When Robots Meet Large Models, the Gears of "Intelligence" Begin to Turn | Ronghui Industry-Academia-Research Seminar

Shaping intelligence with form, breathing spirit into machines.
Since Alan Turing first proposed the concept of Embodied Intelligence in 1950, it has undergone decades of multidisciplinary development and convergence. With the advance of generative AI and large models, renewed expectations for embodied intelligence have been awakened, drawing active engagement from both academia and tech companies.
To put it simply, embodied intelligence refers to the capacity to generate intelligence through physical bodily experience. A major trend here is the deep integration of AI and robotics — robots are becoming a critical platform for large models, while large models are also reconstructing the robot development workflow, enabling general-purpose scenarios, multi-tasking, and rapid development.
Further out, general-purpose robots hold the promise of demonstrating high-level intelligence and practical value — not only with capabilities in perception, understanding, reasoning, and decision-making, but also with the ability to authentically interact with the physical world and efficiently execute commands and tasks. This opens up far greater possibilities for intelligent living.
Of course, embodied intelligence still faces numerous challenges before true commercial deployment, spanning robot hardware, algorithms, data, and computing dimensions.
Recently, Gaorong Ventures' Ronghui platform hosted an online industry-academia-research seminar on "Embodied Intelligence," bringing together experts from the research community, AI computing enterprises, and humanoid robot manufacturers to share their frontline explorations from their respective vantage points.
Below are highlights from select speakers (edited for clarity):


Today, many embodied intelligent agents already demonstrate strong capabilities in specific scenarios, even becoming "experts" in their domains. But what we truly aspire to is a general robot — one that can tackle 1,000 different tasks across 1,000 different scenarios, whether factories, laboratories, or kitchens, and handle all manner of objects.
So why hasn't the fully general-purpose robot arrived? Why can't we yet achieve this level of generalization? Consider: when a robot opens a refrigerator, it encounters a vast array of foods, beverage bottles, and so on. It's nearly impossible for training scenarios to encompass such object complexity, let alone the even greater complexity of real-world environments.
From practical challenges encountered in the field, we've abstracted three generalization requirements for embodied intelligence: visual appearance, 6D poses, and object types — and proposed corresponding solutions.
1) Visual Appearance Generalization
We know that in computer vision, ImageNet served as a pivotal benchmark dataset that significantly propelled the field's development. This led us to ask: could we build a reinforcement learning benchmark platform for visual generalization in embodied intelligence?
Thus we launched RL-ViGen, a platform where embodied intelligence algorithms can be compared and evaluated, with preliminary validation of which approaches can generalize to sufficiently diverse scenarios — and thus have the potential to move from the lab into everyday households.
RL-ViGen currently integrates a rich variety of task categories, including robotic arm manipulation, autonomous driving, dexterous hand operation, quadrupedal and bipedal robots, and indoor/outdoor navigation. Going further, RL-ViGen also provides multiple generalization types, including appearance (color, texture, etc.), camera viewpoint, lighting, structure, and embodiment.

Additionally, we've proposed a Pre-trained Image Encoder for Generalizable Visual Reinforcement Learning method (PIE-G).
Previously, when pre-training and testing embodied intelligent agents, inputting different visual scenes led to significant variance in model generalization performance. How to maintain training efficiency while developing more robust and generalizable models? PIE-G directly leverages representations generated by ImageNet pre-trained models, embedding them within visual reinforcement learning algorithms. By using early layers and updating Batch Norm statistics, it further breaks through bottlenecks in agent generalization capability.
