shows how a molecule, starting from random initialization of each atomic position, finally converges to a relatively stable structure.
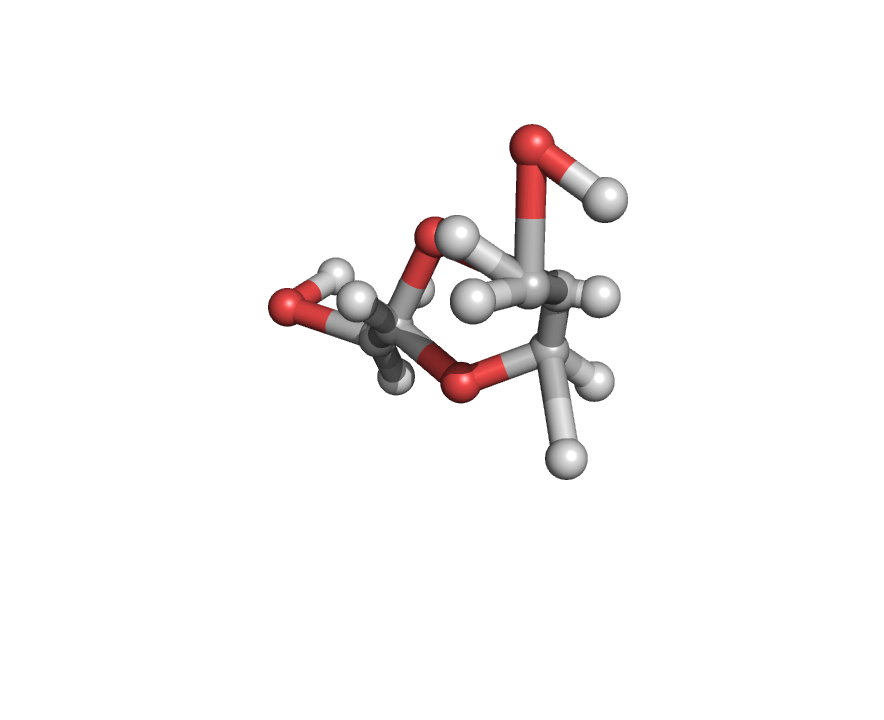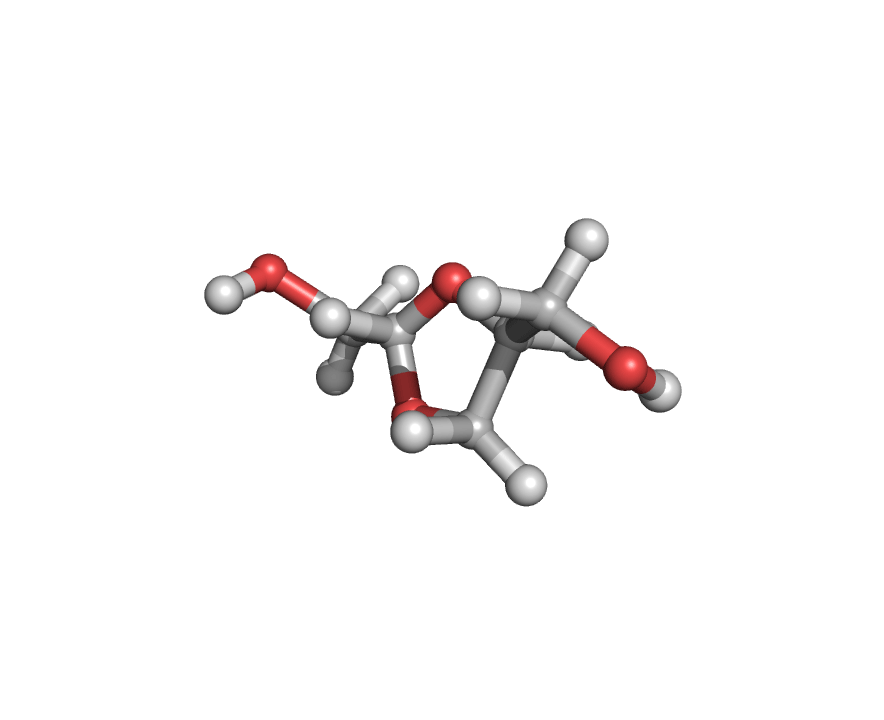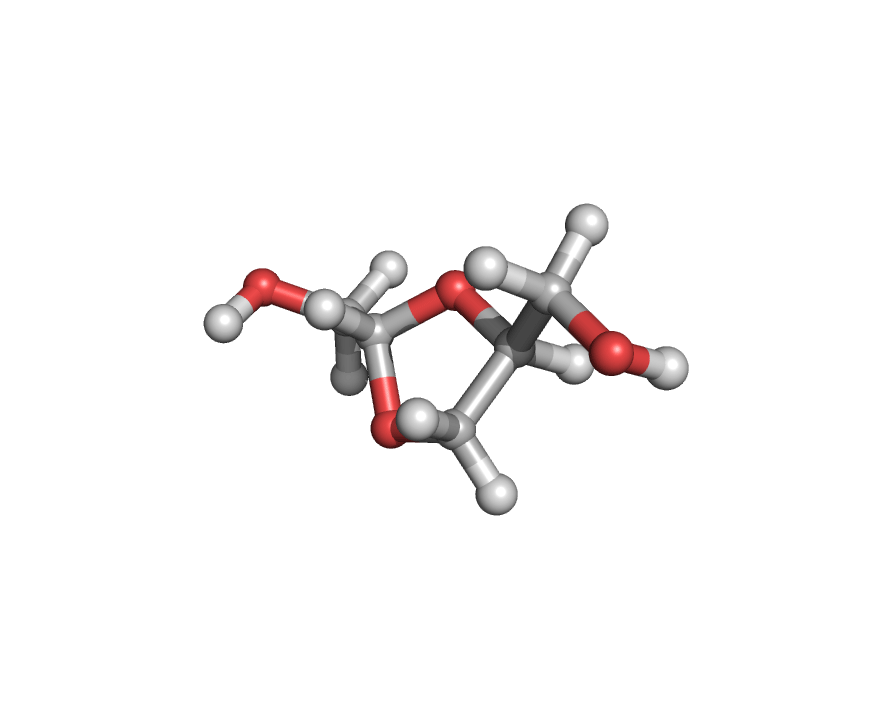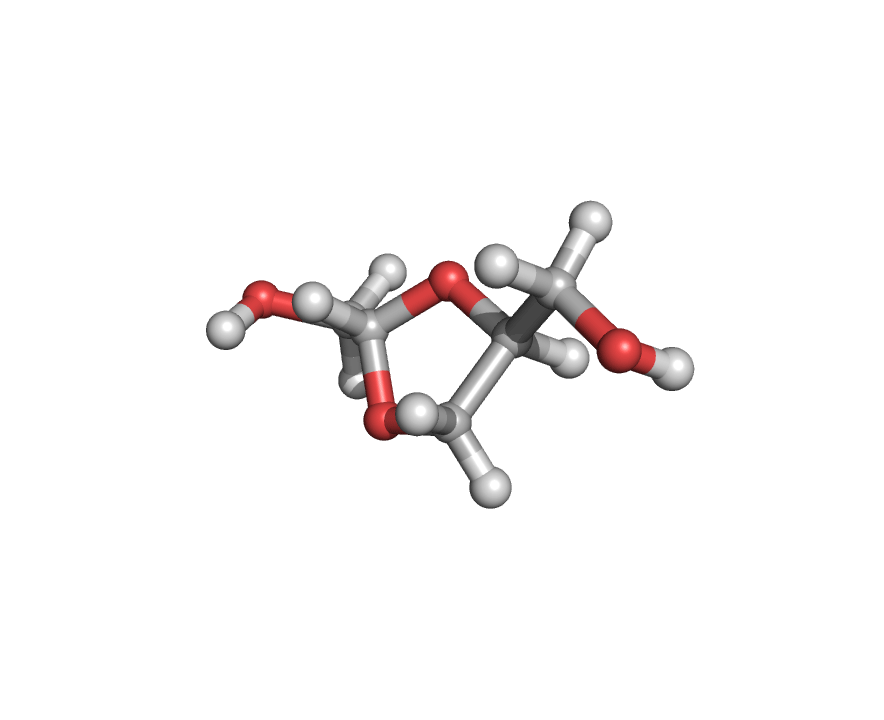
Application 2: Protein-Ligand Complex Structure Prediction
Beyond predicting molecular 3D conformations, we further extended to complex structure prediction, such as protein-ligand structures. By inputting protein 3D structures and ligand molecular graph structures, we predict the complex structure.
We similarly developed a diffusion generative model with an encoder-decoder framework. The encoder first encodes the molecular graph, protein, and their interactions, obtaining their geometric constraints; the decoder's core is also a denoising network, which through multi-round optimization, infers and obtains a stable complex structure.

