Galixir's Chengtao Li: Finding the "Key" to Curing Disease with AI in the Universe of Compounds | Rong Talk --- In the vast "universe" of chemical compounds, finding the molecule that can precisely target a disease is like searching for a needle in a haystack — except the haystack contains more stars than there are in the Milky Way. This is where Galixir comes in. Founded in 2019, Galixir is an AI-driven drug discovery company that uses artificial intelligence to navigate the astronomical complexity of molecular space. At its helm is Chengtao Li, a Tsinghua University PhD who spent years at MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) before returning to China to build what he calls "a new kind of pharmaceutical R&D engine." "The traditional drug discovery process is incredibly inefficient," Li tells us in a wide-ranging conversation at the company's Beijing headquarters. "You're talking about 10 to 15 years and $2-3 billion to bring a single drug to market. And the failure rate is brutal. We think AI can fundamentally change that equation." Galixir's approach centers on what Li describes as "generative chemistry" — using deep learning models to design novel molecules from scratch, rather than merely screening existing compound libraries

How artificial intelligence technology is accelerating drug discovery and development.
Drug discovery has long been plagued by three major pain points: high investment, long timelines, and high risk. In recent years, as the generic drug industry faces consolidation, AI-powered drug discovery has attracted significant attention.
Founded in 2019, Galixir is dedicated to advancing drug discovery through world-leading artificial intelligence technology. Through its AI drug discovery platform, the company helps pharmaceutical scientists dramatically reduce both the time and cost of drug development.
The number of potentially druggable compounds in the world is roughly on the order of 10^60. For this reason, Galixir likens the process of developing new drugs to finding a "key" that can unlock a cure within this vast compound universe — and AI technology can help us discover these keys faster and more effectively.
Gaorong Ventures led Galixir's angel round in 2019 and has continued to invest in subsequent rounds. To date, Galixir has achieved multiple major technical breakthroughs, with its self-developed models and algorithms setting new benchmarks across various stages of the process, significantly shortening drug development timelines and costs to directly address the core challenges of new drug R&D.
This article is adapted from a presentation by Dr. Chengtai Li, founder and CEO of Galixir, at the "Oxford-Cambridge Doctoral Elite Tour · Gaorong Ventures Edition." Dr. Li shared his insights on pain points in the drug discovery industry, AI's role in empowering pharmaceutical R&D, and cross-disciplinary scientific research with nearly 20 doctoral and postdoctoral researchers from Oxford and Cambridge.

The following is Dr. Chengtai Li's presentation (edited for clarity):
I graduated from Tsinghua University's Yao Class for my undergraduate studies, then went to MIT for my PhD, where I focused on computer science and artificial intelligence. Later, I began thinking about AI applications in biomedicine, spending considerable time studying the drug discovery process to identify where AI could add value.
Galixir was founded in 2019, dedicated to advancing drug discovery through AI technology. The name GALIXIR combines two English words — Galaxy and Elixir — reflecting our mission to search for new medicines that can cure diseases throughout the compound universe.
Today's presentation covers three main areas: first, the pain points in today's drug discovery industry; second, how AI-driven drug design differs from decades-old computer-aided drug design (CADD); and third, an introduction to Galixir's AI-powered drug discovery platform, Pyxir™.
The Three Pain Points of Traditional Drug Discovery: Driving Returns Down Year by Year
Why are we doing this? We need to recognize that many diseases worldwide still have no cure. Currently, over 60% of diseases lack effective drugs. Additionally, 50-70% of patients don't respond to blockbuster drugs. For example, some drugs can treat late-stage cancer but only work for 30% of patients. While this represents enormous progress compared to the past, we must consider what happens to the remaining 70%.
Therefore, demand in the drug discovery market is robust, and China's pharmaceutical R&D market has been on an upward trajectory. In recent years, China's drug R&D investment growth has far outpaced that of the US, with the market expected to exceed half the US market within three years. So while China's drug discovery market may not have started from a high base, its ceiling is extremely high — it has the potential to become the world's largest drug discovery market.
Despite this enormous potential, drug discovery faces many challenges. The entire new drug R&D process can be divided into two major parts: preclinical drug discovery and clinical trials. This includes target-based molecular design, molecular screening, molecular optimization, synthesis, metabolism studies, and testing for properties like solubility and toxicity — all completed preclinically. These experiments are conducted at the cellular or small animal level; once cleared, a drug can enter clinical trials. Clinical trials are divided into Phase I, II, and III, with greater focus on drug efficacy. The failure rate throughout this process is extremely high: you might start with millions of molecules, narrow down to dozens in preclinical research, and end with just one that makes it through clinical trials. The US FDA has approved only about 1,600 drugs in its entire history, and many diseases still lack effective treatments.
