CrossWe's Jia Kui: The Next Decade Is Physical World AGI

Let AI penetrate every corner of the physical world.
In 2016, Jia Kui returned to China after completing his studies abroad and threw himself into computer vision research. At the time, a flood of talent was rushing into facial recognition and image understanding, but he turned toward a direction almost no one else was exploring.
Over the next five years, he kept returning to two deceptively simple questions: What is the essence of 3D data? And what is the definition of Physical AGI? To him, these investigations into the three-dimensional world represented the core proposition.
Choosing an unpopular path also meant paying the price of long-term obscurity.
During those waiting years, he ran through models again and again, tested hypotheses repeatedly, and continually reconstructed his understanding of the world — yet he almost never wavered. "If you're doing what you love, why would you switch?" This is his criterion for judging whether someone is lucky, simple to the point of plainness.
His understanding of world models carries a similar near-intuitive precision.
He believes Physical AGI is called physical general artificial intelligence for a crucial reason: it must genuinely enter the physical world and ultimately land on a concrete intelligent terminal.
Humans observe the world from different perspectives, seeing often only mirrors of reality. When countless partial, fragmented pieces of information stack together, the world appears extraordinarily complex. But in Jia Kui's eyes, the physical world is elegant. If you can reach its true underlying mechanisms, it becomes as light as Einstein's E=mc². Only by finding this essential law can one build a truly scientific world model.
By the end of 2025, CrossWe open-sourced its core technology, EmbodiChain — a pipeline for online data streaming and model production that achieves fully generative synthetic data training with 100% generated data for virtual physical models. In this world, where AI learns the essential laws of physics, environments, objects, and robot embodiments can all evolve continuously.
There is more than one path to the destination. CrossWe has chosen a longer-term route: first create the "world," then let AI penetrate every corner of the physical world, ultimately building a sustainable path toward Physical AGI.

The Road to Physical AGI
Q: Please introduce yourself and what CrossWe is working on now.
Jia Kui: Since our founding in 2021, CrossWe has been dedicated to solving the problem of AI's interaction with the three-dimensional physical world.
I began researching computer vision in 2001. Starting in 2016, I started exploring how to use AI for 3D modeling and generation, and how to train models with synthetic data to drive robots in dexterous manipulation.
An important technical milestone came in 2019, when we published an end-to-end model capable of precise grasping of unknown objects trained entirely on mixed data. These technical accumulations laid the groundwork for our company preparation in 2020, when ZhenFund also came in as an angel investor.
In recent years, with the rise of Physical AI and the boost from large models, CrossWe's underlying technology, products, and business have gone through a cycle from steady to accelerated growth. Today, we have gradually formed a multi-dimensional, synergistic product matrix: with the DexVerse™ engine as our technical foundation, alongside KINGFISHER vision sensors, the Dexforce W1 humanoid robot embodiment, and PickWiz robot brain software.
Returning to CrossWe's core belief: Develop a sustainable road towards Physical AGI. We hope to forge a sustainable path, using continuous original technology to push AI into every corner of the physical world, creating real value across different industries.
Q: How do you currently understand Physical AI? What has changed during your entrepreneurial journey?
Jia Kui: I have always believed that Physical AI is something that must be advanced through practice. Only by continuously building technology and products can you truly approach it. Humans are a typical advanced biological intelligent agent. The relationship between human cognitive intelligence and bodily form corresponds precisely to today's relationship between large language models and Physical AGI.
From a technical perspective, we still follow the AI paradigm supported by massive data, large models, and strong computing power. This paradigm has benefited from text, images, and video accumulated on the internet since the 1990s, which is why large language models and multimodal systems achieved rapid accumulation between 2022 and 2025.
But Physical AGI is the proposition for the next decade, or even longer. Its data requirements are not merely quantitative increases, but a fundamental change in the paradigm of data generation.
The basic data elements for achieving Physical AGI may come from real robot data collection, or from video generation, or from the 3D generative technology and generative simulation that our team specializes in — these cutting-edge paradigms.
On the other hand, Physical AI must land on actual intelligent agents, operating in real application scenarios like homes and factories. This in turn poses different demands on the capabilities of terminal intelligent agents.
Whether from a technical or application perspective, Physical AGI is more difficult than the large models and AI Agent applications people see today. But its ceiling is higher, its imaginative space larger, and its pulling effect on social economy and human behavior greater.

