Data Is the Model: A Look at Recently Released Small Models

When costs are fixed, data quality determines model quality.

Large language models seem to be at a delicate moment. The leading frontier models are roughly comparable in capability, and there's considerable anticipation for breakthroughs in the next generation. But taking capability up another notch requires either an architectural breakthrough or costs rising by at least an order of magnitude — neither is easy, giving things a faint sense of "should be here by now." A few weeks ago, we saw a flurry of small model releases, reflecting intensive data augmentation efforts that may represent, in some sense, an alternative path for improving model capability while reducing costs.
Starting with Scaling Laws
The steady improvement in today's large models owes much to Scaling Laws. Their elegance lies in how little we need to do — no new architectures required, just money and data, and model capability keeps climbing.
But the relationship between model capability and data is a power law, meaning the data required grows ever larger. Setting aside the perennial concern of "when will large models run out of human data," making this power law more economical is itself a multi-billion-dollar question. Moreover, not all data contributes equally to model capability. Until the next major architectural leap, a model's data efficiency (performance per token trained) depends heavily on data quality. When costs are fixed, data quality determines model quality.
Hugging Face SmolLM
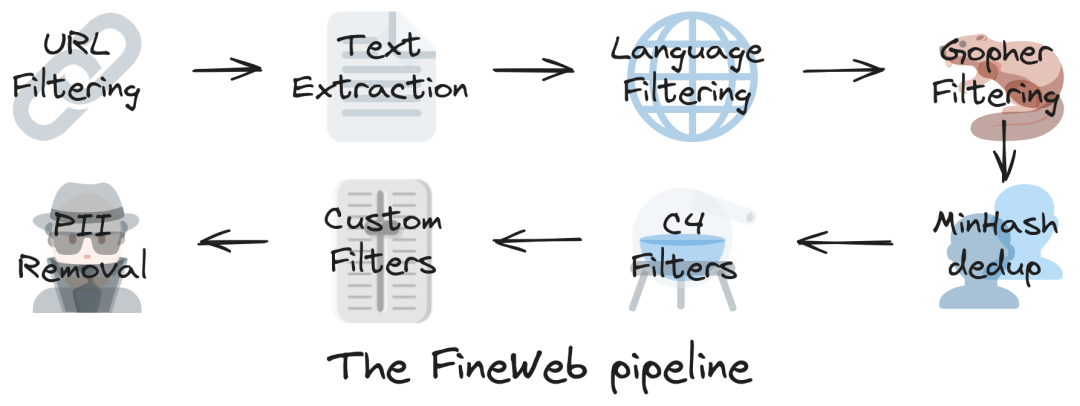
A few weeks ago, Hugging Face released a series of small models called SmolLM, all under 1 billion parameters, requiring only a few gigabytes of memory to run on a phone. A major highlight of this series is its training efficiency. The release data shows that SmolLM 135M/360M/1.7B achieved roughly state-of-the-art performance among comparable models while consuming far fewer training tokens — primarily due to the datasets used. The original SmolLM release details the dataset composition, including FineWeb (currently the best-performing open-source data for model training) and Cosmopedia v2 (the largest synthetic dataset for pretraining to date). A close look at how each dataset component was constructed and optimized reveals extensive use of large models for filtering or generating data.