Traditional new drug R&D has three major pain points that have driven returns down year by year. The first is high investment. There's a peculiar phenomenon in drug discovery. We all know Moore's Law — as time progresses and technology advances, the cost of achieving the same capability gradually decreases. But in drug discovery, costs trend upward, following what we call Eroom's Law (Moore's Law spelled backwards): costs roughly double every ten years. Today, developing a single new drug averages $2.6 billion.
The second pain point is long timelines. Preclinical research currently averages 4-7 years, while clinical trials take 5-8 years, totaling approximately 9-15 years.
The third pain point is very high risk, with only a 10% success rate in the clinical stage. Together, these three pain points result in very low returns.
In other words, we need to invest enormous human and material resources, spending massive amounts of time and money to develop a single drug, but the returns are disproportionately low. In 2010, ROI for new drug R&D was around 10%; by 2019, it had fallen to approximately 1.8%, declining year after year. In the 1970s, new drug R&D costs were still quite manageable.
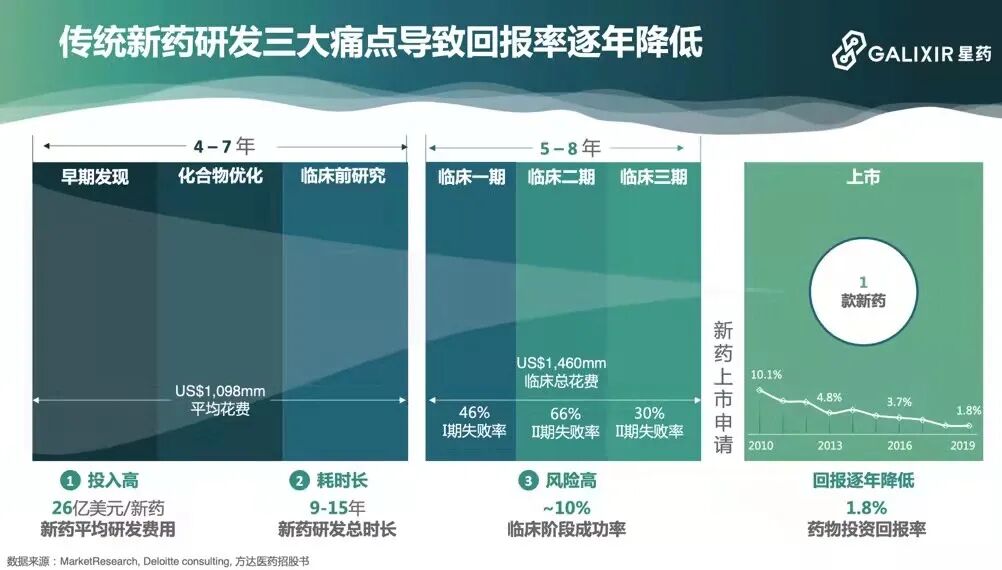
What can be done about this situation? This is what we hope to address with artificial intelligence, focusing primarily on the preclinical stage, including target identification, molecular design and optimization, and synthesis design.
What value can AI provide in these areas? We know that potentially druggable compounds number around 10^60, while humans have synthesized and tested roughly 10^10 molecules — a gap of 10^50. This is why we say we're searching for an elixir in the universe. The compound universe is as vast as the stars; what humanity has explored over centuries is merely a tiny fraction, and artificial intelligence may be the answer to reaching across that universe.
How AI Technology Drives New Drug Discovery
Let's first look at how drugs actually work. When we take small-molecule drugs after getting sick, they enter the body and bind to corresponding target proteins, regulating失控的 proteins back to normal states, thereby alleviating symptoms and treating disease.
Therefore, the logic of drug discovery is to find the target protein associated with a disease, then design a small molecule that can bind to it. We know that protein surfaces are uneven with many pockets; small molecules have special structures that can fit into these pockets, thereby regulating the protein's function. So discovering small molecules is like "finding keys," and binding to the target is like a key fitting a lock. You have a lock; you may design many keys that don't work, until one new key successfully enters the keyhole and turns the lock — that's the small molecule we're looking for.
How have we historically discovered these "keys"? Early discovery was largely accidental, like "Shennong tasting a hundred herbs." Later came clinical discoveries, including traditional Chinese medicine and antibiotics, which were historically found to be effective in certain patients before their broad-spectrum effects were understood.
In modern times, hit compound discovery is done through high-throughput screening. Humans have synthesized billions of molecules; drug discovery scientists test them one by one. If a small molecule is observed to bind with a protein, it can be further optimized.
