Securing Hundreds of Millions of Yuan in Pre-A Funding, How Westlake Omics Builds the AlphaFold of Proteomics | Gaorong "Future"

Deciphering the mathematical laws of the microscopic protein world to enable proteomics-based precision medicine.
In July 2021, the DeepMind team and the European Bioinformatics Institute (EMBL-EBI) released a database of protein structures predicted by AlphaFold, completing structural predictions for 98.5% of the human proteome. It was considered one of the most important scientific breakthroughs of the century.
Proteins are the gears of life, but knowing the shape of a gear alone doesn't let you assemble a functioning living machine. We also need to understand the types and quantities of different gears within an organism; more importantly, these gears are in constant dynamic change and interaction. This is the code that proteomics seeks to crack.
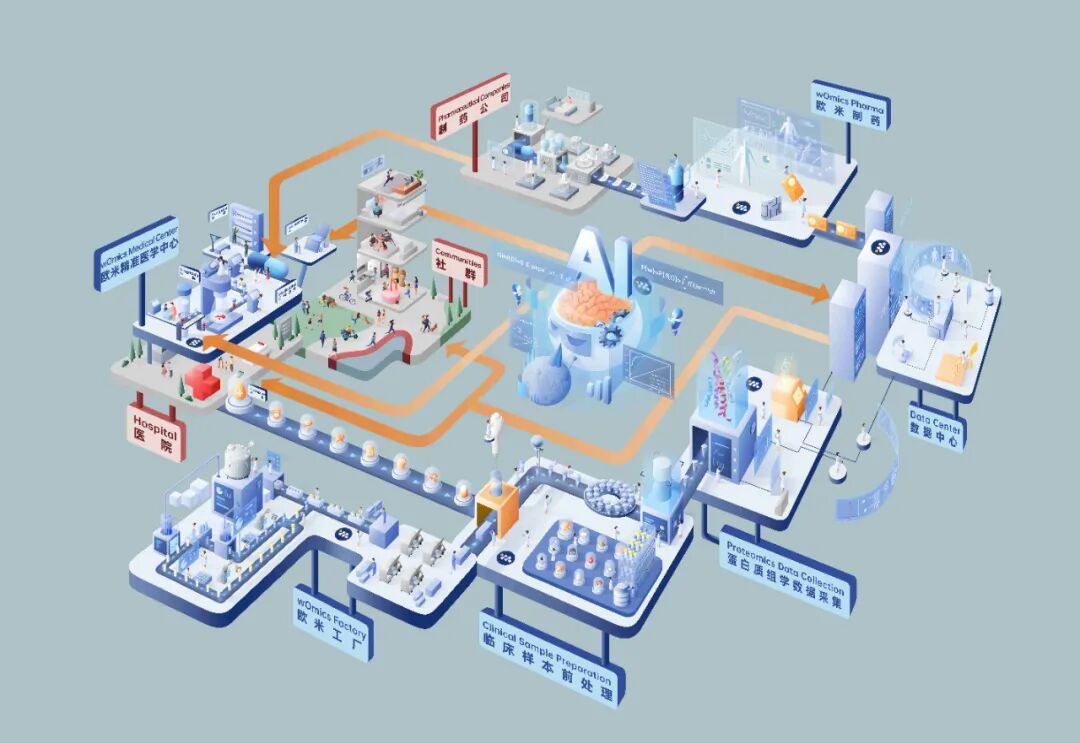
Founded in July 2020, Westlake Omics is dedicated to developing and applying multi-omics technologies centered on mass spectrometry-based proteomics. Drawing on large-scale proteomics data, the company aims to discover quantifiable biological patterns to advance precision medicine and drug development. Today, Westlake Omics announced the completion of a Pre-A funding round of several hundred million yuan, co-led by Efung Capital and Hillhouse, with Gaorong Ventures, Med-Fine Capital, and Westlake Innovation and Venture Capital participating. Gaorong Ventures had previously co-led Westlake Omics' seed round in early 2021.

