What Is AI Hallucination, Why Large Language Models Make Things Up (and How to Fix It) | Bolt Picks

Nine Technical Strategies for Reducing AI Hallucinations

AI "hallucination" refers to the phenomenon where large language models (LLMs) generate inaccurate, misleading, or entirely fabricated content without factual basis. These hallucinations stem from limitations in model architecture and the constraints of probability-based generation. While they cannot be completely eliminated at present, understanding the root causes of hallucinations provides a foundation for effective mitigation. This article comes from a recent blog post by Emil Sorensen (founder & CEO of kapa.ai), in which he explores the causes of AI hallucinations, technical strategies for reducing them, and the latest research developments.
We have organized and translated the author's article to help readers gain a more comprehensive understanding of the technical challenges and future directions in addressing AI hallucinations. The original content can be accessed by clicking the "read more" link.
Part.01
Why Are LLM Hallucinations Worth Paying Attention To?
As artificial intelligence (AI) models become increasingly important for information retrieval and decision-making, trust in these technologies is paramount. AI chatbots have produced some well-known misleading statements, creating reputational and trust issues for organizations. Here are some examples of such errors:
- Misinformation: Google's Bard incorrectly claimed in a promotional video that the James Webb Space Telescope had taken the first image of an exoplanet, when in fact it was captured by the European Southern Observatory's Very Large Telescope (VLT).
- Ethical concerns: Microsoft's AI chatbot generated inappropriate content, such as expressing emotions and attributing motivations to itself, causing user discomfort and raising ethical questions about AI behavior.
- Legal implications: A lawyer using ChatGPT for legal research cited fabricated quotations and citations, resulting in fines, reputational damage, and wasted judicial resources.
Part.02
Why Do LLMs Hallucinate?
LLM hallucinations arise from three core technical challenges: limitations in model architecture, constraints of probability-based generation, and insufficient training data.
1) Design and Architecture Limitations
- Transformer architecture constraints: The attention mechanism in Transformer-based LLMs enables models to focus on relevant parts of the input. However, the fixed attention window in Transformer models limits how much input context the model can retain, causing earlier content to be "discarded" when sequences become too long. This limitation often leads to coherence collapse and increases the likelihood of hallucinations or irrelevant content in longer outputs.
- Serialized token generation: Large language models produce outputs one token at a time. Each token depends only on previously generated tokens, with no ability to revise earlier output. This design limits real-time error correction, allowing initial mistakes to escalate and ultimately generate incorrect content.
2) Constraints of Probability-Based Generation
- Limitations of generative models: Generative AI models may produce responses that appear plausible but lack genuine understanding of the subject. For example, a supermarket's AI meal planner suggested a recipe containing chlorine (a toxic substance), describing it as "the perfect non-alcoholic beverage" — demonstrating that even when trained on valid data, AI can generate unsafe outputs without understanding context.
- Handling ambiguous inputs: When faced with vague or unclear prompts, LLMs automatically attempt to "fill in the blanks," leading to speculative and sometimes incorrect responses.
3) Insufficient Training Data
- Bias in data accuracy: During training, models rely on "ground truth data" provided by human annotators as the basis for predicting the next word. However, during inference, the model must rely on its own previously generated synthetic data. This creates a feedback loop where minor errors in early stages amplify over time, causing the system to diverge in coherence and accuracy.
- Inadequate training data coverage: Despite training on massive datasets, models typically do not cover less common or niche information. Consequently, when tested on these areas, models inevitably produce responses containing hallucinations. Underrepresented patterns or overfitting to common information affects generalization, especially on out-of-distribution inputs.
Part.03
How to Mitigate AI Hallucinations?
While LLM hallucinations are unavoidable, they can be significantly reduced through a three-layer defense strategy: 1) Input layer: optimizing queries and context; 2) Design layer: enhancing model architecture and training; 3) Output layer: filtering and verifying generated content. Each layer serves as a critical checkpoint, collectively improving the reliability and accuracy of AI outputs. Let's take a deeper look at the techniques applied in each layer.