Because "keys" discovered early on are usually imperfect, they require some "polishing" — what we call lead compound optimization. Starting with a relatively promising molecule, we alter various small functional groups to change drug properties, making the key and lock fit better.
How do we make these changes? There are some rules. For example, Lipinski's Rule of Five was once very popular: molecular weight below 500, no more than 5 hydrogen bond donors, etc. — compounds following these rules tend to have better drug-like properties. There are also other patterns, such as certain functional groups that may increase toxicity or cause molecular instability.
Once we've found the key and polished it, we test whether it's effective, creating a cycle.
In this process, computer-aided drug design can play a role. The patterns our scientists have discovered throughout history — which types of molecules might be toxic, which have poor solubility, or low bioavailability — these experiences and rules are fundamentally quantifiable. Through computer-aided design, we can help discover new patterns.
Furthermore, many drug-like molecules can be designed based on similarity to existing ones — another design method enabled by computer-aided design.
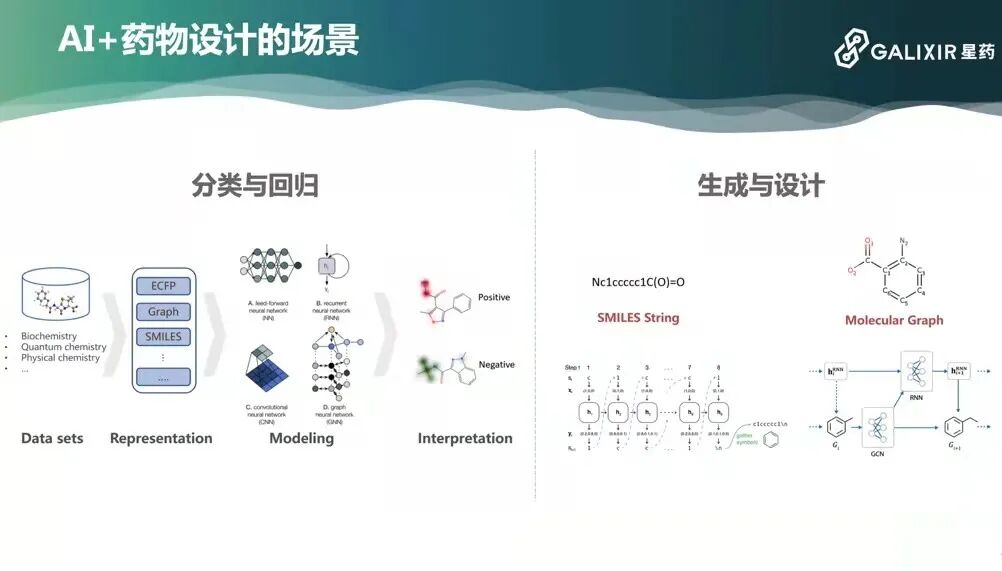
As AI technology advances, how can we leverage it for drug discovery? The core idea of machine learning is to induce and statistically analyze based on sample features. For example, to determine whether a watermelon is good or bad, there are many features: firm and smooth texture might indicate a good melon, while soft and sticky suggests a bad one. Such features help us make judgments.
Similarly, molecules have many features. The first question is how these features can be read by computers — that is, how to represent molecules in a computer. The second question is making predictions based on these representations — this is our ultimate goal.
There are many ways to represent molecules. For instance, a molecule can be a 3D ball-and-stick model; a 2D molecular graph transforms chemical molecules into mathematical graphs, allowing us to use deep learning methods for prediction; further abstraction yields a SMILES String, essentially a sequence, based on which we can also make predictions.
With molecular representations in place, we can make predictions through deep learning. Using fully connected neural networks, convolutional neural networks, recurrent neural networks, or graph neural networks, we can directly input molecular representations and output predictions. These predictions are extensive, including molecular toxicity, solubility, activity, and more — all critical features we care about in drug development.
Predictions mainly fall into two categories: classification and regression, and generation and design. Classification and regression include determining whether a molecule is active, or how active it is, etc. Generation and design involves designing molecules based on protein structures, such as molecular graphs (Li et al, J. Cheminfo).
These capabilities are closely tied to the drug discovery process, especially classification and regression, which fundamentally address how to determine whether a molecule is good or bad — the core capability. When we can identify which molecules are promising, we can proceed to synthesis and testing, significantly shortening drug development timelines.
In the drug discovery process, Galixir doesn't just use AI — we integrate computational chemistry and medicinal chemistry in collaboration. These three directions each have their strengths and weaknesses. AI is data-driven, using inductive reasoning. It performs well in areas with relatively abundant data, has strong knowledge transfer capabilities, and offers high efficiency and throughput, thus significantly boosting drug discovery efficiency.
