Linear Capital π Review: Agent Companies and Model Companies Are Entering Each Other's Turf — What Are They Thinking? | Linear Event

The logic of competition isn't "devouring," but "running toward each other."

"Linear Tech π" is a new frontier-tech salon series launched by Linear Capital, designed as a no-fluff, high-signal forum where founders and operators can exchange substantive ideas.
The inaugural event took place in Shanghai on November 2. We were joined by Yifeng Yin, co-founder and CEO of TEA.AI; Minghao Guan, founder and CEO of Final Round; Andrew, co-founder of Macaron AI; and Feihu Tang, head of developer relations at Moonshot AI, alongside Linear Capital's managing director Can Zheng and senior director Zeren Bai. Together, they explored how AI agents are being deployed in the trenches across their respective fields.
We received over a hundred applications for this session. To preserve the quality of discussion, we had to cap attendance. But we've distilled some of the standout insights from the event to share here.
PART 1
What Are the Four Core Elements of Building an AI Agent System?
Yifeng Yin | Co-founder and CEO, TEA.AI
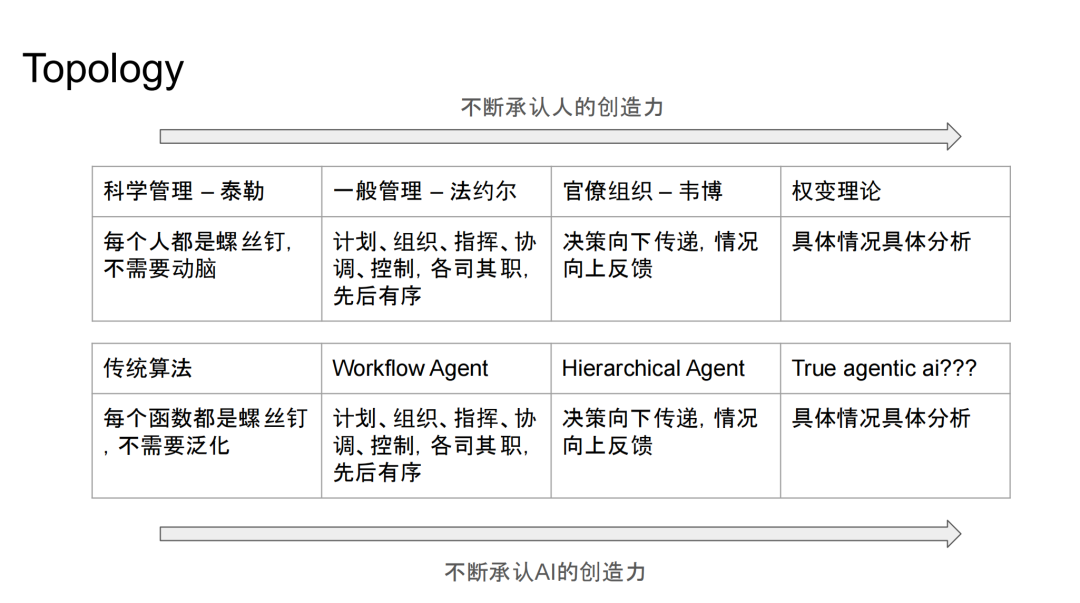
Agent topology — the connection structure and interaction patterns between agents — is not a technical problem but a management problem. It has evolved through four generations:
-
Scientific management, like classical algorithms: every agent is a cog, executing fixed workflows without thinking;
-
General management, corresponding to workflow agents: aside from the boss who designed the workflow, no one in the chain has real decision-making authority; each person does a bit of thinking, executes in a planned and organized manner, and makes minimal decisions;
-
Bureaucratic organization, which is today's popular hierarchical agent: a brain handles operations, a strategist handles planning, and orders flow down while information flows up — the pyramid of a large corporation;
-
The ultimate form is True Agent: all agents think collaboratively and complete tasks together. We're currently in the transition period between Hierarchical Agent and True Agent.
On LLM selection and training, one trend is that you must continually acknowledge AI's creativity and judgment. What do you want your agent to be? How do you want these agents to work together? This requires giving each agent a dedicated role.
Taking today's most prominent models as examples, they represent four distinct personalities: GPT is like "a college student fresh out of gaokao" — knows everything but speaks rigidly, lecturing without emotional intelligence; Claude is the "Silicon Valley big-tech engineer" — politically correct, strong at long-context tasks, patient, and tool-savvy; Gemini resembles "the art student" — multimodal talent is its strength, other capabilities are average, thinking is scattered and abstract; while Grok is the "sarcastic current-affairs pundit" — quick with memes, high EQ, calls things as they are without pretension, now becoming the "go-to for emotionally intelligent communication."
Context optimization is fascinating — to some extent, context engineering is about compensating for what large models lack. Four key principles: First, clarify identity: tell the AI upfront "who you are and what you're doing," and every subsequent generation will be guided by this. Second, avoid neologisms: stick to words the model has seen countless times; precision matters, and coining new terms is like forcing extra training on the fly. Third, brevity wins: shorter context is better, provided no critical information is lost; extraneous content dilutes the AI's attention. Finally, reflection mechanisms: AI doesn't know if its output is right or wrong; it needs user feedback and hard-rule validation to self-correct.
Tool design follows a "microservices architecture" logic, with four principles: 1) Don't use AI if you don't have to — it's expensive and not always accurate; if a SaaS tool can solve it, don't bother the LLM. 2) Safety first: guard against prompt injection attacks, set proper permissions, and protect data — don't let AI become a security hole. 3) Single-purpose tools: avoid "Swiss Army knife" designs; instead carry a "toolbox" where each tool solves one problem well, avoiding ineffective sharing. 4) LLMs select tools based on name and description, so design with common, precise vocabulary, clearly stating purpose; names should be standardized, descriptions detailed — essentially writing DocString. Follow these standards, and your agent system will run smoothly.

