Bolt Perspective | How Do We Measure (General) Artificial Intelligence?

One of Zapier's cofounders, Mike Knoop, recently launched a challenge called the ARC Prize on Kaggle, the well-known AI competition community. On the challenge's homepage, these words appear: "Progress toward artificial general intelligence (AGI) has stalled. We need new ideas."
Mike Knoop, one of the co-founders of Zapier, recently launched a challenge called ARC Prize on Kaggle, the well-known AI competition community. On the challenge's homepage, these words appear: "Progress toward AGI has stalled. We need new ideas."
At a time when AI and large language models are dominating headlines, this statement sounds strange. But to discuss this proposition, we need to first address a more fundamental question: What is intelligence, and how do we measure it?
Let's start with the ARC Prize's origins to explain what it actually is. ARC Prize traces back to a 2019 paper titled "On Measuring Intelligence," authored by Francois Chollet — best known as the creator of Keras, one of the most widely used machine learning frameworks, and also a co-founder of this challenge. In the paper, Chollet summarized past definitions and metrics of intelligence and offered his own perspective:
Evaluating skill alone cannot move us forward in the pursuit of intelligence. Therefore we need new evaluation criteria. These criteria must strictly constrain prior knowledge, experience, and generalization difficulty.
The first half echoes criticisms of deep learning's inability to generalize. But the point remains true today — even when evaluating composite skills like writing or painting. We can always sample from a skill's problem space to train intelligent systems. We can optimize under such evaluation frameworks, but the resulting systems fail to generalize.
The paper presents a complete framework for quantitatively evaluating intelligence on tasks with specific constraints around prior knowledge, experience, and generalization difficulty. It concludes with a benchmark called ARC. As the author describes, this benchmark provides highly abstract tasks with only a few examples (and no way to mechanically generate more), thereby measuring generalization. Moreover, simply memorizing the training set is useless for test performance. This ARC Prize is built directly on that benchmark.
Below is an example ARC problem:
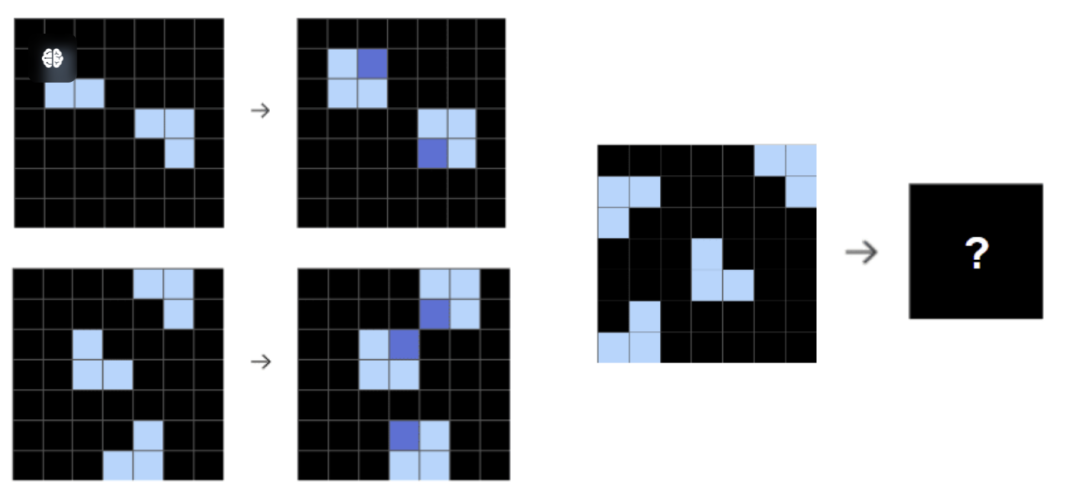
An ARC example: based on the two examples on the left, complete the pattern with the question mark on the right
As you can see, ARC isn't difficult for humans. In fact, ordinary people achieve roughly 85% accuracy on the public training set (the evaluation test set is harder than the training set, typically scoring 10% lower, so while there's no formal statistic, we can estimate humans would reach about 75%). But ARC is far from easy for AI. Chollet launched an ARC challenge four years ago. The winning algorithm in that competition achieved 21% accuracy on the test set. According to the organizers, the best AI result prior to this challenge was 34%. Looking at the current challenge leaderboard, the top score is 39%.
We naturally ask: how do today's large models perform on this challenge? Unfortunately, the standard ARC challenge prohibits internet access, which relates to Kaggle's competition format — ensuring the confidential private test set doesn't leak. But recently, Ryan Greenblatt, a researcher at Redwood Research, achieved 50% accuracy on the public test set (roughly equivalent in difficulty to the private test set) using GPT-4o, the current AI best. Because of this result, even though testing on the private set wasn't possible, the competition organizers prepared an additional semi-public test set that had never been seen before; the algorithm reached 43% accuracy on this set.
