Essential SEO for the AI Era | Bolt Recommends

Vercel Research: The Rise of AI Crawlers

The core technology enabling AI to access and retrieve information from the entire internet is: AI crawlers. This technology is rapidly transforming traditional web scraping and content distribution models, becoming an important component of the internet. MERJ and Vercel recently released a research report focusing on the growth trends of AI crawlers in web content collection and their impact on website optimization. The report also analyzes the technical capabilities, content preferences, and limitations of AI crawlers through real-world case studies. At the end of the report, the authors share recommendations for building AI-friendly websites — strategies that make content easier for emerging AI tools to correctly understand and use.
We've organized and translated the authors' research report, hoping to offer some food for thought. The original content can be accessed by clicking the "read more" link.
Part.01
What Are AI Crawlers
According to the latest research from MERJ (a professional data consultancy) and Vercel (a well-known frontend development and deployment platform), AI crawlers (AI web content collectors) have become a significant presence on the web. OpenAI's GPTBot generated 569 million requests on the Vercel network in the past month, while Anthropic's Claude followed closely with 370 million. To put this in perspective: this combined total has reached 20% of Google search engine crawler (Googlebot) requests during the same period, which totaled 4.5 billion. In other words, AI crawlers have already reached one-fifth the scale of traditional search engines.
Previously, we collaborated with MERJ to study how Google's search engine processes JavaScript code in web pages. Now, we've turned our attention to these emerging AI assistants. Through data analysis, we've discovered unique behavioral patterns in how ChatGPT, Claude, and other AI tools access and process web content.
Of particular note, these AI crawlers show distinct characteristics in three key areas that directly determine how AI tools understand and process modern website content:
- JavaScript code processing capability
- Priority selection among different content types
- Web page navigation methods
1) Research Methods and Data Sources
To ensure accuracy and comprehensiveness, we primarily collected two types of data:
1. Core data source: Continuous monitoring data from nextjs.org (the official Next.js website) and the Vercel network
2. Verification data sources: To validate the universality of our findings, we also analyzed two job search websites using different technical architectures:
- Resume Library (built with Next.js)
- CV Library (built with traditional monolithic architecture)
This diverse data collection approach helped ensure our research findings hold value across different types of websites.
Special note: Since Microsoft's Copilot (formerly Bing Chat) does not use a unique identifier, we could not distinguish its behavior in the data, and therefore excluded it from this study.
2) The Scale of AI Crawlers
Let's look at the traffic volume of various crawlers on the Vercel network over the past month:
1. Traditional search engines:
- Googlebot: 4.5 billion (including both Gemini AI and regular search)
2. AI-specific crawlers:
- GPTBot (used by ChatGPT): 569 million
- Claude: 370 million
- AppleBot: 314 million
- PerplexityBot: 24.4 million
While individual AI crawlers don't yet match Google in scale, their combined total is already considerable: all AI crawlers together reached approximately 1.3 billion requests, accounting for over 28% of Googlebot traffic. This impressive figure shows that AI crawlers are becoming a force to be reckoned with in the web ecosystem.