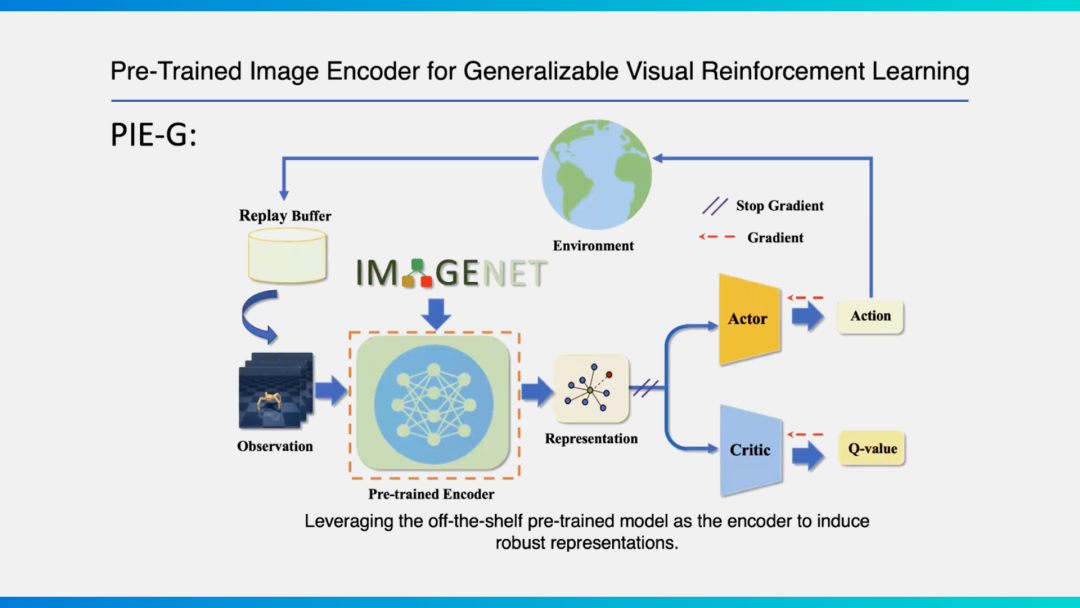
PIE-G achieves an average 55% improvement in generalization performance over existing solutions, with gains up to 127%. Visually, whether in MetaWorld or the autonomous driving simulator CARLA, PIE-G can handle diverse background variations.
2) Intra-Category Object and Pose Generalization
Finding correspondences is the key to achieving 6D pose generalization. What do we mean by pose generalization? As humans, if we learn to use one knife, we can use others because we identify key feature points (handle, tip, etc.). Thus, to achieve pose generalization, we need to find these keypoint correspondences.
Computer vision already offers many mature methods, such as unsupervised approaches like KeypointDeformer for identifying object key feature points. But in the real world, factors like low-quality point clouds and pose rotation make these feature points difficult to leverage effectively.
We've proposed a Teacher-Student Framework. Using the classic "teacher" network architecture PointNet++ to extract object features, we obtain a set of keypoints through unsupervised methods; the "student network" then learns to imitate these keypoints (in a supervised manner), maintaining consistent output for any rotated input.
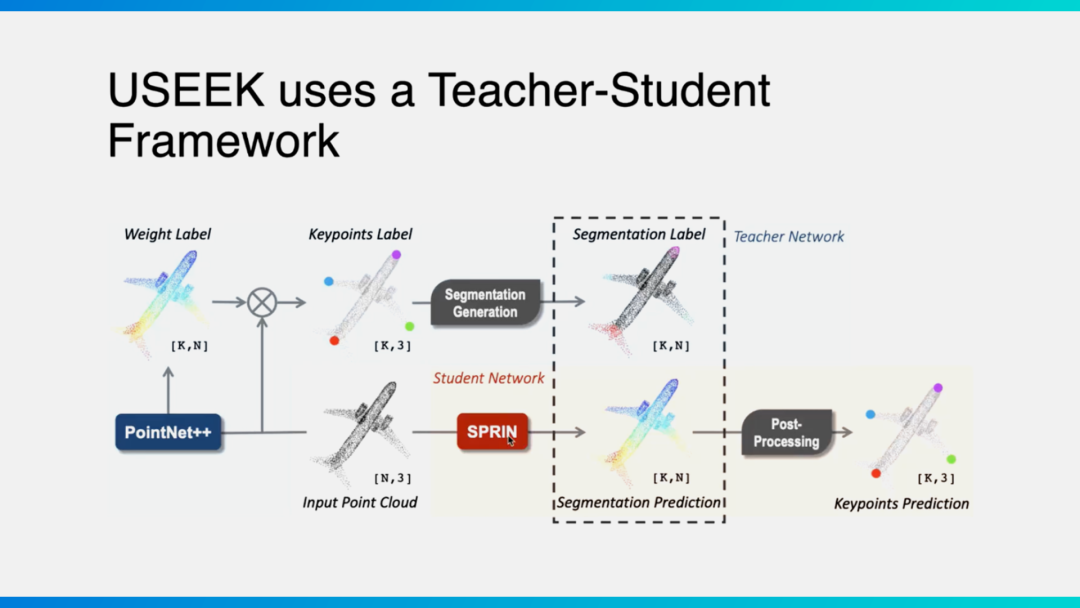
This framework enables us to find intra-category object keypoint correspondences, thereby achieving generalization to any pose within a category.
