How DeepSeek Is Transforming AI Application Development: 34 Insights from 7 Practitioners | Ronghui --- The past two months have been a "DeepSeek moment" for China's AI industry. From the open-source release of DeepSeek-R1 to the subsequent frenzy of adoption across the ecosystem, the model has become a focal point of discussion among developers, product managers, and investors alike. But beyond the hype, how is DeepSeek actually changing the way AI applications are built? What new possibilities does it unlock, and what limitations remain? We spoke with seven practitioners who have been working hands-on with DeepSeek across different domains — from consumer apps and enterprise software to creative tools and infrastructure. Below are 34 of their most salient observations, organized by theme. --- ## On Model Capabilities and Trade-offs 1. **"DeepSeek-R1's reasoning ability is genuinely step-function better on certain tasks."** One founder building legal AI noted that R1 outperformed GPT-4o on complex contract analysis where multi-step logical deduction was required, with error rates dropping roughly 30%. 2. **But that reasoning comes with latency costs.** Several developers emphasized that R1's chain-of-thought output makes it unsuitable for real-time applications. "You can't use it

From consumer-facing apps to vertical domains like travel, finance, and healthcare, and on to AI agents.
"To this day, we are still living through the aftershocks of the DeepSeek tsunami." From the release of the 671B-parameter DeepSeek-V3 model on December 26 last year, to the January 20 open-sourcing of DeepSeek-R1 — a reasoning model with remarkable performance, efficiency, and cost advantages — through the market chain reactions during Chinese New Year and the subsequent global acceleration of open source, the shockwaves from DeepSeek continue to spread.
Beyond tracking DeepSeek's technical innovations and value restructuring, we also want to understand: What tangible benefits do models like DeepSeek-V3 and R1 bring to entrepreneurs building AI applications and vertical scenarios? What real-world lessons and reflections come from building industry applications on top of open-source models?
Recently, Ronghui (榕汇) invited founders from fields including AI interactive content platforms, AI+travel, AI+financial research, AI+healthcare, and AI coding to an online discussion.

Below, we've excerpted some of their thinking on topics founders care about most: model capabilities, costs, and commercial opportunities in vertical scenarios.

DeepSeek's Core Technical Innovations
Yanzheng, Solutions Architect, Amazon Web Services AI Application Lab
At the end of December 2024, DeepSeek released its backbone model DeepSeek-V3. With 671B parameters, V3's performance approached top-tier closed-source models like GPT-4. The model had numerous innovations, with five most frequently discussed:
01. Mixture-of-Experts architecture (DeepSeekMoE): Despite total parameters of 671B, only 37B are activated per token, dramatically improving computational efficiency. 02. Multi-head Latent Attention (MLA): Reduces computation through low-rank compression, lowering memory and GPU usage while cutting inference latency. 03. Multi-Token Prediction (MTP): Predicts multiple tokens simultaneously, boosting training efficiency by 1.8x and reducing generation time. 04. FP8 mixed-precision training: Combines FP8 low-precision computation with high-precision parameter storage, reducing GPU memory usage while maintaining training stability and significantly cutting costs. 05. Dual pipeline: An innovative bidirectional pipeline parallelism algorithm allowing forward and backward passes to run simultaneously, substantially reducing GPU idle time.
Subsequently, DeepSeek applied pure reinforcement learning training on top of V3, enabling the model to develop reasoning capabilities and producing R1-zero. R1 itself was built on DeepSeek-V3, combining two rounds of supervised fine-tuning with reinforcement learning training to create this powerful reasoning model.
DeepSeek Represents True Paradigm Innovation
Liu Xinhua, Investment Partner, Gaorong Ventures
DeepSeek represents true paradigm innovation because it brings six inflection points in value.
