In Sync with OpenAI, "Deep Principle" Leads 24 Top Global Institutions in Releasing LLMs for Science Benchmark | Linear Portfolio

Can high scores on test banks actually power scientific discovery?

Recently, Deep Principle, a pioneering company in the AI4S space, led a collaboration with 24 global research institutions including MIT, Harvard, Princeton, Stanford, Cambridge, and Oxford to publish a paper evaluating LLMs for Science.
The study found that current large language models perform worse than an average undergraduate student when it comes to driving scientific discovery. Within a day, OpenAI also released an overview of its own paper evaluating AI capabilities in scientific discovery, noting that existing benchmarks have failed in the AI for Science domain.
In sync with OpenAI and breaking through internationally — remarkable for a startup just over a year old. As the lead seed-round investor in Deep Principle, Linear Capital looks forward to the company's continued work deploying AI capabilities to power scientific discovery.
Recently, a paper led by a Chinese team alongside 24 top global universities and institutions — designed to evaluate LLMs for Science — went viral overseas.
That same evening, François Chollet, creator of Keras (one of the most efficient and accessible deep learning frameworks), shared the paper with a call to action: "We urgently need new ideas to push AI toward scientific innovation."
After AI influencer Alex Prompter shared the paper's core abstract, Mark Cuban, owner of the NBA's Dallas Mavericks, quote-posted it — business radar fully activated. Silicon Valley investors, European family offices, and sports media all flooded the comments.
In just one night, cumulative views approached 2 million.
Notably, in the same window, OpenAI also released an overview of its paper "FrontierScience: Evaluating AI's Ability to Perform Scientific Research Tasks," pointing out that existing benchmarks have failed in the AI for Science domain.
In sync with OpenAI and breaking through internationally — what kind of work could stir the global AI discourse?

Not long ago, the U.S. launched the "Genesis Project," billed as mobilizing "the largest federal research resources since the Apollo program," with a goal of doubling American research productivity and impact within a decade.
Yet amid emerging AI valuation bubbles and growing skepticism about energy-to-output ratios, the picture is contradictory: capital euphoria on one side, AI capabilities trapped in superficial applications like text-to-image on the other; LLMs constantly topping leaderboard benchmarks like GPQA and MMMU, yet unable to accurately parse simple NMR spectra.
The questions become unavoidable: Does acing a test bank mean you can power scientific discovery? How far are current models from real scientific breakthroughs? What kind of AI model could actually be up to the task, expanding humanity's boundaries? These debates have intensified amid white-hot U.S.-China AI competition.
Against this backdrop, Evaluating LLMs in Scientific Discovery — led by Chinese AI for Science startup Deep Principle alongside MIT, Harvard, Princeton, Stanford, Cambridge, Oxford, and 19 other global research institutions — directly addresses this question of our time.
The paper introduces the first evaluation framework for LLMs for Science: SDE (Scientific Discovery Evaluation), assessing major global LLMs including GPT-5, Claude-4.5, DeepSeek-R1, and Grok-4 across biology, chemistry, materials science, and physics — from scientific questions through full research projects.
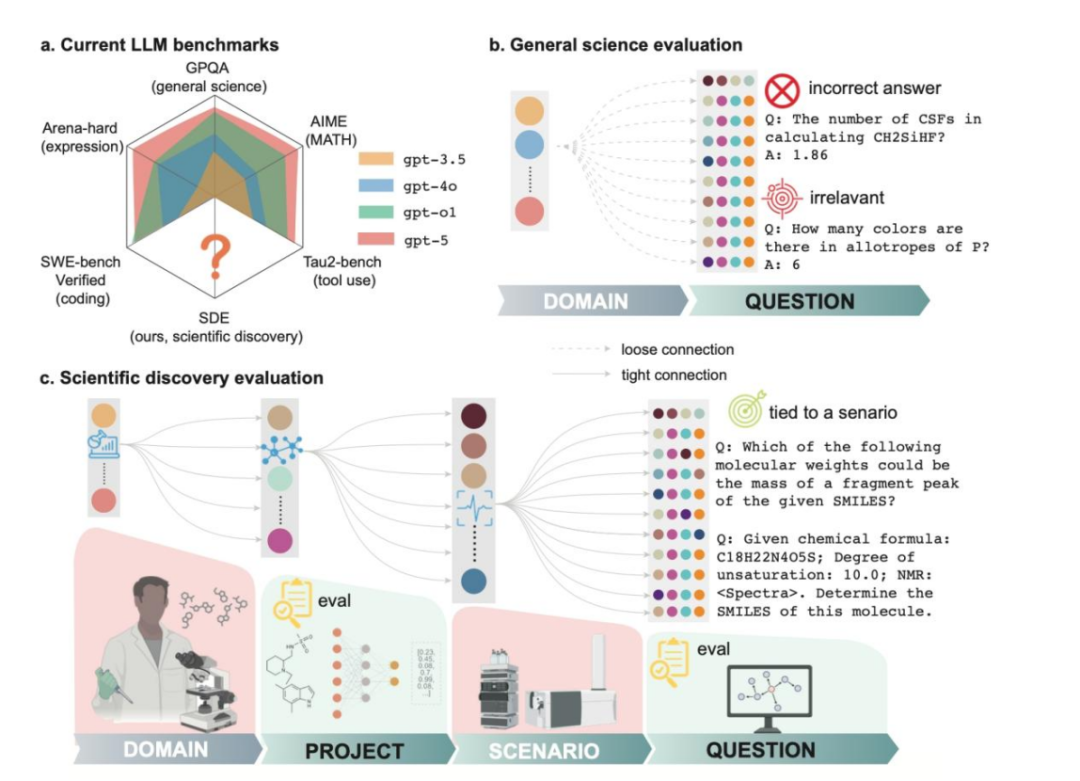
Unlike previous evaluation systems, SDE moves model assessment from simple question-answering into concrete experimental scenarios of "hypothesis → experiment → analysis."
The study found that GPT-5, Claude-4.5, DeepSeek-R1, and Grok-4 averaged 50–70% accuracy, far below their 80–90% performance on GPQA, MMMU, and similar test banks. On 86 "SDE-Hard" problems, the top score was under 12%, collectively exposing weaknesses in multi-step reasoning, uncertainty quantification, and closed-loop experimentation with theory.
More alarmingly, gains from model scale and reasoning improvements show clear diminishing marginal returns.
GPT-5, despite significantly increased parameter scale and inference compute over its predecessor, improved only 3–5% on average across SDE's four scientific domains, with some scenarios (like NMR structural analysis) actually showing performance degradation.
In other words, current large language models perform worse than an average undergraduate student in driving scientific discovery.

