Coconut by Meta AI: Using Continuous Chains of Thought for Better LLM Reasoning | Bolt Picks

Better Reasoning, Fewer Tokens

Meta's research team recently published a paper introducing an innovative approach called Coconut (Chain of Continuous Thought), which enables LLMs to conduct their reasoning processes in latent space, free from the constraints of word-based inference. Experiments show that Coconut significantly enhances LLM reasoning capabilities. Additionally, latent space reasoning reduces token consumption and allows models to perform better on planning-intensive tasks. This opens up promising new directions for the field of natural language processing (NLP). AI Papers Academy distilled the paper's key points, covering Coconut's research background, training methodology, and experimental results, which we have translated and organized. The original AI Paper Academy article can be accessed via the "read more" link.
Original paper PDF: https://arxiv.org/pdf/2412.06769
Large language models (LLMs) have demonstrated remarkable reasoning capabilities and are increasingly permeating every corner of our lives. These models acquire such abilities through pre-training on vast amounts of human language. One common and powerful method for extracting the most accurate responses from these models is known as Chain-of-Thought (CoT), where we encourage the model to generate solutions step-by-step, providing a reasoning process that leads to the final answer. However, LLM reasoning must be generated in the form of words, which imposes a fundamental constraint on the model.
Neuroimaging studies have shown that during reasoning tasks, the regions of the human brain responsible for language comprehension and production remain largely inactive. This suggests that language is optimized for communication, not necessarily for complex problem-solving. If humans don't always translate thoughts into words during reasoning, why should artificial intelligence?
In this article, we will delve into Meta's paper, titled "Training Large Language Models to Reason in a Continuous Latent Space." The paper aims to free LLMs from the constraints of word-based reasoning through a new method called Coconut (Chain of Continuous Thought).
 Figure | Paper authors and title
Figure | Paper authors and title
Part.01
CoT vs. Continuous Thought Chain (Coconut)
The image below from the paper compares the Chain-of-Thought (CoT) method with the Continuous Thought Chain (Coconut) method. We can use this figure to gain a deeper understanding of how the continuous thought chain method works.
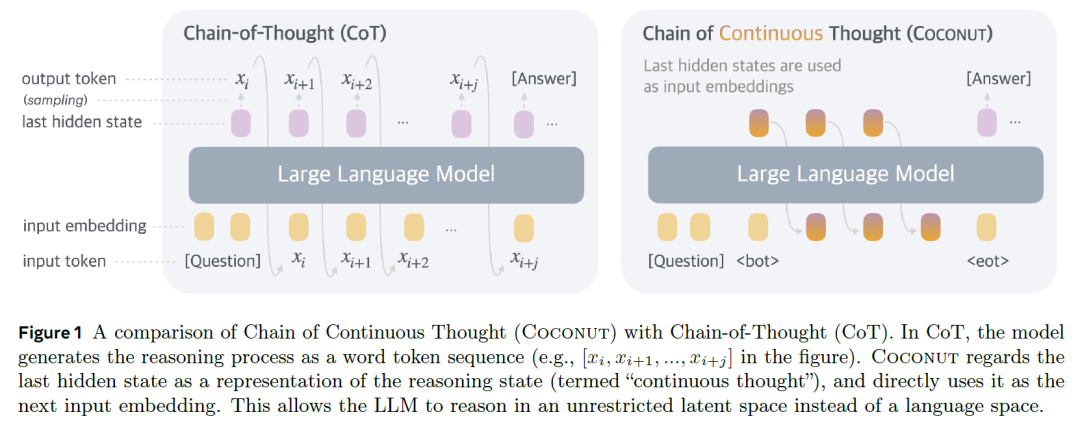 Figure | Comparison of CoT and Coconut method workflows
Figure | Comparison of CoT and Coconut method workflows
Chain-of-Thought (CoT) Method On the left side of the figure above, we can see a schematic of how the CoT method works. The workflow can be broken down into the following key steps:
-
Initial input processing: The system first receives the problem input and converts it into input tokens fed into the large language model (LLM).
-
Reasoning process initiation: The model generates the first token of its response, marking the beginning of the reasoning process. This token comes from the model's last hidden state — the output of the final layer of the backbone Transformer network. The hidden state contains the model's high-dimensional representation of the input information, providing a foundation for subsequent reasoning.
-
Iterative reasoning process: The system performs multiple forward passes, each time using the problem and the currently accumulated reasoning process tokens as input. This iterative approach allows the model to gradually build a complete reasoning chain, with each step based on previous reasoning results.
-
Generating the final answer: Once the model has completed the full reasoning process, the system continues with forward passes to generate the final answer.
The key characteristic of the CoT method is that it expresses the reasoning process through explicit sequences of language tokens, with each reasoning step transformed into an interpretable linguistic form. While this approach is intuitive and easy to understand, it is limited by the discrete nature of linguistic expression — precisely the constraint that the subsequent Coconut method attempts to overcome.
Continuous Thought Chain (Coconut) Method The core innovation of the Coconut method lies in introducing a dual-mode operating mechanism that allows the model to flexibly switch between language mode and latent thought mode. This design breaks through the limitation of traditional methods that rely solely on language tokens for reasoning.