CrossWe robots being shuffled
Q: What considerations went into designing the body configuration of CrossWe's humanoid robot?
Jia Kui: Physical AGI is called physical general artificial intelligence for a core reason: it must enter the physical world and ultimately land on a concrete intelligent terminal.
The form of this terminal depends on the first principles of its application scenario. If it's a robot for factory use, it doesn't necessarily need a humanoid form — its core requirement is whether it can stably and precisely complete assigned tasks.
In some commercial service scenarios, the robot's evolution path becomes more human-like. In social life or commercial services, people are building their own IP and persona, because what you're selling isn't just functionality, but brand value. If we look beyond digital humans and observe real people in the physical world, we find that creating robot IP and letting the robot itself generate derivative value is extremely important.
As for home scenarios, people have multi-dimensional demands for robots. First is solving practical household problems — for instance, we hope that after work, it can organize the shoe cabinet; or if there are children at home, it can tidy up toys scattered everywhere. This is the demand for its tool attributes.
But if the robot has a humanoid form, people will have higher companionship demands. This companionship encompasses language communication, emotional connection, and even whether its appearance is cute or warm. This is why some researchers currently focus specifically on "warm" robots, or pursue extreme aesthetic beauty in exterior design.
If you want to build a deep product that can both solve practical problems and generate positive interaction with people, balancing exterior design and interaction logic is crucial.