In the example below, the green region is the protein 3D structure, and pink shows the predicted ligand structural changes from the model. The initial structure is similarly random, and through multi-round optimization, it finally converges to the ground truth position (gray). Throughout the process, denoising is performed at each step, learning the force field, and adjusting atomic positions through the force field. Currently, the model's prediction results show significant accuracy improvements compared to traditional methods.
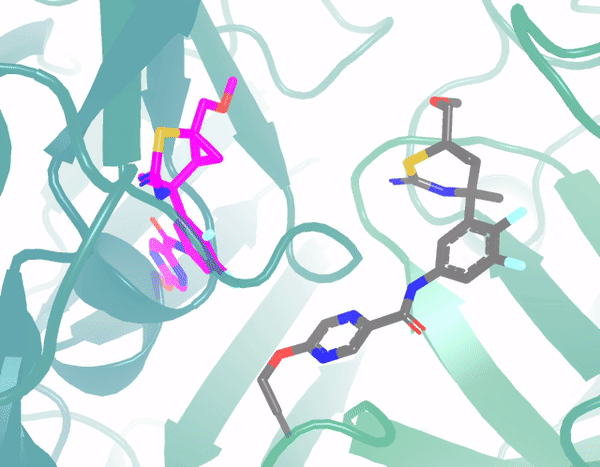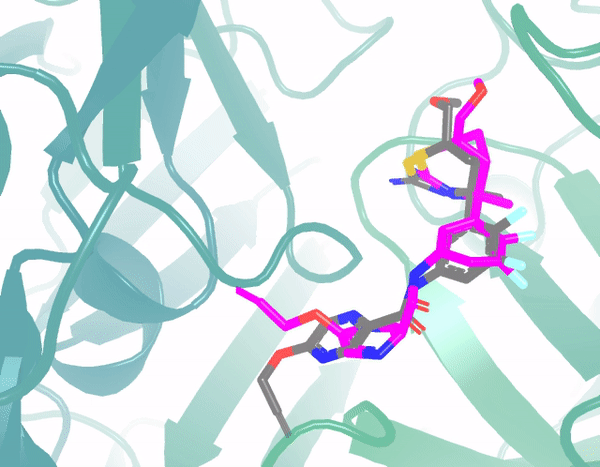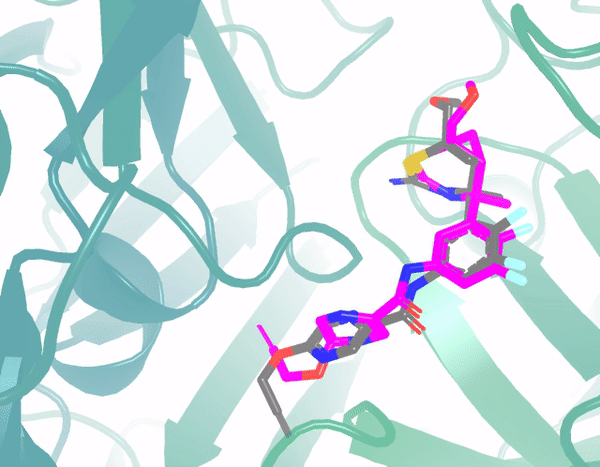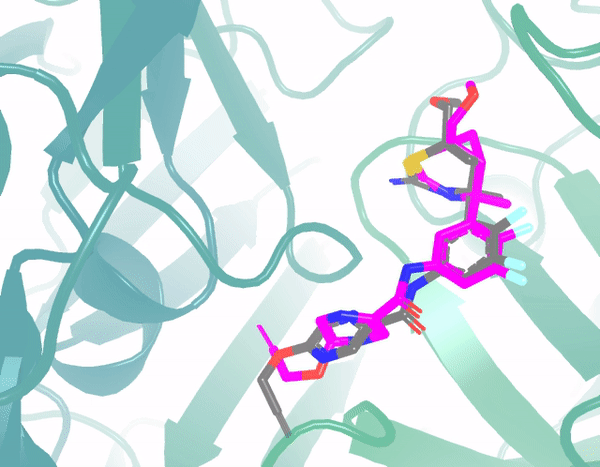
Application 3: Large-Molecule Protein Design
Recently, BioGeometry has been working on large-molecule protein design based on diffusion generative models, targeting de novo protein design — that is, designing entirely new protein structures and sequences.
In de novo protein design, the RFdiffusion algorithm released by the University of Washington's David Baker Group in 2022 is relatively representative. It is trained on PDB structural data, then follows a two-stage algorithm — first generating new structures, then completing protein sequence design through a sequence design model based on the structure. Currently, this algorithm has performed sequence design on many targets, showing significant improvement in success rates compared to traditional physics-based algorithms.