PART 2
How Can AI Marketing Agents Break Through Customer Acquisition Bottlenecks?
Minghao Guan | Founder and CEO, Final Round
Traditional SEO's bulk-content playbook has been shattered by AI. With Google's algorithms iterating at high frequency, "timeliness" has become the core competitive advantage for traffic. The underlying logic is event-driven marketing — essentially precision "traffic-hijacking." So much is happening in the world, every day brings massive changes, and these changes may connect to your industry, product, team, even your company. So the system we built understands what's happening in the world daily, identifies hijackable moments, then goes platform-wide to capture that traffic. In the AI era, SEO isn't about content volume but response speed — traffic always tilts toward whoever speaks first.
GEO's core is global content distribution, aiming to dominate search results across regions. The key play is using AI to build brand presence at scale on high-authority platforms. Early tricks like prompt-injection with special instructions are dead. Today's core is multi-channel exposure across news media, social platforms, and content sites — repeating keywords through different accounts, even coining proprietary terms like "interview partner." Even for something unprovable like "Was Stephen Hawking an alien?", your article can sit as the sole source in search results.
Influencer marketing's core pain point is scale management. By building a highly agentic workflow, one employee can manage 120+ global creators. AI can send bulk "spam"; after firing off millions of emails, we've established long-term partnerships with 120+ influencers. Post-collaboration, the system automatically monitors video exposure; once it hits the agreed 1 million view threshold, payment is automated. If not met, our AI agent fires off a warning: "Step it up or you're fired." We now process hundreds of monthly payments and performance bonuses fully automated, freeing human effort for core creator signing and partnership strategy.
Creator management is another interesting topic. Internally incubating a brand-suitable creator is extremely difficult. The core logic is figuring out how to make fewer than 10 people function like 1,000. The algorithmic key is global video repurpose: an internal creator team of under 10, powered by AI workflow, achieves scaled content output. One raw video, processed by AI, becomes 20 versions in different languages, simulating 20 different personas, distributed across 20 platforms. For example, an IP video of two ducks eating, after AI adaptation, gets deployed in dozens of languages across global accounts — even Burmese. Though the same people might follow all these accounts, their user count successfully multiplied several times over.
On lifecycle marketing, Americans are still stuck in early-2000s email and SMS retargeting, while China leapfrogged straight to the 22nd century — AI enables truly personalized, thousand-person-thousand-face lifecycle marketing at scale. The core has three modules: First, a user tagging system that transforms uploaded resume data — location, education, career goals — into structured data for precise targeting. Second, an AI decision engine that generates different solutions for each user upon entry. Third, a layer built atop existing databases that dynamically responds to user behavior: automatically sending tutorial emails when a user lingers too long on a page, or analyzing usage paths to offer alternatives when someone requests a refund — extending B2B white-glove service to every individual user. This kind of mass customization is crucial.