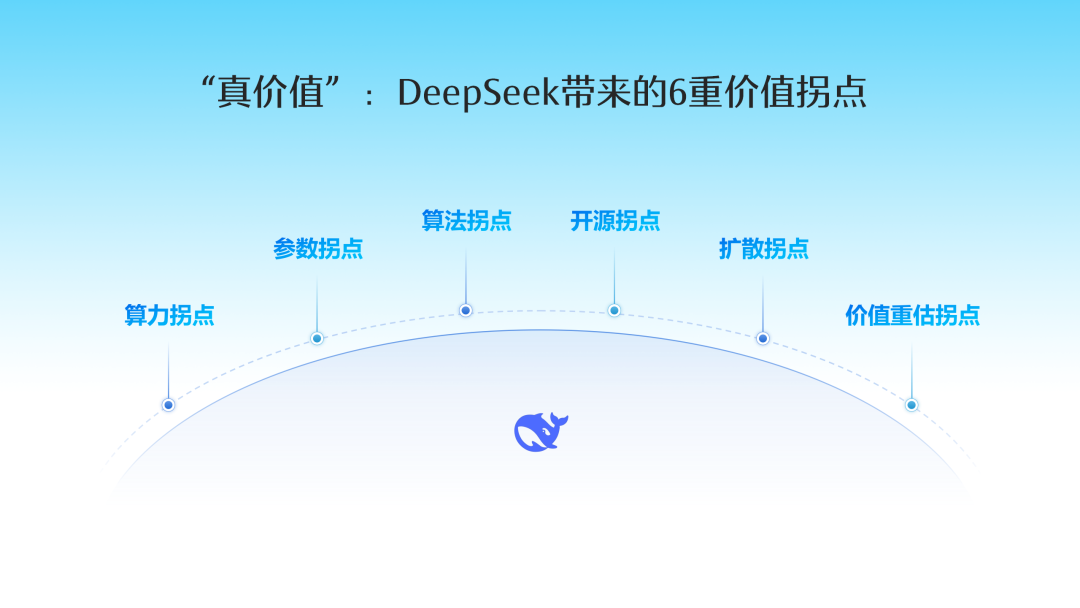
01. Compute inflection: Through extreme innovation in algorithms, model architecture, and training strategies, DeepSeek significantly reduced reliance on high-end hardware, proving that "spending massively on compute is the only path to top-tier models" is not the only solution. Compute has long been a critical battleground in global AI competition. DeepSeek's "innovation in the cracks" broke through compute bottlenecks, creating opportunities for domestic chips, ASICs, and others.
02. Parameter inflection: DeepSeek used model distillation to extract and transfer reasoning patterns from powerful "teacher" models to smaller "student" models. For example, smaller distilled models from R1 (1.5B, 7B, 14B, 32B, 70B) perform excellently on reasoning tasks while preserving the essence. This means reasoning models can now be deployed in edge scenarios with limited compute — AI phones, AI PCs, humanoid robots, IoT, and more.
03. Algorithm inflection: DeepSeek innovated across multiple algorithmic dimensions: mixture-of-experts architecture, R1-zero's pure reinforcement learning strategy (GRPO) for directly optimizing reasoning capabilities, multi-token prediction, and more. These significantly improved model performance and efficiency while reducing costs. I believe major global model companies will now embrace some of the new paradigms DeepSeek pioneered.
04. Open source inflection: DeepSeek adopted the MIT license, the most permissive open-source license, allowing commercial use. More importantly, while open-source models historically lagged behind closed-source ones, DeepSeek's models matched or even surpassed top closed-source models in performance. In late February, DeepSeek's open-source week further revealed numerous engineering innovations. DeepSeek has led "the victory of open source" and prompted other major model companies to reconsider their open-source strategies.
05. Application diffusion inflection: In July 2024, we predicted that over the next 18 months, as hardware costs declined and model architectures and algorithms improved, AI product development costs could drop 100x. Today, the cost reductions triggered by DeepSeek may exceed even that forecast, truly ushering in an explosion at the application layer. Looking further, the Jevons paradox has been much discussed recently — when efficiency improves and costs fall, adoption accelerates, driving overall demand expansion. Future innovation diffusion won't be limited to internet application layers but will penetrate全产业链各种场景 [the full industrial chain and various scenarios], including chips, cloud, robotics, autonomous driving, and beyond.
06. Value reassessment inflection: DeepSeek not only promotes revaluation of Chinese assets but also demonstrates "China's innovation and inclusiveness in technology development," reflecting the innovative vitality of private enterprise and entrepreneurs.
Principles for AI Application Development
Yanzheng, Solutions Architect, Amazon Web Services AI Application Lab
01. The AWS AI Application Lab focuses on cutting-edge model research and AI project development and delivery. Based on different scenarios, the lab uses various models for adaptation and combination to ultimately serve B2B customers. A single workflow might include foundation models, fine-tuned models, or industry-specific models.
