Open-Source LLMs May Be Reaching Their "Android Moment" — How Can Startups Seize the Opportunity? | Ronghui Practical Insights

A Conversation on the Future of Open-Source AI.
In the tech world, open source has long since ceased to be merely a novel technical trend or software development paradigm — it has become an unshakable conviction for countless developers and brilliant minds. Open source fully demonstrates how an altruistic spirit can drive exponential growth and tremendous prosperity across an entire ecosystem.
In the era of large language models, open source has been an integral part of the conversation from the very beginning. Guided by the "North Star" of closed-source models, open-source large models have also sprung up like mushrooms after rain, brimming with vitality. The release and commercialization of heavyweight open-source models like LLaMA 2, along with the rise of open-source communities such as Hugging Face, have led many to believe that the open-source world has the potential to go toe-to-toe with closed-source alternatives.
Looking back at history, from computer vision to today's large language models, what role has open source played in driving innovation along the path of AI development? How do open-source communities, builders of open-source systems, and developers view this fertile ground for innovation, and what fruits do they hope it will bear? How can small and medium-sized or vertically-focused startups embrace the power of open-source AI to efficiently develop their own models and applications, and build moats for enterprise growth?
Recently, Ronghui invited experts deeply engaged in open-source infrastructure, open-source communities, open-source models and algorithms, among other fields, to an online discussion on the trends and future of open-source AI.


Bill Jia, Senior Vice President at Meta, shared his perspective on the evolution of the AI ecosystem across all layers over the past decade and the driving force of open source, taking a holistic and long-term view.
At the AI model layer, open source has played a crucial role in bringing computer vision and language translation to their current level of maturity. Taking computer vision as an example, "CNNs (convolutional neural networks) were open-sourced from the moment they emerged, and the subsequent series of models were also largely open-source, accelerating multiple rounds of innovation and technical iteration."
As for today's booming large language models, open-source models are continuously forming their own ecosystem, while simultaneously driving closed-source models to keep upgrading to the next generation. Bill Jia predicts that large language models have the potential to see new architectural breakthroughs capable of understanding relationships between paragraphs, which would be a significant milestone. Additionally, while current large models primarily consider spatial relationships for context inputs, future models will need to account for temporal relationships in inputs — this is critical for video generation and logical reasoning generation. These are all weaknesses of current large models that require research and innovation. Open-source large models also create more opportunities for developers in the ecosystem, including the possibility that "in the next 6 to 9 months, running relatively smaller LLMs on mobile devices could very well become reality."
Beyond the model layer, Bill Jia also systematically analyzed the open-source landscape at the data layer, AI training software platform layer, AI framework layer, and AI hardware layer. At the data layer in particular, he looks forward to more high-quality, diverse, and trustworthy open-source datasets in the future, "which is crucial for further enhancing the capabilities of large language models, and where there are also numerous commercial opportunities."

Hugging Face, as the "top stream" in the AI open-source community, currently hosts over 260,000 open-source models and 46,000 open-source datasets, and holds the conviction that "every company in the future will have its own models, its own machine learning capabilities."
Yifeng Yin, Principal Machine Learning Engineer for Hugging Face's Asia-Pacific region, shared his outlook on open-source ecosystem trends based on firsthand observations of the community.
"We have four observations about the open-source ecosystem: First, a hundred flowers blooming — after powerful open-source models like LLaMA 2 were released to the community, it was like the Cambrian explosion, which we also call 'The LLaMA Moment'; second, the Matthew effect — according to our observations, the top 1% of models account for 99% of downloads; third, light-speed iteration — for example, the interval between LLaMA and LLaMA 2 was very short; fourth, data is king — as open-source models become increasingly powerful, the value of high-quality datasets and data science teams becomes ever more apparent, as data determines whether a trained model has genuine commercial value."
Discussions about open-source business models have been ongoing for some time, and Hugging Face itself has chosen the path of "open source driving commerce", having already launched a series of paid services. Yin cited BloombergGPT, Stability AI, and Grammarly as examples, noting that open-source projects can also possess commercial potential when combined with specific business scenarios and rich training corpora.
On the topic of the mutually beneficial relationship between open source and closed source, Yin used the metaphor that "open source is the floor for closed source, and closed source is the streetlight for open source." Closed-source giants like OpenAI have resource and team advantages; once they've paved the path from zero to one, they light the way for the open-source community. As open-source models steadily improve, numerous developers can quickly build on foundation models to fine-tune and apply them across various scenarios, which in turn pressures closed-source models to iterate further. He also believes that "although closed source currently leads in the large model space, open-source forces will eventually have the potential to go toe-to-toe with closed source, just like the Android and Apple ecosystems."