Apple DCLM
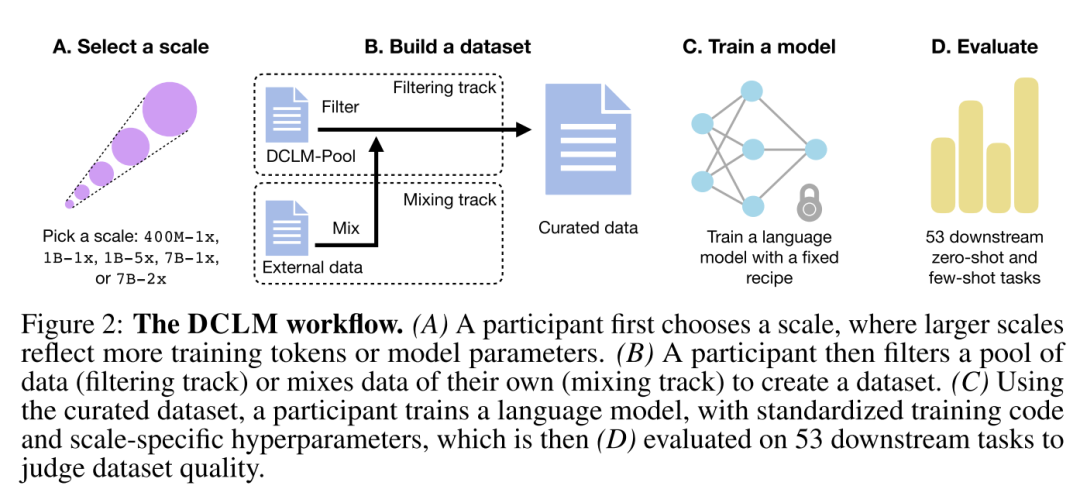
Similarly, Apple recently released a small model, DCLM-7B, from a comparable angle. The DCLM project focuses on building a dataset optimization platform. The DCLM-7B model released this time was trained on DCLM-Baseline data primarily to validate this platform's effectiveness. The training results show the DCLM dataset performs exceptionally well. DCLM-7B used 2.6 trillion training tokens to reach 64% on MMLU, roughly on par with Llama 3 8B or Mistral-7B-v0.3 — with less than one-sixth the training data of Llama 3 8B.
Large Models + Small Models: The Data Augmentation Flywheel
From the work on SmolLM and DCLM, we can see a very clear idea: high-quality data equals high-quality models. And there's already a rigorous data optimization methodology behind this.
- Use existing large models to provide synthetic data, including direct generation or filtering
- For different choices at each step, hold other steps constant and train small models on sampled data for rapid comparative validation
- Note that selecting appropriate criteria for comparing small models is crucial: stability (not affected by small sample sizes), monotonicity (performance keeps climbing as dataset size increases), comprehensive reflection of data quality, while avoiding data overfitting to these metrics
In this methodology, large models and synthetic data play the role of supplying data and capability, while small models provide a means of rapid validation. This combination naturally forms a flywheel-like data optimization pipeline. Correspondingly, the open-sourcing of Llama 3.1 405B last week marks an important milestone for the upper bound of this flywheel.
Synthetic Data and Model Quality
A common concern here: if synthetic data is heavily introduced during training, won't data and resulting model quality collapse rapidly? There are two perspectives on this:
-
First, as ChatGPT and large models become increasingly prevalent online, it's hard to escape the influence of synthetic data on datasets. FineWeb analyzed all historical CommonCrawl datasets and found that ChatGPT-generated content has risen noticeably since early this year. At least for now, the introduction of this data doesn't appear to significantly harm model capability.
-
Second, at larger scales of synthetic data, we'll need more controllable and longer-tail sampling — ensuring both data diversity and that generated data distributions match reality. Randomly generated synthetic data can easily mislead models distributionally, harming capability on specific related tasks. Addressing these issues requires more investigation in at least the following directions:
-
How to conveniently control model sampling
-
The bidirectional relationship between data distribution and model output distribution
-
Rapidly predicting model performance based on training data (or minimal training)
War of Money vs. War of Data
Data remains the root of model capability. Improvements in dataset performance, or the pursuit of "optimal" datasets for specific models, will continue advancing toward larger-scale synthetic datasets and training larger models. If frontier large models remain, for some time, a war of money — after all, the game requiring 20,000 GPUs as buy-in isn't one you join with a briefcase — mid-sized and smaller models have effectively become a war of data, or rather data quality. We can see that publicly available data is already extensively used today, while proprietary content platform data is increasingly closed off for model training. As data becomes harder to obtain, data augmentation and the more fundamental work described above will only grow more important in the foreseeable future.
My WeChat: Can_Zheng. Feel free to add me for discussion.
Linear Bolt Bolt is an investment initiative established by Linear Capital specifically for early-stage AI applications targeting global markets. It upholds Linear's investment philosophy, focusing on projects where technology-driven transformation occurs, and aims to help founders find the shortest path to their goals. Whether in speed of action or investment approach, Bolt's commitment is to be lighter, faster, and more flexible. In the first half of 2024, Bolt invested in seven AI application projects including Final Round, XinGuang, Cathoven, Xbuddy, and Midreal.