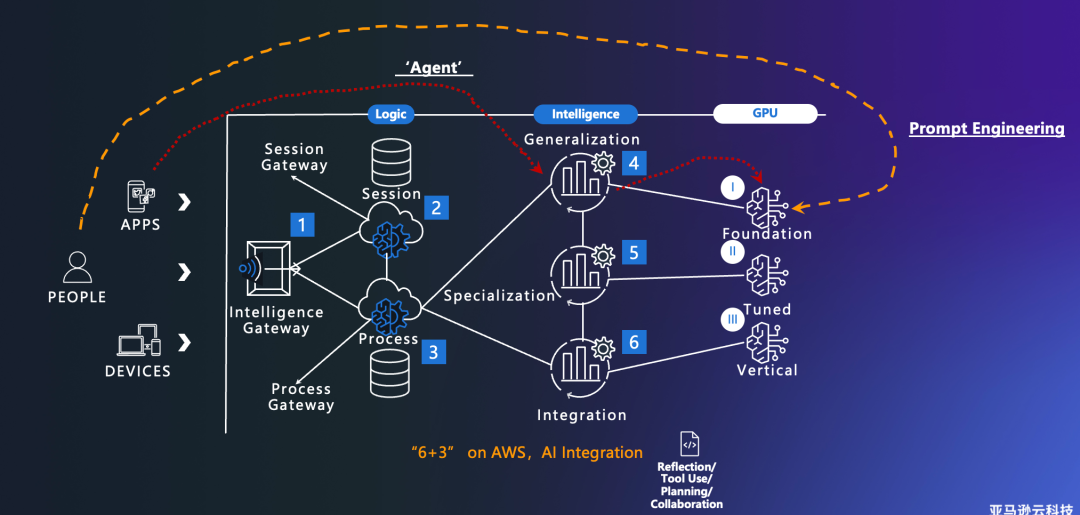
Recently, the lab has actively used DeepSeek models to build concrete落地应用方案 [landing application solutions] for clients. For example, using a DeepSeek-R1 Distill 70B-based knowledge base, it achieved deep understanding, analytical reasoning, and source tracing for user queries — outputs that not only provide answers but include detailed step-by-step explanations.
02. At the same time, an important principle and consideration is: DeepSeek models are powerful, but that doesn't mean DeepSeek can solve everything. You need to let specialized models handle specialized tasks, then combine those specialized models to complete complex jobs.
For example, the lab recently combined DeepSeek-R1 with a task-classification detection fine-tuned model to provide potato leaf disease detection services for agricultural clients, along with treatment recommendations. The overall technical approach: first, a fine-tuned CV model detects potato leaves; then the detection results are passed to R1, which leverages its reasoning capabilities to provide guidance to farmers, including disease causes and prevention advice.

AI Interactive Content Platform
Shen Qiajin, Founder & CEO, Xiangfaliu (想法流)
01. Xiangfaliu's core product, Dream Dimension (造梦次元), is a multimodal AI-driven interactive content platform. Behind the platform is a complete workflow system connected to multiple models — including large language models, image generation models, music generation models, and engineering modules — allowing creators to build engaging interactive content and even gamified experiences based on model capabilities.

02. DeepSeek-V2 caught our team's attention from its release. We realized then that MoE architecture would become increasingly important, enabling application developers to call models with large total parameters but smaller activated parameters — balancing model cost, latency, and intelligence, ultimately benefiting application developers with lower-cost access to large-parameter models.
Previously, a major problem for AI applications in content was this: small-parameter models couldn't solve content generalization issues, leading to poor instruction-following that could break plotlines and character settings; large-parameter models, besides high costs, generated content too slowly. MoE architecture solved this well. After we adopted MoE models (initially Doubao's large model), we found it still performed well when generalizing to fantasy, historical, and other content types.
03. We also realized cache hit rate is critically important. Per million input tokens, the price difference between cache hits and misses is substantial. Dream Dimension's product characteristic is users are constantly using the model, with average daily active interaction time exceeding 100 minutes. In our scenario, input tokens far exceed output tokens. If 90% of our inputs hit cache, costs drop dramatically.