The model operates in two modes as follows:
-
Language mode: In this mode, the model functions as a standard language model, generating the next token in the conventional manner. This mode is primarily used for outputting final results.
-
Latent thought mode: In this mode, the model leverages hidden states to reason directly in continuous latent space. This approach avoids the constraint of converting thought processes into discrete tokens, making reasoning more flexible and efficient.
Coconut Method Workflow:
-
Initialization phase: The input question is appended with a special start token
to mark the beginning of latent thought mode. The model processes the input and generates hidden state representations. -
Latent thought mode phase: Unlike CoT, which generates concrete token sequences, Coconut directly uses the model's last hidden state as the thought representation. These hidden states are directly used as input embeddings for the next step, forming a continuous chain of thought that reasons in latent space.
-
Transition phase: A special end token
marks the end of latent thought mode, and the system switches back to language mode to begin generating the final answer.
The main innovation of the Coconut method is that it allows the model to reason in continuous latent space. Compared to traditional discrete token sequences, this approach can more naturally express complex thought processes, reduces information loss from linguistic expression, and provides the model with a more flexible reasoning space.
Part.02
Coconut Training Process
Now let's introduce the training process for the continuous thought chain method. This process aims to teach large language models how to reason in continuous latent space. We will use the figure from the paper below, which illustrates the various stages of the training process.
 Figure | Continuous thought chain multi-stage training process
Figure | Continuous thought chain multi-stage training process
The researchers utilized existing linguistic chain-of-thought as training data for the model, similar to the Chain of Thought (CoT) format, where each sample contains a Question, reasoning steps (Step 1, Step 2, ...), and a final Answer.
The training process is divided into multiple stages (Stage 0, Stage 1, Stage 2, ...), with each stage gradually introducing more continuous thoughts ([Thought]) and removing one concrete reasoning step (Step). In Stage 0, no continuous thoughts are introduced in the training data; the model is trained directly with the original reasoning steps and answers. In subsequent stages, each stage removes one reasoning step from the sample and replaces it with a continuous thought [Thought]. In the final stage, all reasoning steps are replaced with continuous thoughts [Thought], with only the answer portion used for loss calculation.
Coconut's training objective is to gradually introduce [Thought] in language reasoning tasks, thereby enabling the model to acquire "continuous thought" capabilities. The staged training approach allows the model to gradually adapt to more complex reasoning tasks, avoiding the difficulty of directly learning a complete reasoning chain.
Part.03
Switching from Latent Thought Mode to Language Mode
How does the model determine when to switch from latent thought mode to language mode? The researchers explored two strategies:
-
Using a binary classifier to judge latent thoughts and make the decision
-
Using a fixed number of latent thoughts
Since both strategies yielded similar results, the researchers ultimately chose to use a fixed number of latent thoughts for experiments, for the sake of simplicity.
Part.04
Experimental Results
Now let's review some results shown in Table 1 from the paper, which compares the Coconut method with several baseline methods across three datasets: GSM8K (math problems), ProntoQA (logical reasoning), and ProsQA (a dataset constructed for evaluating the Coconut method, designed to assess the model's planning capabilities).
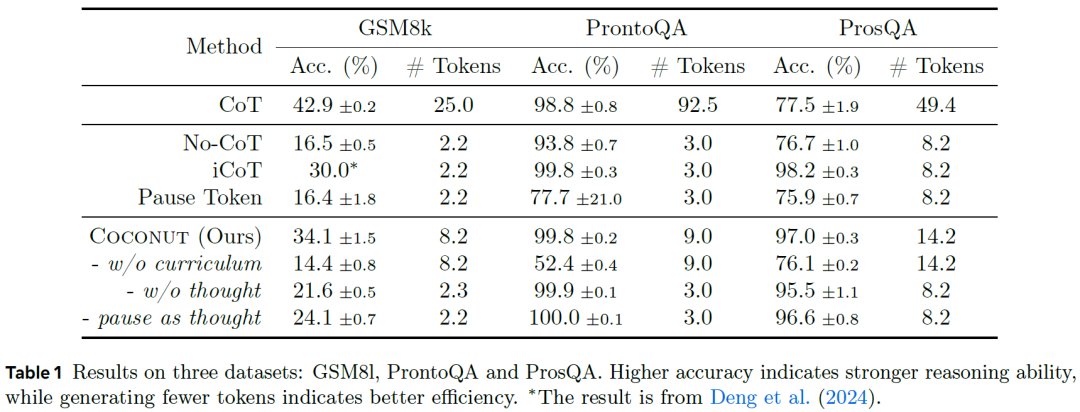 Figure | Continuous thought chain experimental results
Figure | Continuous thought chain experimental results
First, comparing Coconut results with No-CoT (an LLM version that directly generates answers without chain-of-thought reasoning), we can see that conducting continuous thought in latent space significantly improves reasoning capabilities, as Coconut performs markedly better across all three datasets.
Compared with CoT, we find that CoT performs better on math problems, but Coconut is significantly superior on ProsQA, which requires strong planning capabilities (we will delve deeper into this shortly). Notably, CoT requires generating more tokens compared to Coconut, making Coconut more efficient.