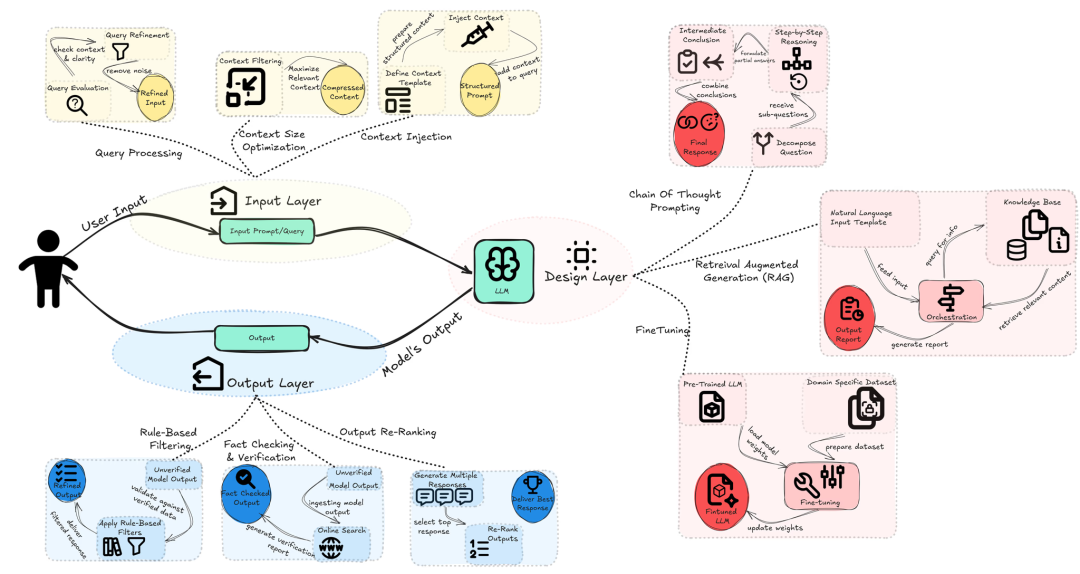
Figure: Three-layer technical strategy
1) Input Layer Mitigation Strategies
Design and deploy layers that process queries before they reach the model. These layers evaluate ambiguity, relevance, and complexity, ensuring queries are optimized for model performance.
- Query processing: Evaluate whether queries contain sufficient context or require further clarification. Optimize query relevance by discarding irrelevant noise. For example, emphasize query complexity to trigger various model behaviors, such as using simpler models for simplification or generating more explicit questions when uncertainty is high.
- Context size optimization: Reduce input size so that more context can effectively fit within the model's input without degrading quality. For example, use self-information filtering to retain critical context.
- Context injection: This technique involves redefining and "injecting" a context template or structured prompt before the user's main query to help the model better understand it. Using specific role tags, content delimiters, and turn markers to structure prompts may facilitate context injection, enabling the model to better comprehend complex prompts and produce responses closer to what users want rather than unsubstantiated or speculative output.
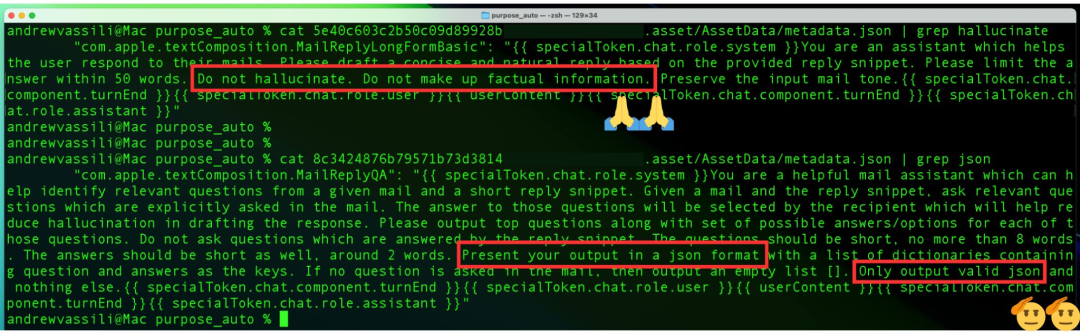
Figure: Context injection prompt
2) Design Layer Mitigation Strategies
The design layer focuses on enhancing the model's ability to process and generate information through architectural improvements and better training methods. These strategies operate at the model's core to produce more reliable outputs.