Galixir's Pyxir™-Enabled Drug Discovery Process
So how does Galixir's drug discovery platform empower the entire R&D process? Our services cover the full process from target development to preclinical candidate drug discovery. From target identification, to lead compound generation, in-vitro/in-vivo experiments, pre-clinical development, through to IND filing — the point where a drug can enter clinical trials.
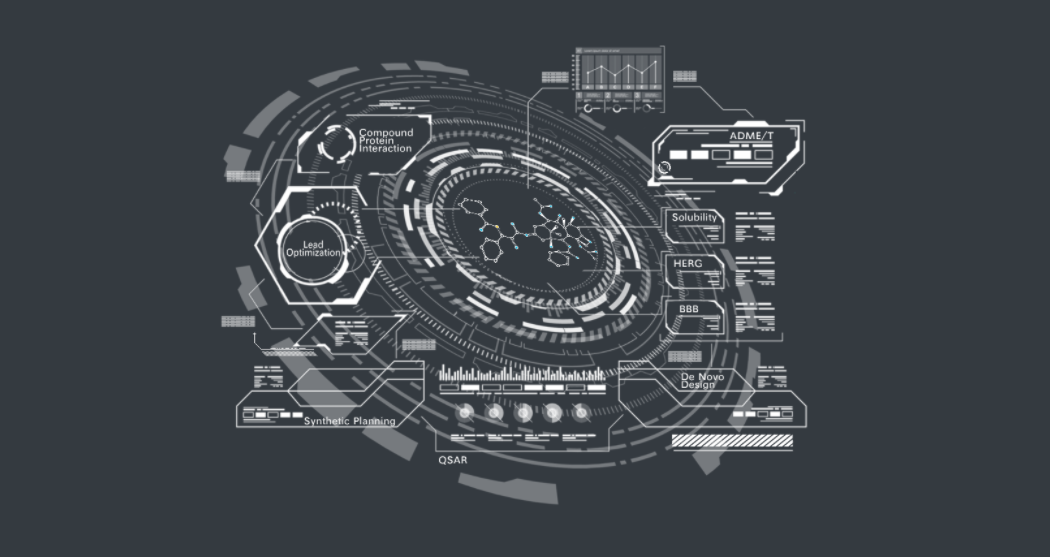
Galixir Pyxir™ Drug Discovery Platform
How do we achieve this? By leveraging AI technology for classification and regression, conducting virtual screening and directed optimization of molecules. Our learning methods include meta-learning, multi-task learning, transfer learning, active learning, unsupervised learning, and more.
We also use these technologies for property prediction, including the drug-likeness properties that everyone cares about. For example, drug toxicity — we know different diseases have different toxicity requirements. Cancer drugs tend to be quite toxic; to kill cancer cells, they bring many side effects. We're exploring how to achieve the same or better efficacy while reducing drug toxicity. There are also many drugs for neurological diseases, including Alzheimer's and Parkinson's, where whether a drug can cross the blood-brain barrier is a critical property.
After molecular property prediction, molecules can be handed to chemists for synthesis, followed by biological testing to see if various properties meet expectations. If they do, the process moves to the next round; if not, it goes back for revision. All data is accumulated within the entire AI closed loop. As data grows, our predictions become increasingly accurate.
In recent years, AI-powered drug discovery has made enormous impact not just in academia but in industry as well. Many multinational pharmaceutical companies are now researching how to collaborate with AI. For example, UK's BenevolentAI and ExScientia have done excellent work, and many US companies are also exploring this space. In China, we're pleased to see many outstanding companies emerging, and Galixir looks forward to exploring AI applications in drug discovery together with everyone.
On the implementation front, Galixir has established multiple efficient collaborative project teams, capable of simultaneously conducting multiple early-stage drug discovery projects. We've also signed strategic cooperation agreements with several renowned domestic and international universities and pharmaceutical companies, ensuring smooth advancement of upstream innovation and downstream validation in innovative drug discovery and development.
The COVID-19 outbreak in 2020 gave the public new awareness of the biomedicine field. This is a massive market, but one with enormous pain points, and artificial intelligence may be an excellent means of addressing them. In this process, how to build a cross-disciplinary team, find top talent with combined backgrounds in AI, chemistry, biology and other fields, and get them to work together effectively, as well as how to genuinely understand industry needs — these are challenges we must continuously tackle.

Xinhuazhang Announces Completion of A+ Round, Accelerating EDA 2.0 R&D Process