Realizing World Models
Q: What do you think of the different data collection approaches currently being used?
Jia Kui: The industry generally expects that the Scaling Law observed in large language models will also appear in Physical AI. But there's a precondition: without sufficient magnitude of data support, simply increasing model scale or computing power means little.
Therefore, the primary problem facing embodied intelligence right now is how to improve the efficiency of data generation.
Between 2024 and 2025, the industry gradually reached a consensus: obtaining training data by building data collection facilities and using real-machine teleoperation. But this approach's efficiency remains limited. Later, more efficient embodiment collection solutions like UMI (Universal Manipulation Interface) also emerged, though how capable a model trained through this path can become remains to be verified.
Another highly anticipated path is video generation. Models like Sora have already demonstrated powerful capabilities in content creation, but video generation's essence is a two-dimensional result. From a technical paradigm perspective, diffusion-model-based video generation fundamentally models in RGB pixel space, lacking explicit physical causal structure. This means it struggles to meet strict engineering standards in precision, stability, and physical consistency.
Our goal is to fully leverage the generation efficiency brought by models and computing power, while ensuring generated content possesses strict three-dimensional physical fidelity. Around this, we also conducted rigorous principle-based verification. The results proved that models trained entirely on 100% generative synthetic data can indeed work in real applications.
What we should truly focus on is not the inherent pros and cons of any particular data acquisition method, but which data paradigm can make the Scaling Law of AI large models actually function.
Q: What was your reaction when Sora was released?
Jia Kui: An important messaging concept when Sora was released was world model.
But the world model concept was already proposed in the reinforcement learning field back in 2018. Its core logic is that for efficient reinforcement learning, the system must possess an internal model to simulate the world, thereby learning and producing excellent strategies. Though this concept long existed in academia, it had never become mainstream.
Sora's stunning achievement was that its generated videos far surpassed previous results in appearance, dynamics, and scene expressiveness, yet it still conducted diffusion model learning within RGB pixel space. OpenAI tried to argue that if our model weren't a world model, how could it produce such realistic video results?
The service target of Physical AI's required models is not human eyes, but concrete task execution — for instance, how a robot precisely picks up a cup of coffee and hands it to you.
This is fundamentally different from pure two-dimensional visual perception. Anyone with basic machine learning or engineering knowledge understands that a 2D image is merely a projection of the 3D world from a specific viewpoint, meaning information necessarily gets lost during projection. Generated videos may look exquisite, but switch the viewpoint and significant distortions often become exposed.
Current video generation visual models fundamentally cannot solve problems in the accuracy of generated results regarding 3D shape, physical accuracy, and dynamic causal accuracy.
Q: Where does the world model currently stand in its development?
Jia Kui: This is a goal everyone wants to achieve. But how exactly to achieve it, I believe we must first think through the problem clearly. The industry currently still lacks a recognized and precise definition of "what is a world model."
When definitions haven't unified, people can only evaluate whether a model truly possesses world model capabilities by its results. If your model is a world model, it should consistently and accurately avoid obstacles and plan paths in autonomous driving scenarios; in robot operations, it should also precisely and stably complete grasping and manipulation.
Q: What is CrossWe's advantage in realizing world models?
Jia Kui: Our world model ensures absolute three-dimensional stability from the underlying logic of AI architecture modeling. From a statistical or mathematical perspective, this physical world is actually very elegant.
Why do people find it complex? Because we observe the world through different perspectives, including human eyes and various perception sensors, and these observation results are merely mirrors of the real world. These mirrors often provide partial information, and when countless partial and trivial pieces of information interweave together, they create the illusion that the world is extremely complex.
But in reality, if you can reach the true underlying mechanisms within the world, it becomes as clear and concise as Einstein's E=mc². Only by finding this truly correct, elegant essential law can you build a genuinely scientific worldview.
Our core logic is precisely to use AI to learn this essential law, rather than crudely piling up training with massive amounts of video. Because large volumes of video are essentially just scene superpositions from different viewpoints, with low learning efficiency and no fundamental guarantee of 3D physical accuracy.
Actually, other teams aren't incapable of doing this — almost every team in the industry emphasizes the importance of 3D physics and is trying to move in this direction. Our team's advantage lies in the fact that in neural 3D modeling and neural 3D generation — the technical route of using AI for 3D physical modeling and generation — we have consistently maintained an industry-leading position.
Q: Could you briefly explain CrossWe's recent open-source work?
Jia Kui: Our open-source EmbodiChain data generation pipeline directly addresses why data generation efficiency is so important.
In GS-World, we begin by proposing the Efficiency Law, which is the precondition for the Scaling Law. Only when data generation efficiency meets certain conditions can model performance continue to improve.
It then explains how to rigorously construct a 3D virtual world conforming to physical laws through generative methods. In this world, we can efficiently generate environments, manipulation objects, and even robot embodiments. Robots can generate data through operations in this controllable virtual space, thereby forming models and even achieving embodiment evolution.
This is not only a concrete academic achievement but also our technical roadmap.
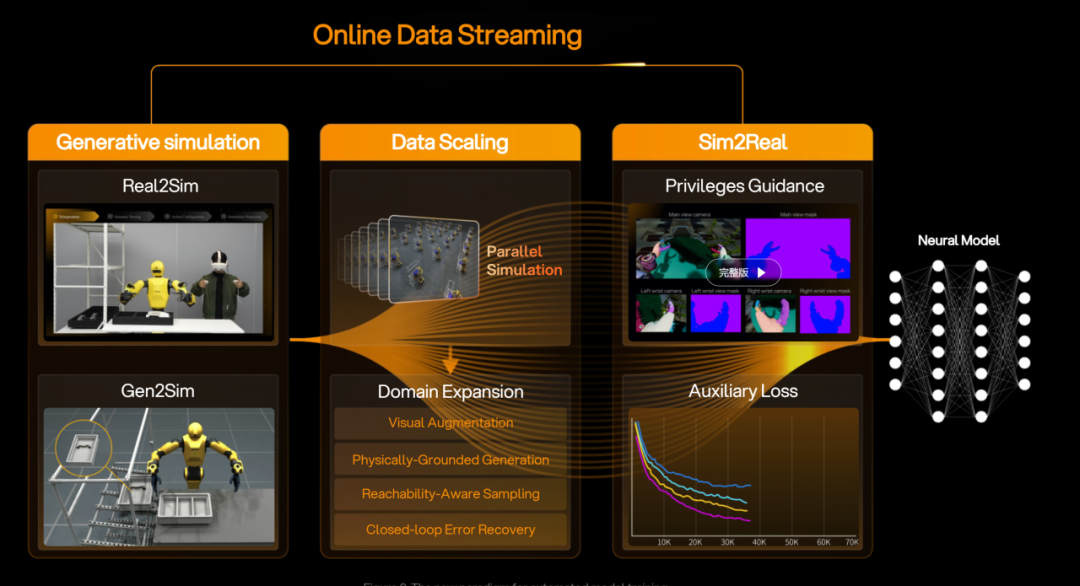
EmbodiChain schematic
Based on this, we designed an architecture capable of achieving the Efficiency Law. This is first a sim-to-real process. Whether through real-machine teleoperation, UMI-style approaches, or directly recording videos of human operations, we can extract 3D logical actions and project them into the virtual world. Then, we conduct efficient data augmentation and reinforcement learning in the virtual world. This paradigm can generate both precise 3D physical models and action policies.
We also conducted rigorous comparative tests on the open-source Motion dataset. Results showed that this paradigm significantly outperforms mainstream models like NVIDIA's GR00T and RDT in both efficiency and success rate. As we published, CrossWe has indeed achieved a VLA model trained entirely on 100% generated synthetic data. This is absolutely unprecedented globally.
We believe the correct logic is that you must first put a valuable robot into operation, let it serve customers and generate value.
We follow the autonomous driving field in activating "shadow mode," allowing data to flow back. Under this mode, what flows back is high-quality, annotated data with anomalies filtered out, data that can directly improve model performance. At this point, the robot is already working and generating returns in real environments; acquiring data is just a byproduct. This is the data flywheel paradigm for efficient product and service evolution.