We also spoke with Dr. Tiannan Guo, a leading expert in proteomics — Principal Investigator at the School of Life Sciences at Westlake University, Director of the imarker Lab at Westlake Laboratory, and Founder of Westlake Omics. Here is his account:

When people think of life sciences, they often think of genes. Genes are the blueprint of life, a one-dimensional linear sequence; through the transcriptome, genes are expressed as proteins that make up the three-dimensional living organism. Readers of the science fiction novel The Three-Body Problem will recall that in one-dimensional space, the complexity of three-dimensional space seems fundamentally incomprehensible. Compared to genes, proteins are orders of magnitude more complex. First, a single gene can be expressed as multiple proteins; second, proteins constantly transform across time and space like "Transformers"; additionally, proteins undergo post-translational modifications, form complex complexes, and are continuously generated and degraded. While humans have largely unlocked the genome, no scientist can yet tell us how many proteins exist in a single red blood cell. Its complexity exceeds the entire network of human relationships on Earth today.

At the same time, human health and disease are intimately tied to proteins, and the effectiveness of disease treatment depends on the regulation of protein machinery. Many will remember the "miracle drug" Gleevec from the film Dying to Survive. Gleevec treats chronic myeloid leukemia, once considered incurable. More than a decade ago, I was studying and working in the hematology department at Wuhan Union Hospital when Gleevec had just entered China. I remember very clearly: one box cost 300,000 yuan. Many patients couldn't afford it, so the department would buy the medicine and sell it to patients pill by pill. We later learned that the drug's target is a fusion protein — inhibiting this fusion protein with a small-molecule drug controls the disease's progression. If we hope to make more "incurable" diseases treatable in the future, it must be built on a deeper understanding of proteins.

The proteomics we study goes beyond protein structure. We want to see, in a clinical sample or a tumor cell, which proteins are present, how many of each, and how they change dynamically. This data could have transformative implications for drug discovery, understanding health, and treating disease. This year's Nobel Prize was awarded to meteorologists for the first time, answering why climate models remain reliable despite weather's variability and chaos.
▲ If humans can predict the weather, why can't we predict disease progression? ▲ Physics, chemistry, and economics have formulas and laws — why doesn't the microscopic world of proteins? ▲ COVID-19 struck suddenly — why do some people get mild cases while others become severely ill? ▲ Why does a targeted drug work for some cancer patients but not others, or work initially but then lose effectiveness due to resistance?
All these questions stem from our lack of understanding of protein machinery. I believe this inability to understand comes down to two things: we lack the process of accumulating quantitative data on proteins, and we lack suitable algorithms. We hope to collect as much dynamic proteomics data as possible and use AI to build a new engine capable of predicting protein dynamics. This engine would be far more complex than AlphaFold and requires a sufficient volume of data as its foundation. In the past, we lacked proteomics data because we lacked the right technologies and tools. Just as we once had no telescopes to see the stars, no microscopes to see cells — fortunately, today we have cutting-edge proteomics technologies opening a new door.

In recent years, mass spectrometry has advanced tremendously, enabling protein detection at an entirely new level. Mass spectrometry is a highly complex, interdisciplinary engineering feat, combining chemistry, physics, biology, and data analysis. It depends on extremely expensive equipment that is constantly being updated, so it has remained largely confined to universities and laboratories. But bringing it into clinical settings presents an entirely new challenge: identifying and quantifying proteomes from clinical samples, which are far more complex than animal samples in labs. Our technological foundation is PCT-SWATH/DIA, short for Pressure Cycling Technology, Sequential Window Acquisition of All Theoretical Fragment Ion Mass Spectra, and Data-Independent Acquisition. This high-throughput proteomics technology was developed in the research group led by Professor Ruedi Aebersold in Switzerland, one of the pioneers in proteomics, where I previously worked. It enables high-reproducibility, high-throughput mass spectrometry analysis of small clinical samples, with findings published in Cell, Nature Medicine, and other journals. This technology can analyze extremely minute tissue samples — virtually any protein-containing sample, including blood, urine, hair, nails, bone, and gut microbiota. Additionally, we can process paraffin-embedded tissue, unlocking a vast archive of clinical samples that have been stored away. A unique key to achieving this is Pressure Cycling Technology (PCT), which uses rapid cycles between ambient pressure and ultra-high (liquid) pressure to enable precise extraction of biomolecules. Imagine placing a sample in a 150-microliter tube, applying 3,000 atmospheres of pressure, releasing it, then pressurizing again in repeated cycles — effectively extracting proteins from extremely minute tissue samples.