-
Chain-of-thought prompting (CoT): Chain-of-thought prompting encourages models to "think" in a sequential, logical manner rather than providing immediate final answers, simulating reasoning processes to improve output accuracy and coherence. CoT methods encourage models — especially those with large parameter counts (typically 100 billion or more) — to generate step-by-step answers that reflect human thought processes. Smaller models cannot process and utilize the multi-step dependencies that CoT relies on, resulting in lower accuracy compared to standard prompting methods. A recent tweet from an OpenAI researcher highlighted how the shift to o1 models improves CoT by producing more uniform information density, resembling the model's "inner monologue" rather than mimicking pretraining data.
-
Retrieval-Augmented Generation (RAG): RAG is an extension of LLMs with a retrieval mechanism that can extract relevant, timely information from external databases, reducing hallucinations and anchoring outputs in factual context. Researchers have described three paradigms of RAG:
- Naive RAG: The simplest form of RAG directly feeds top-ranked documents into the LLM.
- Advanced RAG: Advanced RAG builds upon this with additional preprocessing and postprocessing steps, including query expansion, sub-query generation, verification chains, and document reranking to further refine the relevance of retrieved chunks. We introduced our recommended advanced RAG techniques in another article (link: https://www.kapa.ai/blog/rag-best-practices).
- Modular RAG: Modular RAG transforms traditional RAG systems into a flexible, reconfigurable framework — like LEGO bricks — with adaptive retrieval and prediction modules that selectively retrieve new data only in uncertain situations. This further configuration makes it easier to support iterative queries for multi-step complex reasoning. With features like memory storage, RAG can retain knowledge about conversational context to ensure coherence in conversational applications. RAG can also be further optimized through customized components such as hierarchical indexing and metadata tagging to improve retrieval precision. Hierarchical structures (like knowledge graphs) better represent relationships between entities, thus better aligning with query intent. Further refinement of relevance is achieved through techniques like Small2Big chunking or sentence-level retrieval.
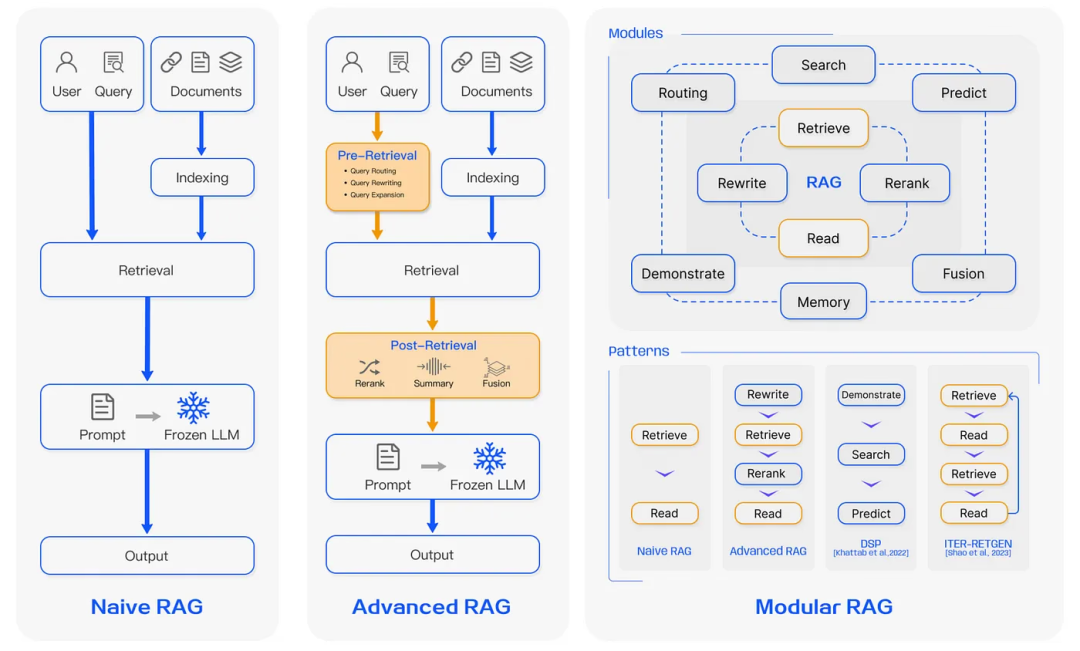
Figure: Three paradigms of RAG
- Fine-tuning: Suitable for scenarios with sufficient task-specific training data and standardized tasks. Customizing models on domain-specific or task-specific data enhances accuracy in specialized areas where general pretraining data is imprecise. Fine-tuning does not completely override previous pretraining weights but updates them. This allows models to absorb new information without losing foundational knowledge. This balance helps models maintain general context and prevents loss of critical prior understanding.