The author dedicated a blog post to explaining his method. It's not particularly complicated, roughly divided into several steps:
-
Have GPT-4o generate 5,000 different Python code solutions for each problem
-
From the first step's outputs, select the 12 best candidate codes, then have GPT-4o optimize them again, generating 3,000 different optimized code versions.
Finally, on the test set, have all solutions that answered correctly on the training set provide answers, and submit the answer with the highest vote count.
Of course, there are many details in this approach, and the author discussed them quite openly — I won't recount them all here, but interested readers can check the original post (linked at the end).
What does this result tell us?
-
First, ARC is genuinely fascinating as a metric. Considering this paper was published three years before ChatGPT, its value feels almost timeless. In my view, compared to many other benchmarks, ARC successfully identifies the largest gap between AI and "intelligence." On one hand, no AI has passed the threshold in five years — let alone compared to humans. On the other hand, this benchmark requires virtually no prior knowledge. Unlike programming challenges (e.g., SWE-Bench), which are equally difficult, ARC tests intelligence more purely, without requiring skill.
-
Let's first answer a qualitative question: Do LLMs have intelligence at all? We can assume LLMs have no prior knowledge of ARC (which is part of ARC's elegance), so this question becomes nearly equivalent to: "Did the LLM learn anything from the prompt (examples and instructions)?" The answer is yes. Although the final answer comes from massive voting, if none of the candidate algorithms contributed anything, such strong results would be impossible. This answer is far from obvious. I suspect large models represent the first time we can solve ARC problems through AI rather than symbolic algorithms.
-
The next question is more specific: How strong is LLM learning ability? This is considerably more complex than the previous question. Clearly LLMs aren't strong enough — otherwise we wouldn't need massive candidate algorithms and voting. For a more quantitative answer, we can look for clues. Ryan, like a typical Kaggle competitor, described in detail how he gradually expanded his solution pool and the results at each step. Most worth noting is that with only 1,000 candidate algorithms initially, the approach achieved 25% accuracy. Roughly speaking, we can consider this the result of 1,000 GPTs brainstorming together.
What if we used just one GPT? The organizers thoughtfully tested direct problem-solving with mainstream large models when releasing the semi-public test set. Results shown below: Claude 3.5 scored 14%, leading the pack; GPT-4o and Gemini 1.5 scored 5% and 4.5% respectively. This can serve as a reference for today's model intelligence (compared to humans' estimated 75% on the public test set). I didn't examine the organizers' testing procedure, but I suspect there's still room for improvement — better input formats and more detailed instructions. According to Ryan, his problem-solving prompt reached roughly 30K tokens.
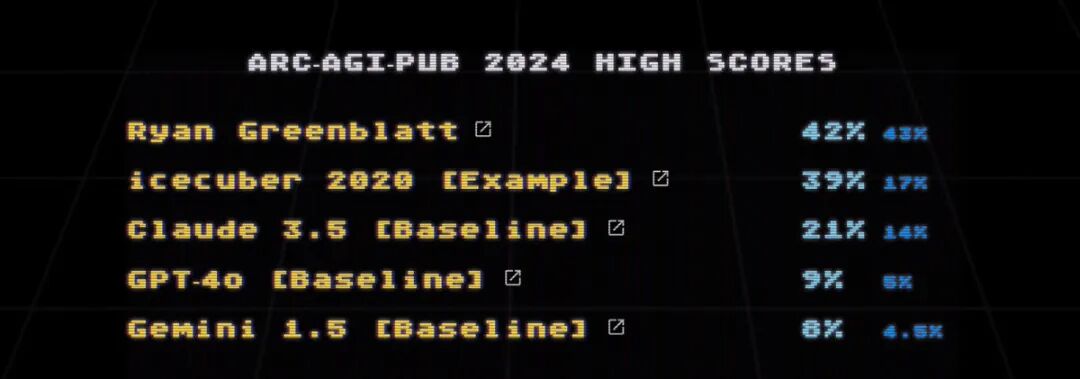
Semi-public test set leaderboard (including mainstream large models)
So, if we use ARC to measure large model intelligence, we can roughly place it between these two lines. GPT-4o, for instance, falls between 5% and 25%. Finally, looking at this leaderboard, Claude 3.5's performance is simply stunning.
- Another revelation: intelligence can emerge from systems, not just models. In fact, with MoE and other technologies, there was never a clear dividing line between models and systems anyway. Kaggle veterans know the value of ensemble models, but Ryan's approach reminds us again that we can obtain "intelligence" by cleverly combining massive numbers of large models. In fact, as he gradually increased his sample size, scores showed an almost perfect exponential relationship with sample size. If this exponential relationship holds at higher score ranges, then ignoring cost, with just 2 million candidate algorithms, machines could reach 70% accuracy — roughly human-level. On the frontier of intelligence exploration, cost is always the last thing we consider. This approach could also apply to other scenarios requiring genuine intelligence where cost can be ignored (military applications, perhaps?)