04. The team has consistently tracked model progress, especially improvements in reasoning capabilities. Dream Dimension has many gameplay mechanics — for example, numerical/scoring game mechanics or murder-mystery deduction — that require certain reasoning capabilities. We originally implemented these through workflow approaches; with R1's arrival, we knew the low-cost, strong-reasoning, sufficiently-fast model we'd been pursuing had arrived.
05. Going forward, we hope AI interactive content platforms evolve from "fun" to "useful" — for instance, integrating life-scenario capabilities like time/location/weather APIs could enable more interesting experiences. For example, if I'm on a business trip to Beijing, the AI might tell me it's minus 6 degrees there and ask if I brought a down jacket.
AI-Driven Travel Platform
Li Shaohua, Founder & CEO, Shilü Technology (视旅科技)
01. Shilü Technology aims to build an AI-driven next-generation travel platform. Over the past few years, we've seen several opportunities. First, the natural interaction revolution brought by large language models will create massive transformation opportunities for travel scenarios. Second, multimodal large model applications may enable fundamentally different product presentation compared to today's mainstream OTA platforms. Third, industry vertical models and vectorized digital supply systems could change the long-standing fragmentation of travel industry supply.
02. In May 2023, Shilü Technology released VtripGPT, China's first travel-domain large model and the first in the travel industry to pass regulatory review and filing by the Cyberspace Administration and other authorities. After DeepSeek-R1's open-source release, we immediately deployed it privately and used distillation to transfer R1's reasoning capabilities to our travel large model. From a business growth perspective, reasoning models have significantly boosted our operations.
03. In 2023, when we launched our first destination based on our self-developed industry model, 4-5 senior operations experts spent roughly two months on pre-training and supervised feedback before the model's output reached industry-usable standards. After running for over a year, the model basically allowed 1-2 business staff to add a new destination in about a month. After deploying R1, we found we could launch a destination in roughly two days without business expert feedback (adding an expert correction module at the model output stage with some general rules to constrain outputs).
**04. R1's reasoning and long chain-of-thought (CoT) capabilities significantly boost itinerary planning, customized solutions with specific requirements, and dynamic product bundling in the travel industry. For example, international flights with 2-3 layovers for overseas business trips currently rely almost entirely on human effort and require extensive platform data accumulation. Going forward, large models' deep reasoning capabilities could fully address such complex scenarios.
05. Further, if open-source high-performance models enable every ordinary user to complete high-end private customization without travel expert involvement, it would massively restructure the travel experience and help vertical startups find commercial breakthroughs faster.
AI Intelligent Investment Research
Li Yu, Co-founder & CTO, Shangjian Technology (熵简科技)
01. Shangjian Technology's AlphaEngine product is an AI investment research tool that uses cutting-edge large model technology to help professional investors improve decision efficiency and win rates in research and investment decisions. Two years ago, we trained our own industry model FinGPT; after R1's release, we distilled FinGPT-Deep with reasoning capabilities, giving the model logical reasoning, causal analysis, and multi-step decision-making abilities, deployed on AlphaEngine. Leveraging deep reasoning, AlphaEngine achieved three core functional upgrades: 1) multi-step reasoning Q&A, 2) precise source tracing, and 3) integrated analyst thinking. Since launch, user Q&A interaction volume has increased approximately 3x.
02. Compared to previous models, R1's reasoning breadth is roughly equivalent, but reasoning depth goes at least two steps deeper. For example, asking "how to analyze a robotics company's trajectory" — previous large models would examine company fundamentals and competitive landscape; with R1, the model reasons independently that analyzing company trajectory requires studying upstream and downstream industry chain, then further deducing that downstream might involve sensors, bearings.
03. A fundamental variable DeepSeek brings is enabling vertical SaaS companies like ours to obtain capabilities basically on par with o1 at very low cost. Only with dramatically reduced costs can we let users experience this at scale and truly boost productivity.
04. Building industry applications on large models requires three elements. First, a sufficiently strong base model. Second, sufficiently comprehensive, timely databases accumulated in the vertical industry — Shangjian currently basically achieves full coverage of publicly available A-share and US/Hong Kong stock data. Third, supporting small models plus a complete Multi-Agent orchestration system. On small models, Shangjian trained FinBERT, a vectorization model improving data recall rates; FinAudio, a professional voice large model for investment research scenarios supporting accurate transcription of research meeting audio to text; and a text large model for PDF parsing.