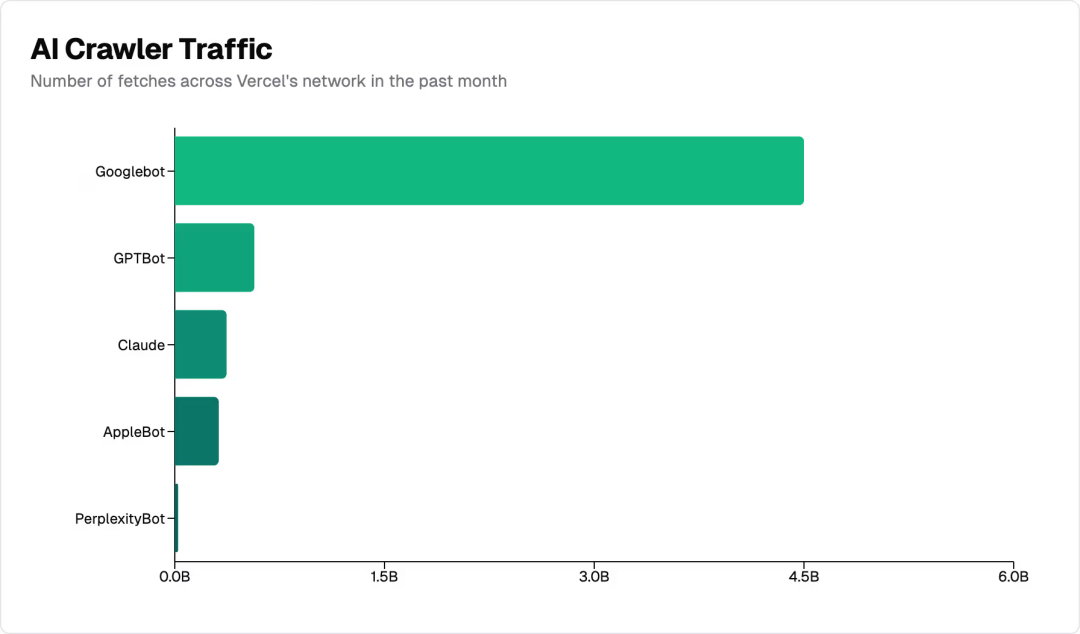
Figure | Traffic volume of various crawlers
3) Geographic Distribution of AI Crawlers
Regarding geographic distribution, we found an interesting phenomenon: AI crawlers are concentrated in just a few US data centers:
- ChatGPT: Located in Des Moines, Iowa and Phoenix, Arizona
- Claude: Located in Columbus, Ohio
By comparison, Google's crawlers are more broadly distributed across seven different US locations, including The Dalles, Oregon; Council Bluffs, Iowa; and Moncks Corner, South Carolina.
4) Technical Limitations of AI Crawlers
(1) AI Crawlers Cannot Execute JavaScript Code in Web Pages
In terms of technical capabilities, we focused on studying how various AI crawlers handle JavaScript. The research found that mainstream AI crawlers share a common limitation: they cannot execute JavaScript code in web pages. Specifically:
1. Crawlers unable to execute JavaScript:
- All OpenAI crawlers (including OAI-SearchBot, ChatGPT-User, GPTBot)
- Anthropic's ClaudeBot
- Meta's Meta-ExternalAgent
- ByteDance's Bytespider
- Perplexity's PerplexityBot
2. However, there are some exceptions:
- Google's Gemini: Because it uses Googlebot technology, it can fully run JavaScript
- AppleBot: Uses browser-like technology capable of processing JavaScript, CSS, and Ajax requests
- Common Crawl (CCBot): As a training data collection tool, it does not execute JavaScript
Interestingly, while ChatGPT and Claude's crawlers download JavaScript files (11.50% of ChatGPT's requests are JavaScript files, and Claude reaches 23.84%), they do not execute this code. This means that if website content needs to be displayed through JavaScript, these AI tools cannot see that portion of content.
However, it's worth noting that if a website's initial HTML response contains complete content (such as JSON data or React Server Components), AI models can still understand this content because they can parse data in various formats.
(2) AI Crawlers Have Relatively High Failed Access Rates
Data shows that current AI crawlers exhibit high failed access rates:
- ChatGPT: 34.82% of requests encountered 404 errors (page not found)
- Claude: 34.16% of requests encountered the same issue
- ChatGPT also had 14.36% of requests encounter redirects
Analysis found that beyond the standard robots.txt file, these crawlers frequently attempt to access files under the /static/ directory that no longer exist. This indicates they are not yet sophisticated enough in URL selection and validation.
By comparison, Google performs much better:
- Only 8.22% of requests encountered 404 errors
- Only 1.49% of requests required redirects
This difference shows that Google has invested more effort in optimizing crawler access efficiency.
5) Content Preferences of AI Crawlers
By analyzing nextjs.org access data, we found that different AI crawlers have distinct preferences in content acquisition:
- ChatGPT particularly focuses on HTML content (57.70% of total requests)
- Claude acquires more images (35.17% of total requests)
- Both acquire substantial amounts of JavaScript files (ChatGPT: 11.50%, Claude: 23.84%), despite not executing this code
By comparison, Google's crawlers (including Gemini) show more balanced behavior:
- HTML content: 31.00%
- JSON data: 29.34%
- Plain text: 20.77%
- JavaScript: 15.25%
These differences may reflect different companies' technical strategies: Google has developed mature content collection strategies over years of development, while emerging AI companies may still be exploring optimal content acquisition methods.