The OpenMMLab open-source algorithm system is one of the most influential open-source projects globally in the computer vision field. Kai Chen, a young scientist at the Shanghai AI Laboratory, introduced the original vision behind building OpenMMLab from scratch, its iterative journey, and his thinking on continuously expanding outward to create a valuable open-source system.
As early as 2018, inspired by unified deep learning algorithm frameworks, OpenMMLab was born with the mission of creating a unified algorithm framework for computer vision, "so that developers wouldn't have to spend enormous amounts of time reproducing different algorithms and doing all kinds of parameter tuning during algorithm and application development."
Since then, OpenMMLab has continued to develop and iterate, from initially launching object detection frameworks to image classification, semantic segmentation, video understanding, and more — "basically releasing a series of open-source frameworks and applications every year, until today, forming a very complete ecosystem in the computer vision field." Beyond unified and advanced underlying architecture, OpenMMLab currently covers 30+ hot directions in computer vision, with support for 400+ algorithms and 4000+ pre-trained models and out-of-the-box tools.
Building on the broad influence of its open-source algorithm system, OpenMMLab is committed to further expanding its reach and driving a cluster of ecosystem projects. Currently, OpenMMLab open-source projects have accumulated over 90,000 stars, with more than 500 ecosystem projects, and continue to radiate outward to the broader AI community and promote industry-academia-research collaboration.
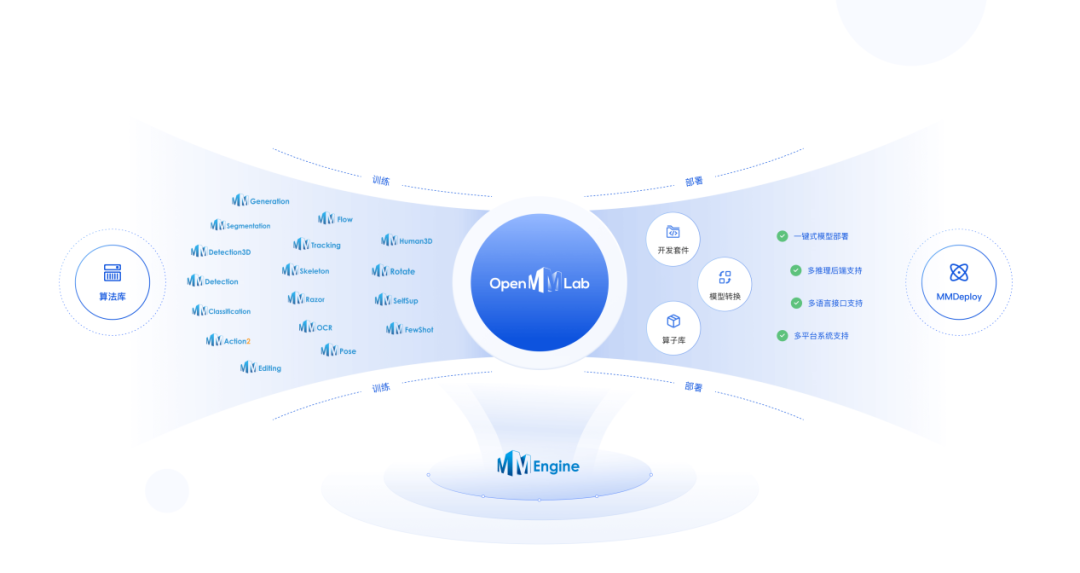
Leveraging its powerful open-source ecosystem, OpenMMLab is also creating value across the upstream and downstream of the computer vision industry. Upstream, it supports chip adaptation, driving the development of domestic software and hardware ecosystems through its algorithm ecosystem; downstream, it accelerates the deployment of computer vision technology at enterprise clients, improving industry R&D efficiency.
Amid the wave of large language models, the Shanghai AI Laboratory also recently released the InternLM-7B open-source model at the World AI Conference. Beyond the model itself, Chen particularly emphasized that "we hope to build a complete large model ecosystem chain through open source." Consequently, InternLM-7B has built a complete open-source system around key stages of large model deployment including data, pre-training, fine-tuning, deployment, and evaluation, "with the ultimate goal of making it truly usable for the community."