Another baseline method, i-CoT, also attempts to internalize the reasoning process in a different way. We can see that Coconut achieves better accuracy on math problems while performing comparably on the other two datasets.
An interesting result in this study is the experiment labeled "w/o curriculum." This version of the model was trained using only samples from the final training stage (Stage N), which contain only questions and answers, requiring the model to solve entire problems using continuous thought alone. The results show that this version scored significantly lower. Through this, we can better understand the importance of multi-stage training.
Part.05
BFS-Style Reasoning
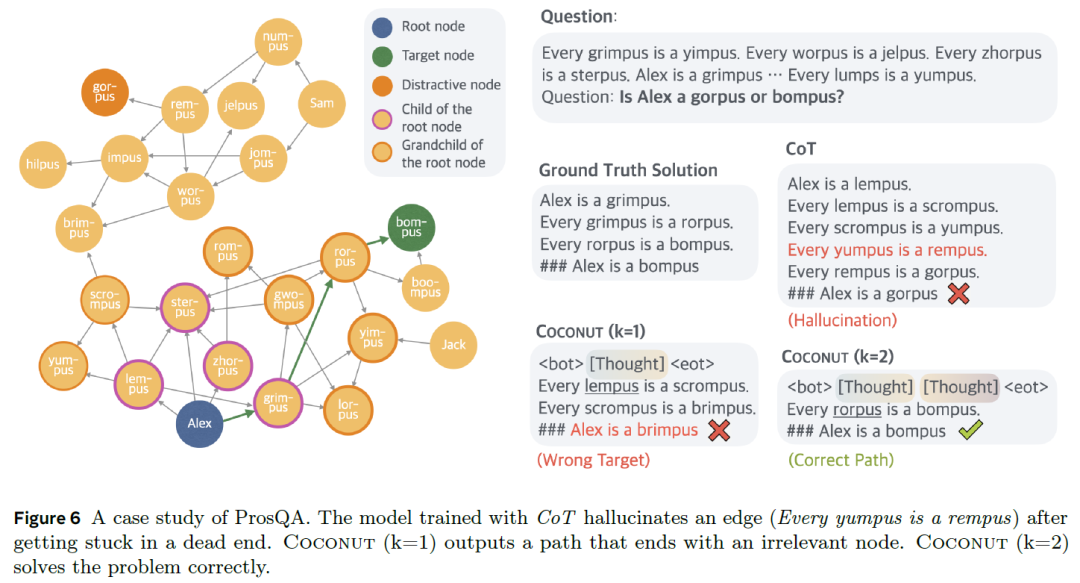
Figure | Example demonstrating Coconut's BFS-style reasoning capability
An interesting observation from the experimental results is the benefit of latent reasoning for planning-intensive tasks. All model versions using some form of latent reasoning outperformed CoT on the ProsQA dataset, which requires more complex planning compared to the other two datasets.
Let's understand this through a case study from the ProsQA dataset. In the figure, we can see:
- The upper right [Question] shows how various internal relationships are established and asks about the connections that can be derived from these relationships
- The left side displays a graph constructed from the relationships defined in the problem
The problem designed by the authors asks the model to determine whether Alex is a gorpus or a bompus. Test results show that the model requires two steps of reasoning to arrive at the correct answer, bompus. The specific approach is to perform a graph search from the Alex node, reaching the target node bompus within two steps, thereby deriving the correct answer.
Using standard chain-of-thought reasoning, the model generated something that doesn't exist in the relationship network, leading to an incorrect answer. We also observed that Coconut with one [Thought] yielded an incorrect result, but with two [Thoughts], the model arrived at the correct answer. One possible explanation is that Coconut allows the model to explore multiple possible branches before determining a specific path, a capability somewhat analogous to Breadth-First Search (BFS).
Part.06
Conclusion and Future Research Directions
Let's summarize the main findings and explore several possible future research directions. First, the Coconut method significantly enhances LLM reasoning capabilities. We saw this when comparing results with the No-CoT version. Second, latent space reasoning enables the model to develop BFS-like reasoning patterns, which helps it perform better on planning-intensive tasks.
Looking ahead, there are several interesting research directions. One possible direction is to pre-train large language models with continuous thought, rather than starting from standard pre-trained models. Another direction is to optimize Coconut's efficiency to better handle the sequential nature of multiple forward passes. Finally, combining latent thought with standard chain-of-thought, rather than replacing it, might allow capturing the advantages of both methods simultaneously, though this would require more reasoning steps.
📮 Further Reading



Linear Bolt Bolt is an investment initiative established by Linear Capital specifically for early-stage, global-market-facing AI applications. It adheres to Linear Capital's investment philosophy, focusing on projects where technology-driven transformation creates change, with the goal of helping founders find the shortest path to achieving their objectives. Whether in terms of execution speed or investment approach, Bolt's commitment is to be lighter, faster, and more flexible. In the first half of 2024, Bolt invested in seven AI application projects including Final Round, Xin Guang, Cathoven, Xbuddy, and Midreal.