The "Cold Bench" Period
Q: What was the catalyst for your initial interest in world models?
Jia Kui: I came to this field because I was focused on the essence of AI signals.
Looking back at 2015, too many people were flooding into facial recognition and image understanding, but I was thinking: what is the essence of 3D data? What is the essence of signals? As someone doing innovative research, the most basic requirement is absolutely not following trends. If many people are already doing something, it shouldn't be your first choice. Researchers must follow first principles, not parrot others.
During that stage when no one was involved, these explorations around the 3D dimension represented more fundamental, more important questions in AI — the kind of innovation I considered truly valuable. This capacity for independent research is actually a basic element that every mature PhD should possess through their professional training.
Of course, this persistence comes at a cost. The source of research can certainly be curiosity, but beyond curiosity, you need to add a bit of "utilitarian" thinking — can this curiosity ultimately produce value? Whether short-term, medium-term, or long-term value, you must project it.
The price of choosing a non-trendy direction is that you may need to long-term "sit on the cold bench." Looking at AI's development history, from the 1950s to today through several peaks and troughs, even AI godfather Geoffrey Hinton experienced extremely long cold bench periods.
One must have one's own persistence.
Q: When did you feel this "cold bench" sensation?
Jia Kui: Between 2016 and 2021, frankly, I gained far less sense of achievement than those working on image understanding.
In academia, your paper citation count largely depends on the base of people studying that problem. If only 1,000 people worldwide are paying attention to a certain 3D task, while 1 million are researching image understanding, then no matter how good your research is, you can't match hot directions in absolute influence metrics. Over five long years, this gap was objectively present.
But even during that time, I never thought about switching directions. I think the criterion for judging whether someone is lucky is whether they're doing what they truly love. If you're doing what you love, why would you switch?
At that time, I still firmly believed my research held greater value, consistent with my current judgment logic regarding Physical AGI.
From the perspective of enterprise growth and entrepreneurial logic, Physical AGI's ceiling is even higher than current large model companies' ceilings.
Q: How do research and entrepreneurship differ?
Jia Kui: Scientific innovation and entrepreneurship are different forms of value creation and realization. From the research innovation perspective, you immerse yourself in study, expecting logically sound research to eventually produce value, but results often remain on paper — this interaction is relatively restrained and indirect.
By contrast, entrepreneurship is solidly working backward from commercial value. To achieve true value, what products or services do we need? Which technologies need breakthroughs and are conditions ripe? What are the breakthrough timelines? Under this logic, we also need to think about the team's core strengths, differentiated characteristics, and whether we can genuinely produce value in target commercial scenarios.
This shift in thinking allows us to shed some research inertia in the innovation process. We don't do things to publish papers, nor do we pursue research that seems valuable but actually can't make real commercial contributions.
When your product gets used in real scenarios, that sense of achievement is completely different from purely pursuing paper citations. This value creation is more direct, able to genuinely reflect at various levels of society, whether the impact is large or small.

Returning to the Essence of Labor
Q: Are there any specific collaboration cases you can share?
Jia Kui: We have accumulated substantial experience in relatively semi-structured scenarios like industry and logistics, with some projects running for over two years. We're not simply promoting the CrossWe robot brand; we need to deeply embed robots into the business processes of franchise stores, brand owners, and shopping centers.
Making others' businesses run better is this humanoid robot's true value.
One case is our collaboration with "Weixiaofan." Weixiaofan is a healthy dining brand in Shenzhen and Hong Kong that labels calories on every boxed meal. Our robot is deployed in Weixiaofan stores, taking on tasks like sales guidance. This combination of "healthy dining + cutting-edge technology" is both an extremely attractive commercial draw and a practice of robots creating value in real commercial environments.

CrossWe robot deployed at a Weixiaofan store
Q: What differentiates CrossWe's products?
Jia Kui: The core isn't purely technical superiority, but who can truly close the loop from technology to niche commercial scenarios. Take facial recognition technology — now almost any company can achieve sufficiently high success rates, but the ultimate winners are those that have formed brand recognition and captured market position. Of course, if future robot demand becomes extremely large, the primary and secondary status of functional value versus added value may shift.
Q: What's next for CrossWe?
Jia Kui: Our business philosophy can be summarized in one phrase: DexBot Inside.
This term borrows from Intel's famous "Intel Inside" campaign. As a humanoid robot, even if it has traffic-driving and IP attributes in commercial service scenarios, it must ultimately return to the essence of labor.
In human-to-human interaction, even initial novelty typically fades within two weeks; robots are even more so. If a robot cannot generate genuine labor value, its IP and cute exterior cannot sustain its long-term commercial existence. In actual scenarios like stores, it will eventually degrade from a novelty to the essence of a laborer.

By Nuohan
Edited by Cindy