The open-source ecosystem continuously expands the boundaries of AI, while also providing excellent innovation opportunities for entrepreneurs and developers. So how should startups embrace this surging open-source force? During the panel discussion, Hui Wang, Senior Vice President at Gaorong Ventures, explored strategies for building growth moats in the era of large models with several experts.
Strategy One: Protect Your Core Business, Then Expand
Facing the opportunities and challenges brought by large models and open source, Bill Jia's advice is to "build the city first, then the moat." Companies should first accurately understand their ecological position in their industry, firmly guard their core business and bottom line, "watch your own cheese"; second, maintain an open attitude toward large models and open source, and think about whether new technologies offer possibilities for expanding their business; finally, the transformation brought by large models is like the fourth industrial revolution — it will ultimately grow the pie for everyone, and in this process, companies should think about which key territories they can enter early.
Strategy Two: Model Selection Should Consider Business Scenarios, Compliance, and Other Factors
With open-source large models blooming everywhere, how should companies select the most suitable model? Tiecheng Wang, Head of Hugging Face China, pointed out that relying solely on academic benchmarks is far from sufficient — companies need to test against their own business scenarios using proprietary datasets and comprehensively evaluate whether a model's capabilities match their needs. For example, when selecting text-to-image models, aesthetic scores shouldn't be the only criterion; rather, companies should holistically assess whether the model aligns with their target audience and use cases. This again highlights the importance of building proprietary datasets — "the return on investment for datasets is very long-term — no matter which model becomes the most popular in the future, you can use it for training and evaluation."
Additionally, Wang advised that when selecting open-source models, companies need to pay attention to local compliance and regulatory policies, including whether the model's license permits commercial use, the transparency of model training, training data copyright issues, and whether data aligns with values.
Ultimately, corporate competition depends on talent, and Wang specifically recommended that startups leverage open-source communities to discover outstanding talent and build talent competitiveness. If a company open-sources a vertical-domain large model, it can naturally uncover excellent developers and contributors in the community, helping the company more precisely target and screen talent.
Strategy Three: Don't Worry Too Much About Model Gaps — Speed Is Everything
Addressing the performance gap between open-source and closed-source models, Chen noted that open-source models iterate very quickly — companies should focus more on their own business scenarios and workflows, as models can be continuously swapped and upgraded. "You might think a model's performance is inadequate today, but a month later a new open-source model emerges and the previous problem is solved; we've also observed that open-source model sizes keep growing, from the previously common 7B to 13B, 30B, and even larger scales."
In this competitive landscape, startups need to remember that "speed is everything." "Some tracks are very crowded, so companies need to efficiently nail down a vertical application and core scenario, then accumulate more user feedback and real-world data to form a data flywheel, converting time advantage into a corporate moat."
Strategy Four: Accumulate Core Competitive Data Through Long-Term Investment
Guan Huang, founder of Shifang Ronghai (Shixue.com), shared practical frontline experience on how to land AI large model applications based on core business.
As a digital vocational online education technology company, Shifang Ronghai currently focuses on how to use AI as an innovation engine to improve student learning experience and teaching efficiency. Initially, Shifang Ronghai applied large model technology to help students with copywriting assistance when learning short video production; it then explored using AI to grade language and creative assignments; and further considered whether large models could efficiently answer students' foundational and knowledge-based questions, improving teaching assistant efficiency.
"We learned, experimented, and iterated quickly, and starting from April this year, fine-tuned based on LLaMA to develop the OpenBuddy-LLaMA series of open-source models, with excellent question understanding and answering capabilities." Along the way, Huang and his team also continuously improved response accuracy through model optimization and data annotation, while exploring the model's multi-turn dialogue capabilities. Meanwhile, by iterating models in core business scenarios, the company accumulated core competitive data.
In August this year, Shifang Ronghai released and open-sourced the OpenBuddy-LLaMA2-70B model, a new cross-lingual dialogue model based on the LLaMA 2 foundation, which has already achieved very strong results in internal commercial scenario testing at Shifang Ronghai.
Looking to the future, Huang has high expectations for Chinese open-source models and Chinese corpora, and is "psychologically prepared for long-term investment" — "don't overestimate the short-term effects of large models, and don't underestimate their long-term impact."
Still water runs deep — it doesn't compete to be first, but to flow endlessly. Open-source models are dazzling in their variety, but the ultimate question for enterprises remains: are you open enough to embrace technological change, and do you have the resolve to hold your ground in core scenarios.