3) Multi-Object Generalization
Going further, how can embodied intelligence achieve generalization across diverse object types? One preliminary approach is designing specific robot morphologies — for instance, ArrayBot, a tactile-controlled robot we built from scratch.
ArrayBot adopts a distributed structure, essentially an array, that reads tactile information from objects without needing to account for gravity or visual interference. Additionally, based on reinforcement learning, we conducted large-scale training of the robot in simulation environments; the resulting policies can directly manipulate different real-world objects.

ArrayBot shows promise as an intelligent conveyor belt in industrial scenarios, or as a smart table in home environments. Of course, ArrayBot is just one morphological exploration; other configurations such as soft robots also hold potential for solving multi-object generalization challenges.
Related papers: RL-ViGen: A Reinforcement Learning Benchmark for Visual Generalization, 2023. USEEK: Unsupervised SE(3)-Equivariant 3D Keypoints for Generalizable Manipulation, 2023. ArrayBot: Reinforcement Learning for Generalizable Distributed Manipulation through Touch, 2023.


Embodied intelligence has several defining characteristics: it is grounded in first-person perspective, enabling individuals to understand environments, make decisions, and most importantly interact with and learn from that environment, then execute low-level actions. Meanwhile, embodied intelligence tasks are extraordinarily broad, encompassing visual navigation, tabletop manipulation, object arrangement, embodied question answering, mobile manipulation, instruction following, and more.
Thus, we've attempted to build a general embodied intelligence system capable of wide-ranging tasks — one that can physically accomplish diverse tasks while providing comprehensive intelligence upgrades when integrated with existing robots.
Addressing several core challenges currently facing general embodied intelligence systems, we've proposed the following solutions.
1) First-Person Embodied Cognition
Traditional computer vision has largely focused on third-person "perception" capabilities; first-person "cognition" goes beyond merely seeing and understanding object categories, locations, and contours — it also learns how to interact with objects, grasping their affordances. When opening a drawer, for instance, attention focuses on the handle as the operable part.
Consequently, we needed a first-person, fine-grained, highly interactive dataset to support training. To this end, we created the EgoCOT dataset. This dataset comprises over 2,900 hours of fine-grained video-text annotation data. It was collected from a first-person perspective, with interaction across a rich variety of scenarios and diverse objects.
2) General Decision-Making and Planning
With a cognitive system in place, embodied intelligence still needs to handle complex tasks in open worlds, making decisions and plans — which requires a multimodal, general-purpose knowledge base. For this, we introduced EmbodiedGPT, China's first multimodal embodied intelligence large model. EmbodiedGPT possesses embodied planning capabilities, outputting step-by-step task plans from visual input; it also features Video Capture, Video Q&A, and even multi-turn dialogue capabilities.