In 2022, BioGeometry introduced a new diffusion generative model (ProtSeed) that simultaneously generates new protein structures and sequences.
First, protein structures, sequences, and other context information (such as target structures, secondary structures) are input, and the model outputs updated structure, sequence, and other information. Similarly, through continuous optimization by the denoising network, a relatively ideal protein structure and sequence are ultimately found.
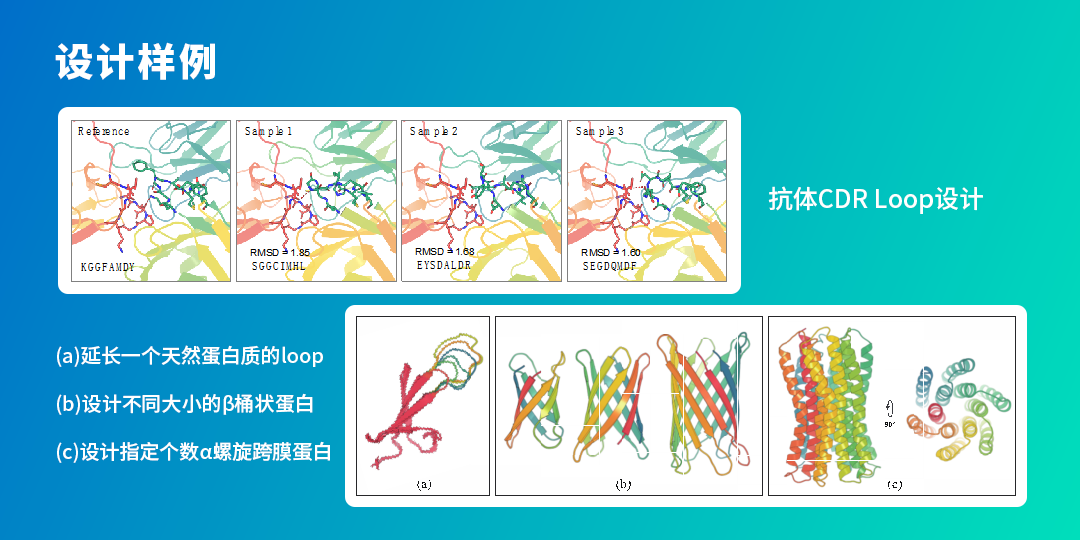
Based on this model, we already have some design examples. For example, in antibody CDR loop design, the CDR loop structures and sequences generated by the model show very small differences from antibodies that actually exist in nature, indicating that the model can basically reconstruct naturally occurring antibodies.
Through the model, we have also attempted to design β-barrel proteins of different sizes and α-helix transmembrane proteins with specified numbers.
Application 4: Antibody Optimization and Design
We have also applied generative models to antibody optimization. Many antibodies are discovered experimentally, but some have insufficient affinity and require mutations to optimize affinity.
We similarly built a model. First, based on large amounts of protein sequences and protein complex structures, the generative model is pre-trained to understand how proteins bind to each other; then through supervised fine-tuning, given protein-protein mutation datasets, an antibody optimization model is obtained, enabling AI to design new antibody sequences; then through wet-lab feedback on antibody affinity data, returned to the AI model for a new round of antibody sequence design. After multiple rounds, an ideal antibody sequence can be found.
Previously, we collaborated with Fudan University to optimize the CR3022 COVID antibody. Through two rounds of iteration with the AI model, we obtained a relatively ideal new antibody molecule. This molecule has three mutations, with significantly improved affinity.
Based on generative models and geometric deep learning models, BioGeometry has currently built a complete platform for de novo antibody design and optimization. Given antigen sequences (or structures) and epitopes, without needing to provide any data, the platform can design large numbers of high-quality antibody sequences, and further utilize a self-developed high-throughput antibody wet-lab verification platform for interactive iteration. Currently, BioGeometry has established antibody discovery collaborations with multiple biopharmaceutical companies on various targets.
In the future, we particularly look forward to having a larger community and platform to jointly promote AI for Science or AI development in biomedicine. Therefore, BioGeometry, together with NVIDIA, Intel, IBM, and other companies, jointly released TorchProtein, the first open-source machine learning platform for large-molecule drug discovery. This platform open-sources a general framework for deep learning modeling of large molecules, the first pre-trained large model based on protein 3D geometric structures, and a benchmark dataset specifically designed to evaluate deep learning's performance in protein modeling.

We firmly believe that generative models will not only benefit biomedicine in the future, but will also have important impacts across agriculture, food, materials, energy, environment, and many other fields.