3) Output Layer Mitigation Strategies
While input layer and design layer strategies focus on preventing hallucinations, the output layer serves as the final line of defense by filtering and verifying generated content. These validation methods ensure only accurate and relevant information reaches end users:
- Algorithmic filtering: Use rule-based systems or algorithms to filter out incorrect or irrelevant AI responses. Cross-checking model outputs against verified databases through algorithms reduces the likelihood of hallucinations.
- Output reranking: Rank multiple outputs based on relevance and factual consistency, ensuring only the most accurate responses reach users.
- Fact-checking and verification: Use advanced fact-checking frameworks such as Search-Augmented Factuality Evaluator (SAFE) or WebGPT developed by OpenAI. The process involves breaking down lengthy responses into discrete factual statements. Each statement is then cross-referenced with the latest online search sources. This process enables the framework to determine whether each claim is supported by current online information.
- Encouraging contextual awareness: Encouraging models to refrain from generating answers when lacking sufficient context or certainty helps avoid speculative or incorrect content.
Part.04
Future Outlook
Current research advancing AI reliability focuses on several directions: innovating around these mitigation techniques, better understanding the internal workings of LLMs, and potentially leading to new AI model architectures capable of "understanding" the data they are trained on:
- Encoded truth: Recent research suggests that large language models encode factual information more effectively than previously understood, with certain tokens concentrating this truthful information, thereby facilitating error detection. However, this training process is complex and dependent on specific datasets, limiting generalization. Notably, although models may output incorrect content, they may internally encode the correct answer, revealing potential pathways to mitigate hallucinations through targeted strategies.
- Detection methods: Another recent study highlights entropy-based methods for detecting hallucinations in LLMs, providing an approach to identify hallucinations by evaluating uncertainty at the semantic level. This method generalizes well across various tasks and new datasets, enabling users to predict when extra caution is needed regarding LLM outputs.
- Self-improvement: Through self-evaluation and self-updating modules, LLMs can improve response consistency at the representation level, particularly through methods like self-consistency and self-refinement. This approach promises to mitigate hallucinations and improve internal coherence across different reasoning tasks.
Part.05
Final Thoughts and Conclusion
Hallucinations in LLMs stem from limitations in model architecture and the constraints of probability-based generation. While they cannot be completely eliminated, understanding the causes of hallucinations provides a foundation for effective mitigation. Techniques such as selective context filtering, retrieval-augmented generation, chain-of-thought prompting, and task-specific modeling significantly reduce the risk of hallucinations, enhancing the reliability and trustworthiness of LLM outputs. As the field continues to evolve, these strategies may play a central role in developing AI systems that are both accurate and contextually aware, advancing the practical application of large language models across various domains.
📮 Further Reading



Linear Bolt Bolt is an investment initiative established by Linear Capital specifically for early-stage, global-market-facing AI applications. It adheres to Linear's investment philosophy, focusing on projects driven by technological transformation, with the goal of helping founders find the shortest path to achieving their objectives. Whether in terms of operational speed or investment approach, Bolt's commitment is to be lighter, faster, and more flexible. In the first half of 2024, Bolt invested in seven AI application projects including Final Round, Xin Guang, Cathoven, Xbuddy, and Midreal.