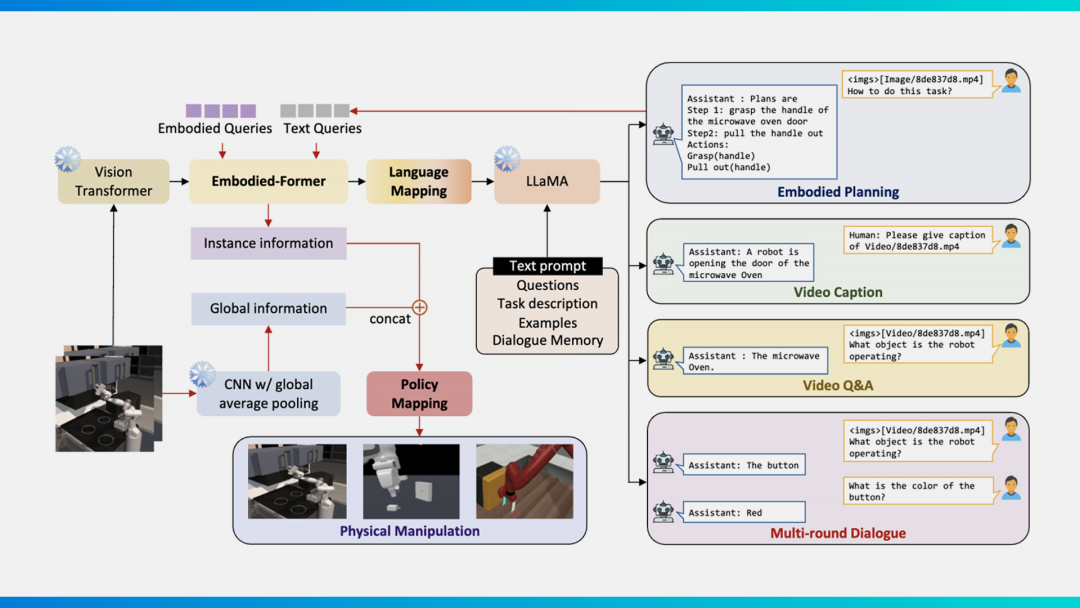
EmbodiedGPT is built on ViT vision models and LLaMA language models, better suited to the needs of universities and SMEs. From vision to language, we designed Embodied-Former and Language Mapping to bridge the two modalities. Uniquely, through learnable Embodied Queries and attention mechanisms between visual features and text features, we can extract the most task-relevant feature information and pass it to the language model via the language mapping layer.
The model also supports code generation, directly producing step-by-step instructions for sequential execution.
This model has already shown application potential in general scenarios such as visual navigation and real robotic arm experiments.
3) Low-Level Skill Learning
For a truly embodied intelligent system, we also hope to master new skills with very high learning efficiency, then transfer and generalize them to new scenarios and tasks. To this end, we primarily leverage reinforcement learning to research efficient policy learning, knowledge transfer, and multi-scenario generalization algorithms.
Related paper: EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought, 2023.


1) Hardware-Software Platforms Accelerating Robot Development Efficiency
NVIDIA Isaac is an end-to-end robot development platform encompassing simulation platforms, algorithm development modules, middleware, and underlying acceleration libraries. Whether building robots from scratch, implementing algorithmic operations, or rapidly filling gaps in robot development applications, acceleration software libraries are available to support and enhance development efficiency for robots, particularly AI-powered robots.
Data is critical for AI robot development, yet data collection faces constraints in many scenarios. Isaac Sim, built on Omniverse, is a robot digital twin simulation platform that helps robots generate annotated datasets in virtual environments. Within the platform, digital twin environments can be created through 3D modeling, environments can be randomized and modified, and virtual datasets can be generated through replicator as data assets for model training, data playback, and more. Isaac Sim delivers precise rendering of ray tracing, object materials, and robots — achieving digital twin-grade simulation.
2) Witnessing More Large Model Deployment on Robot Edge Devices
Facing the advance of large models and general-purpose robots, we believe that robots will ultimately become the optimal platform for large model inference, and we expect to see more use cases of large models deployed on robot edge devices. At that point, many mobile robots will possess large model interaction capabilities — a manifestation of embodied intelligence.
This also places higher demands on computing. As an AI computing platform, we hope the most cutting-edge core technologies can be applied on NVIDIA's platform, and based on these technologies introduce better hardware architectures and software infrastructure to meet ever-growing compute demands, with more accessible software ecosystems for compatibility. We also hope that in terms of commercial deployment, leading industry customers can provide more feedback to help developers and users achieve smoother implementation.
From a scenarios and applications perspective, within the foreseeable future, we all have the opportunity to witness rapid explosive growth in robotics. Humanoid robots, for instance, can improve efficiency in warehousing and logistics, and can also undertake dangerous work such as bomb disposal and power line inspection. Like "special forces," they will become friends and assistants to humanity.
Embodied intelligence still faces many difficult challenges before deployment, requiring long-term technical accumulation and R&D investment. Therefore, it demands concerted industry-academia-research collaboration, converging efforts to accelerate this technology's entry into our lives.