Chenru Duan, corresponding author of Evaluating LLMs in Scientific Discovery, is co-founder and CTO of Deep Principle. As early as 2021, while pursuing his chemistry PhD at MIT, he launched the AI for Science community with support from Turing Award winner Yoshua Bengio, and organized AI for Science workshops at NeurIPS.
In early 2024, he returned to China with MIT physical chemistry PhD Haojun Jia to co-found Deep Principle. Jia serves as CEO and Duan as CTO. Both born in the mid-1990s, they have already made a name for themselves in the global AI for Science entrepreneurship space.
Over 18 months since founding, the company has secured investment from Linear Capital, Hillhouse, Ant Group, and other prominent institutions, and established strategic partnerships with AI for Science leaders including XtalPi and DP Technology.
Deep Principle has carried the expectations of top global AI for Science researchers from day one. The company is now embedded on the front lines of global materials R&D, combining generative AI with quantum chemistry to push materials discovery into a new era.
Over the past year, they have published major results in Nature's major subsidiary journals and JACS and other top-tier journals, demonstrating both technical leadership and the open, collaborative mindset of a "post-95s startup."
From pioneering diffusion models for chemical reaction generation — proving that "it's not enough to generate materials, we need to generate synthesis pathways for them" — to direct comparisons between machine learning potentials (MLPs) and diffusion models showing that traditional MLPs aren't "universal," to now organizing top scholars and universities to launch SDE, proving that traditional Q&A benchmarks won't lead us to scientific superintelligence. Each move precisely targets core tensions in the AI for Science field.
Yet for all AI4S companies, the daily reality is the commercial test of whether AI can truly solve new product R&D problems and meet customer expectations.
As commercial partnerships with industry-leading customers have materialized, Deep Principle's database has accumulated extensive real-world industrial R&D scenario data and model application experience from customer collaborations and its own lab — all from frontline practice.
This combination of academic depth and hands-on AI for Science commercialization meant that when Deep Principle proposed building a new ruler to evaluate LLMs for Science, the call was answered immediately — bringing together over 50 scientists from 23 top global scientific discovery institutions to form the "dream team" behind SDE.
Among them were prominent scholars active in the LLM field, including:
- Huan Sun, MMMU initiator, Ohio State professor
- Yuanqi Du, Cornell PhD, "chief operator" of the AI4Science community
- Mengdi Wang, Princeton's youngest professor, pioneer in AI+Bio Safety
- Philippe Schwaller, father of IBM RXN, EPFL professor
Deep Principle's accumulated scientific discovery scenarios became the precursor to the SDE evaluation system.
After nearly 9 months of cross-institutional, cross-disciplinary, cross-timezone collaboration, Evaluating LLMs in Scientific Discovery was officially published — with the corresponding affiliation prominently listed as: Deep Principle, Hangzhou, China.

Thus, drawing on the collective wisdom of the world's top scientific discovery institutions, the Chinese startup Deep Principle and OpenAI across the Pacific now stand together at the starting line of the climb toward AI for Science — humanity's path to ultimate AGI.
Perhaps centuries from now, when humanity looks back on the AGI era, at the quarter-mark of the 21st century, this resonant serious discussion of AI for Science — echoed by Chinese and American teams alike — will be seen as having nudged LLMs away from endless leaderboard competition toward the true starry ocean of scientific discovery.
As for how to reach that shore, Chenru Duan puts it this way: "When large language models saturate on science Q&A leaderboards but still can't effectively support scientific discovery, it's like 'good test scores' not equaling 'top researcher' — it means we need new evaluation frameworks and training paths."
Deep Principle and its 50+ collaborators across 20+ institutions have demonstrated that the current LLM development path won't 'incidentally' crack scientific discovery.
The road to scientific superintelligence requires more fellow travelers walking alongside.