On another front, we are developing computational resources to enable rapid, low-cost analysis of large-scale proteomics datasets. The Westlake Omics team is still young, but we already possess world-leading clinical proteomics technology. Globally, in terms of both the variety and volume of clinical samples analyzed and proteomics data accumulated, we are among the leaders.
Building on this large-scale proteomics data, we are also combining leading AI algorithms to build an intelligent engine that can predict proteome dynamics. Currently, no known mature AI algorithm can be directly applied to proteomics big data analysis, because this represents a new data type, a new data format, and a new scientific problem. We believe China's AI technology is among the world's best, both in theory and practice, with abundant outstanding AI talent. After AlphaFold's breakthrough, many AI researchers have wanted to enter the life sciences — I see this as a very positive trend.

With this data and technology, we hope to truly advance precision medicine. Precision medicine can be understood broadly or narrowly, but it mainly encompasses two aspects — diagnosis, achieving early detection of disease whenever possible; and treatment, using the most appropriate drugs. In both directions, Westlake Omics has already achieved preliminary results and made concrete attempts.
On the diagnostic front, we have pioneered an AI-enabled proteomics-based LDT product for distinguishing benign from malignant thyroid nodules, planned for launch in Q1 2022. Thyroid nodules are extremely common — 50% of adults have them. Diagnosing their presence isn't the problem; ultrasound can detect them. The challenge is determining whether they're benign or malignant. Currently, 30% of thyroid nodules cannot be classified as benign or malignant through cytological needle biopsy. For patients, the dilemma is whether to remove them. The thyroid is a vital organ, a bridge connecting the brain to the rest of the body; some compare it to a company's CEO. Removing it requires lifelong hormone replacement therapy. Some suggest genetic sequencing for diagnosis, but while highly sensitive, it has poor specificity — only 10% to 50%. This means 50% to 90% of cases diagnosed as malignant are actually benign. Through our diagnostic LDT product, we can raise nodule classification accuracy to around 90%. Our product is currently undergoing multi-center, multi-country validation and optimization. This is an excellent application of proteomics combined with AI in diagnostics, and represents the first time worldwide that such large-scale, multi-center proteomics data has been generated. We have already collected proteomics analysis data from over 3,000 samples. Beyond thyroid cancer, we will further advance the development and commercialization of multiple in vitro diagnostic products including for prostate cancer, breast cancer, and colorectal cancer.
Another diagnostic application involves early detection of chronic diseases such as diabetes and hypertension. Chronic disease develops through a complex, multifactorial process involving genetics, environment, and lifestyle. We have a research cohort tracking diabetes and hypertension patients over more than a decade, periodically collecting blood, urine, and other samples for proteomic analysis to develop multimodal models predicting which individuals are at high risk.
Traditional disease diagnosis has generally been static; but in reality, all disease is dynamic, with conditions changing daily. Beyond observing patient temperature, red and white blood cell counts, and other information, we believe many changes occur at the microscopic level before symptoms appear. We are currently collaborating with multiple hospitals to build an auxiliary precision medicine platform, hoping to monitor proteomes throughout patients' journeys from admission to treatment, recovery, and discharge — enabling more granular, fundamental disease monitoring.
On the treatment front, we also have concrete examples. Nearly all drugs are designed to target proteins; even those not directly targeting proteins act through them. Drug success therefore depends on protein detection. The application of proteomics data to drug development has only become practical in the last year or two. We have a project in ovarian cancer treatment. Ovarian cancer is a highly aggressive women's disease, and in clinical practice we find that certain drugs work remarkably well for some patients while others develop resistance. We have collaborated with several hospitals to develop models predicting which patients will respond better to which drugs. Going forward, we will expand our presence in AI-driven drug discovery, enabling pharmaceutical researchers to access proteomics analysis results that were previously unthinkable or prohibitively expensive.

Many want to work in proteomics, but why is it so difficult? Because it involves too many disciplines — chemistry, physics, biology, medicine, artificial intelligence, drug development. These fields must be integrated, not merely mixed like oil and water. This requires team leaders who understand each discipline. I trained in medicine, later mastered mass spectrometry principles and hands-on operation, have written code, and studied machine learning fundamentals. So a major part of my role in the team is being a translator. Sometimes the same word means different things to people from different disciplines. I have to switch between different languages to enable cross-disciplinary collaboration. By "language" I mean each discipline's terminology, theoretical frameworks, and practical details.

Of course, relying on one person to speak multiple languages isn't enough — we also hope to cultivate a generation of such talent. Currently, Westlake Omics has assembled a team of nearly 80 people spanning biotechnology, artificial intelligence, and drug development. Looking ahead, I greatly look forward to inviting more cross-disciplinary talent to join us in decoding the secrets of life.