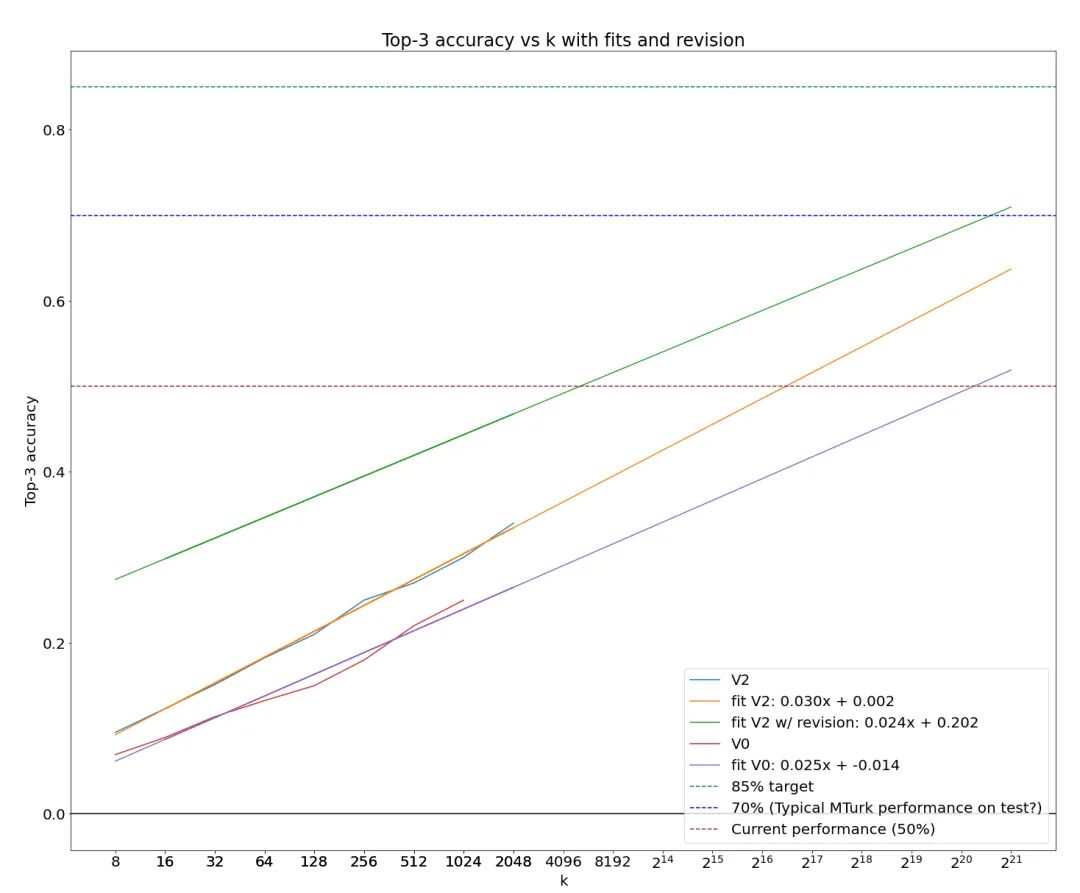
The perfect exponential relationship between sample size and score
Closing Thoughts
Of course, ARC is not a general intelligence test. Achieving or surpassing human-level performance on ARC doesn't mean we've reached AGI. But it's a valuable exploration, seeking out the most glaring gap between AI and humans. If we can't solve ARC, we certainly haven't reached AGI. From this perspective, anyone interested in measuring intelligence should check out Francois Chollet's 2019 paper.
Moreover, we are genuinely making continuous progress toward general intelligence. Even today the gap still looks vast, but at least we see a glimmer of light — this unstoppable progress feels both thrilling and tense. Historically, the journey from 1 to 100 is not only much faster than from 0 to 1, but often far exceeds our predictions. As we continue exploring this path, better benchmarks will certainly emerge, greatly accelerating improvements in system capabilities. If you're interested in general intelligence or how to measure it, welcome to discuss with us (my WeChat: Can_Zheng).
Bolt Community
If you're an explorer of the AI wave who shares Bolt's perspective, and hope to discuss with like-minded peers, welcome to scan the QR code below to briefly introduce yourself. After review, you'll be invited to join the discussion.
PS: Cover image generated by ChatGPT
Linear Bolt Bolt is an investment initiative established by Linear Capital specifically for early-stage, global-market-facing AI applications. It upholds Linear's investment philosophy and principles, focusing on projects driven by technological transformation. Bolt aims to help founders find the shortest path to their goals — whether in speed of execution or investment approach, Bolt's commitment is lighter, faster, and more flexible.