6) Similarities and Differences Between AI Crawlers and Traditional Search Engines
Based on nextjs.org data, we found that current AI crawler behavior exhibits the following patterns:
1. Following popularity: Pages with high organic traffic are more likely to attract crawler attention.
2. Less intelligent: They show less consistent patterns when selecting which URLs to visit.
3. Need optimization: The high failure rates of AI crawlers indicate their URL selection strategies still need improvement.
This stands in stark contrast to traditional search engines: search engines have developed complex algorithms to determine access priority, while AI crawlers are still in their infancy in this regard.
"Our research shows that despite the rapid development of AI crawlers, they still face many challenges in processing dynamic web content. As AI technology continues to transform the web, businesses need to ensure their websites can be understood by both traditional search engines and AI tools. This requires websites to adopt technologies such as server-side rendering to ensure core content is easily accessible and comprehensible."
— Ryan Siddle, Managing Director of MERJ
Part.02
Website Optimization Strategies
1) For Website Owners Who Want to Be Crawled
- Render core content server-side. Since ChatGPT and Claude do not execute JavaScript, any important content should be server-rendered. This includes main content (articles, product information, documentation), meta information (titles, descriptions, categories), and navigation structure. You can use: SSR (Server-Side Rendering), ISR (Incremental Static Regeneration), SSG (Static Site Generation). These technologies ensure all visitors (including AI) can see complete content.
- Use client-side rendering for secondary features. Feel free to use client-side rendering for non-essential dynamic elements such as view counters, interactive UI enhancements, live chat widgets, and social media feeds.
- Maintain clear and stable URL structures. Given the high failed access rates of AI crawlers, all website builders should maintain redirect rules, update sitemaps promptly, and use simple, consistent URL naming conventions.
2) For Website Owners Who Do Not Want to Be Crawled
- Make good use of
robots.txtfiles. The robots.txt file can effectively control various crawlers' access permissions. Set specific rules for AI crawlers by specifying particular user agents or product tokens, restricting access to sensitive or non-essential content. To find the user agents to disallow, you'll need to check each product's technical documentation (for example, Applebot and OpenAI's crawler documentation). - Use Vercel's website firewall. Vercel provides a convenient "Block AI Bots" feature that automatically identifies various AI crawlers with one click, allowing flexible control of access permissions and protection of website resources.
3) For Users of AI Tools
- You may not see dynamic content. JavaScript-rendered content may be missing. Since ChatGPT and Claude do not execute JavaScript, their responses about dynamic web applications may be incomplete or outdated.
- Be cautious about information sources provided by AI. The high 404 rate of up to 34% means that when AI tools cite specific web pages, these URLs have a significant chance of being incorrect or inaccessible. For critical information, always verify sources directly rather than relying on links provided by AI.
- Content updates may not be timely. Except for Gemini, other AI tools show unclear crawling patterns, and some may reference older cached data. Even when asking AI to fetch the latest content, you may not see real-time crawling records.
Here's an interesting example: when we ask ChatGPT or Claude to query the latest Next.js documentation, we usually don't see immediate access records in nextjs.org's server logs. This suggests these AI tools are likely using already cached data, even when they claim to be fetching the latest information.
Part.03
Summary
The rise of AI crawlers represents an important technological inflection point. Currently, they already generate nearly one billion requests per month on the Vercel network, and this number continues to grow. While their technical capabilities are not yet as mature as traditional search engines, they are changing how we access and process web information.
For website developers, the key is to ensure: 1) core content is easily accessible, 2) appropriate rendering strategies are adopted, 3) website structure is optimized, and 4) content accessibility is prioritized. This not only improves website performance in search engines but also ensures website content can be correctly understood and used by emerging AI tools.
📮 Further Reading



Linear Bolt Bolt is an investment initiative established by Linear Capital specifically for early-stage, global-market-facing AI applications. It upholds Linear's investment philosophy, focusing on projects driven by technological change, with the goal of helping founders find the shortest path to achieving their objectives. Whether in terms of operational speed or investment approach, Bolt's commitment is to be lighter, faster, and more flexible. In the first half of 2024, Bolt has already invested in seven AI application projects including Final Round, Xin Guang, Cathoven, Xbuddy, and Midreal.