YITU Claims Another World Championship, This Time in "Voiceprint Recognition"!

YITU demonstrates powerful "generalization" capabilities, with both depth and breadth.
© This article is republished with permission from QbitAI (WeChat ID: qbitai). Please contact the original source for reprint requests.
Recently, YITU claimed the top spot at the VoxCeleb Speaker Recognition Challenge (VoxSRC), a global speaker recognition competition.
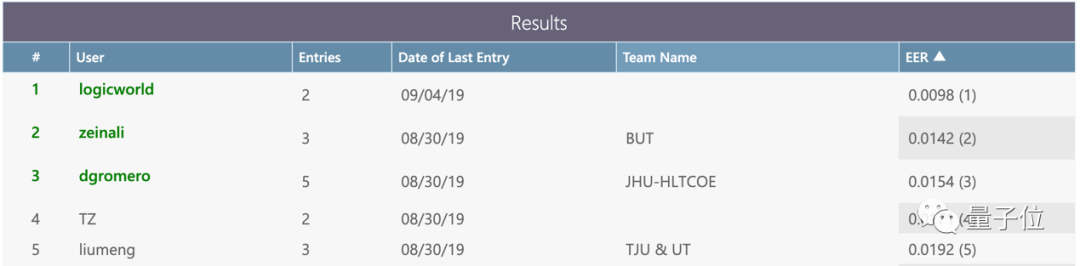
In this challenge that brought together top talent from China and abroad in the speech field, YITU's logicworld team won with an absolute lead.
Moreover, the competition focused on precisely the most cutting-edge track in speech recognition today: speaker recognition.
YITU had previously demonstrated considerable strength in visual perception, speech recognition, and semantic understanding. Now, with a world championship in yet another frontier technical domain, the company is showcasing not only its technical depth but also its expanding breadth.

What Championship Did YITU Win?
VoxSRC is organized by scholars from Oxford University, Stanford Research Institute, and MIT.

Participants included established powerhouses such as Johns Hopkins University, the French Institute for Research in Computer Science and Automation (INRIA), and NEC, as well as Chinese institutions and companies including Tsinghua University, Tianjin University, Sun Yat-sen University, YITU, and Ping An Technology. While fingerprint and facial recognition are already familiar to the general public, speaker recognition — another form of biometric identification — remains at the frontier of technical challenges. It frequently appears in science fiction films and is often cited by speech AI companies as a future aspiration. Authoritative benchmarks for speaker recognition are scarce, and the VoxCeleb Speaker Recognition Challenge is considered one of the few competitions that truly tests the technology. Its core task is using AI to identify speakers from natural speech. The training dataset used is VoxCeleb2, provided by Oxford University. This dataset comprises audio collected entirely from YouTube, covering scenarios including celebrity red carpets, keynote speeches, talk show interviews, and major sports commentary, with over one million utterances from 5,994 celebrities.

These celebrities span diverse genders, ethnicities, accents, professions, and ages. The audio contains a wide variety of background noise, including sudden environmental sounds, overlapping voices, laughter, echoes, indoor noise, and recording equipment artifacts.
The test set is entirely unlabeled, making it a "blind test" that ensures fairness in the competition.
Facing such challenges, getting AI to accurately extract acoustic features and speaker characteristics for precise matching is no easy feat. In a paper published at Interspeech 2018, the authors from Oxford's Visual Geometry Group trained a ResNet-50 that achieved a 3.95% equal error rate (EER), surpassing baseline methods at the time.
In this competition, YITU not only shattered that record by compressing EER to 0.98%, but also finished well ahead of the second-place team at 1.42% — claiming the championship with a decisive margin.

Technical "Redundancy" to Power Scenario-Based Deployment
As a biometric technology, speaker recognition itself has broad application prospects. It can play an important role in personal information encryption. As a biometric solution, it can also provide enhanced security and strengthen risk control in industries such as finance where personal information security demands are high.
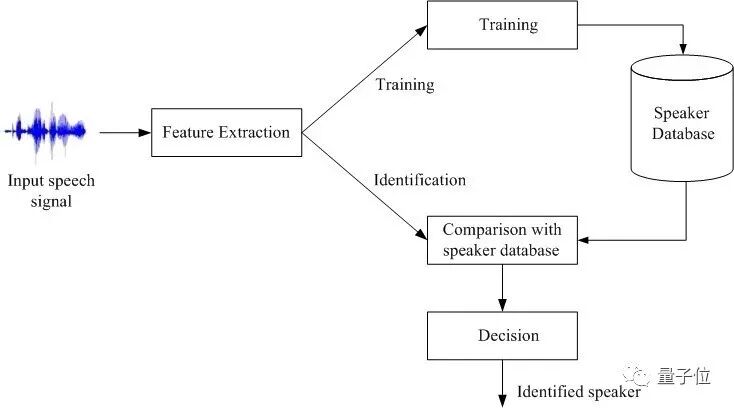
Furthermore, speaker recognition represents a major challenge for intelligent speech applications to become truly operational. Cracking it is essential for building gender and age profiles, identifying languages and dialects, and ultimately achieving genuinely personalized voice interaction for every individual. As AI becomes increasingly deployed across industries in scenario-based applications, technical redundancy — the ability to provide different solutions for different problems — is becoming a core competitive requirement for AI companies. Only with genuine capability and reserves across multiple technologies can a company develop and deploy more comprehensively. In other words, the next phase of AI company development demands both depth and breadth.

Depth & Breadth for AI Companies
This appears to be the thinking behind YITU's current expansion. Previously, YITU was best known as one of the "Four CV Dragons," a label emphasizing its position in computer vision. The company had indeed won multiple international computer vision competitions — for instance, claiming first place for three consecutive years in the Face Recognition Vendor Test (FRVT) conducted by the U.S. National Institute of Standards and Technology (NIST). Its AI vision capabilities have also earned recognition in real-world business scenarios across security, finance, and healthcare. But since 2018, YITU has demonstrated remarkable "generalization" capabilities, integrating its AI technologies and rapidly achieving core breakthroughs in expanded domains. In speech, its speech recognition algorithm achieved a character error rate of just 3.71% on AISHELL-2, the world's largest open-source Mandarin database, substantially breaking the previous record. In NLP, YITU collaborated with Guangzhou Women and Children's Medical Center and other institutions to apply natural language processing to pediatric disease diagnosis, with results published in Nature Medicine — a new milestone for Chinese AI in medicine.

Subsequently, YITU completed development, tape-out, launch, and commercial deployment of its proprietary AI chip "QuestCore," advancing the "algorithm-defined chip" concept and proposing a new theory of "intelligence density" to provide a coordinate reference system for AI scenario-based deployment.

Most recently, at the "China Artificial Intelligence Summit Forum" co-hosted by the Ministry of Industry and Information Technology, the Ministry of Public Security, and the Cyberspace Administration of China, YITU's AI chip received the AI Innovation Star award. YITU also competed in the inaugural multimedia information recognition competition, winning 10 A-grade awards out of 11 tasks — the most of any participant.

The "YITU path" and "YITU model" are being discussed more frequently. This pattern is not unfamiliar in the history of tech entrepreneurship: first establishing vertical depth, then platform migration to build a more technically comprehensive, more broadly applicable platform. But in the history of AI, no one besides YITU has managed to maintain both depth and breadth simultaneously. "So the speaker recognition championship may not even represent the full extent of YITU's capabilities." The YITU path is worth exploring — upward and downward.



YITU Defends Championship at Global Facial Recognition Competition | Gaorong Sharing
Leo Zhu, YITU: A New Era of AI — We Believe Because We See | Gaorong Sharing