PART 3
After Scaling Law Slows, How Can AI Agents Create Core Value Through Training and Data?
Andrew | Co-founder, Macaron AI
My talk today is titled The New Scaling Law, focusing on reinforcement learning and experiential data. The big phenomenon we see is that before the end of last year, the most important thing in the industry was Scaling Law — model performance kept improving, loss kept dropping — but this has slowed to some extent. The industry once believed "more parameters, more data, stronger models"; that logic is now hard to sustain.
The Chinchilla paper proved that optimal model parameters scale linearly with training data volume. Human internet data is only 14 trillion tokens by narrow definition, 46 trillion by broad definition, corresponding to optimal model sizes of 500 billion to 1 trillion parameters. Mainstream models like DeepSeek, Ant Ring, and GPT 4.5 have all hit this ceiling. Blindly stacking parameters now yields marginal returns. More critically, these models have reached average human IQ. We've finally left behind the era of "collaborating with intellectually deficient models," laying groundwork for the AI agent explosion.
Of course, Scaling Law slowing isn't the end — it's the beginning for AI agents. We keep facing a question: If we're just doing prompt engineering on top of models, how much value are we really creating? The real breakthrough is using reinforcement learning (RL) to empower model reasoning. On verifiable tasks like math and coding, RL training can boost model performance from 0.2 to 0.8 or even 0.9. The core logic is simple: Find real users in the real world, generate real interactions, get real feedback, and use that feedback as data to feed back through RL and improve the model's reasoning capability. This isn't "leaderboard optimization" but genuine capability building, making agents increasingly useful in specific scenarios.
AI research used to focus on "indirectly useful" tasks: recognizing cats and dogs, playing Go, solving math problems — useful substitutes rather than direct economic value creation, essentially useless in practice. Now the industry has entered the "era of experience." Truly valuable agents must focus on "directly useful" scenarios. Chai, the world's second-largest chatbot company, used user retention data to retrain models last September, continuously improving chat quality. Cursor this year used whether users clicked Tab suggestions as a reward signal, boosting adoption 28% through online RL. Their shared logic: product deployment → real interaction → data feedback → model iteration, forming a closed loop.
On top of this, one problem everyone still hasn't solved but wants to is memory — the biggest bottleneck in research today. Also, multi-agent interaction: the industry once debated single model vs. multi-agent, but the answer is now clear — multi-agent systems show significant advantages across many tasks. Anthropic's multi-agent research system has formed a mature paradigm, and GPT 5's routing design also proves its practicality. Finally, large-scale model application: 30B, 70B parameter small models have lost experimental relevance. Mixture-of-Experts (MoE) technology maturation is gradually making large model training and inference costs controllable. But this also means agent companies need more complex infrastructure, more advanced training techniques, and greater capital investment — the minimum unit cost for RL experiments has surged from $100 to $530,000.
PART 4
How Does a Model Company Iterate Its AI Agent Products?
Feihu Tang | Head of Developer Relations, Moonshot AI
Last November we launched Explorer Edition, with autonomous planning + massive authoritative data retrieval + process reflection at its core. It takes considerable time to run — users might wait dozens of minutes or even hours for a single execution record — but it opened the prototype of agent autonomous exploration; This June we shipped Deep Research, integrating thinking models, supporting multi-tool integration like search-to-slide-deck generation, becoming an early mature deep-research agent; In July we released a high-performance open-source model competitive with top-tier models, focusing on ToB and AGI development; In September we introduced OK Computer, upgrading from "providing information" to "delivering actual products," with more built-in tools capable of directly generating websites and completing complex tasks.

Sustained agent leadership hinges on three hard technical capabilities. For repeated queries on the same contract or fixed programming scenarios, we launched a caching feature solving the pain point of redundant fixed-context calls — related tech has been open-sourced with published papers; The model uses MoE architecture with 1 trillion total parameters and 32 billion active parameters, scaling up training without clipping, with standout performance; We also open-sourced the Window Verify benchmark, addressing performance variance from quantization and precision adjustments across different vendor models, helping downstream ecosystems align quickly.
Our vision extends beyond building a single product to helping users construct an agent ecosystem. We open our models and core technologies for developers to fine-tune for their scenarios — domestic tools like 3K Web coding have already integrated. Many developer peers and other users requested a subscription model; we rushed it out last month, and it's been well-received in overseas communities since launch.
The competitive logic between large model companies and application companies isn't "predation" but "mutual advancement." Whether building models or applications, the endgame is delivering products users are satisfied with. Your product provides better digital signals to optimize your evaluation; once you have a good evaluation system, you can iterate a better model. Application companies are self-developing models; model companies are building products. The ultimate competition is over the combined capability of "product + model + evaluation function."