05. On orchestration, deep integration with specific industry scenarios is needed to build a Multi-Agent framework involving substantial engineering work and specific rules. For example, Shangjian currently has three Agents cooperating for investment research Q&A: an introspection Agent, a reasoning Agent, and a response Agent.
AI Healthcare Assistant
Zeng Boyi, Co-founder & CTO, Chunyuyisheng (春雨医生)
01. Healthcare has two major problems — 1) insufficient medical resources, and 2) uneven distribution of medical supply. Chunyuyisheng initially focused on solving supply imbalance by connecting supply and demand through its platform. As large models matured, in April 2023 we launched our AI health assistant product Chunyuhuiwen (春雨慧问) and began addressing insufficient medical resources.

02. The current focus in healthcare is insufficient medical resources, especially the shortage of authoritative, high-quality doctors. To address this core contradiction, we plan a two-step approach: first serving as a doctor Copilot for assisted pre-consultation, then gradually transitioning toward AI doctors. We know that the initial information gathering phase in doctor consultations is extremely time-consuming, reflecting the diagnostic thinking and process behind it. Our doctor Copilot aims to complete this pre-consultation process through AI, allowing doctors to focus on providing diagnoses and treatment plans — saving doctors time and improving efficiency.
03. Chunyuhuiwen has integrated R1. Compared to previous base models, R1 offers two major improvements. First, where we previously needed multiple prompts to make the model implement the consultation process, we can now quickly achieve multi-step chain-of-thought tasks. Second, after integrating R1, we found stronger model generalization capabilities. Previously, large models might respond adequately to single-department questions; but once expanded to general practice, facing different departments and diseases, the difficulty of analysis and response increased dramatically. Based on R1, when generalizing to consultation and intelligent diagnosis tasks across different departments, results improve noticeably.
AI Coding
Li Yafei, Founder & CEO, ClackyAI
01. The evolution of AI coding: earliest, relying solely on programmers — "writing code character by character"; after ChatGPT appeared in 2022, coding heated up first, with GitHub Copilot enabling "writing code line by line"; in 2024, AI coding tools represented by Cursor began supporting "writing code block by block", with AI coding leading AI application commercialization due to its strong closed-loop nature; today we're pushing toward "writing code by slice" or by feature, believing this will help programmers achieve massive efficiency gains; at L4, we believe AI autonomous coding will become the ultimate evolutionary direction.
02. ClackyAI positions as an L3-level Agent AI CDE, implementing issue-to-PR workflow in the cloud, targeting serious developers, with an interaction time machine mechanism, full repository recognition and retrieval, and multi-task processing systems. Technically, we've fully self-developed a multi-task Agent architecture. DeepSeek has been enormously helpful — our base model's reasoning module currently deploys R1.
03. On code generation specifically, DeepSeek models currently still have some gap compared to Claude 3.5, Claude 3.7, and others; but programming isn't just programming itself — we also care about reasoning capabilities, such as problem understanding, task planning, and path design. We look forward to DeepSeek's next-generation model making progress on coding, at which point we could potentially fully switch our main model. For now, we balance using SOTA models and DeepSeek open-source models.
AI Agent
Liu Xinhua, Investment Partner, Gaorong Ventures
01. The rapid development of reasoning models makes the Agent direction increasingly valuable. I believe we'll see breakthrough progress in Agents this year, from general Agent frameworks and infrastructure to scenario-specific Agents — a hundred flowers blooming. In ToC, AI search will fully evolve toward Agentization. In fact, DeepSeek's C-end application itself is an Agent: an excellent base model plus a workflow (like web search) enabling continuous self-improvement.
02. In ToB, including horizontal and vertical scenarios. Horizontal scenarios — programming, customer service, productivity, marketing, sales, recruiting — all have opportunities for Agent deployment. For example, customer service Agents can not only converse naturally with users but further integrate with internal workflows, automatically routing customer issues to business departments and circling back to customers after resolution. Vertical scenarios like legal and healthcare will also see prioritized Agent applications.
......
"DeepSeek's explosive success proves one truth — greatness cannot be planned. In our entrepreneurial exploration, we must cherish this contingency and uniqueness, maintaining openness and curiosity. When you've accumulated enough stepping stones, greatness may find you unexpectedly."
Going forward, we also look forward to accompanying mission-driven, innovative entrepreneurs. "We believe 2025 will see more Chinese AI application innovations bloom."




