A Deep Dive into the Beauty of DeepSeek's Creation: How Was DeepSeek R1 Forged?

AI penetration today is only 5%. For the remaining 95%, what will their first AI application be?
Hello everyone, I'm Tao Zhang, Product Partner at Monica.im.
Like many of you, I spent nearly the entire Spring Festival glued to my phone, scrolling through updates. Checking domestic reactions during the day, American reactions at night. That's how the whole holiday went. In the week since the holiday ended, you've probably already seen countless WeChat articles analyzing R1—from technical breakdowns to product implications to long-term impact. Chat groups have been forwarding conversation logs and "must-read" lists of a dozen or so R1 articles.
When Yusen (Managing Partner at ZhenFund) and I decided to do this sharing session, we knew much of the information might already be dated. With so many of us gathered here, rehashing common or macro-level observations would be a waste of everyone's time.
In preparing for this over the past week, I had our Chief Scientist Peak review many technical and algorithmic details with me. Meanwhile, as I synthesized information from various sources, I discovered a particularly fascinating narrative angle.
Today's sharing is both to help everyone better understand the context behind R1, and to show you the remarkable story behind this brilliant adventure.
Alright, let's begin.
01
The Best Tribute Is to Learn
This Spring Festival, I spent the holiday in Shanghai instead of returning to Chongqing, so I video-called my parents to wish them a happy new year. When I said "Happy New Year" to my mom, I heard my dad shouting in the background: "Quick, ask Zhang Tao if that Wenfeng Liang guy is really that incredible?"
This year, DeepSeek and R1 truly broke through to mainstream awareness—to the point where even elderly folks in second-tier cities like Chongqing were following these topics, genuinely curious about the underlying principles.
First, let's review what happened and establish a clear timeline so we're all on the same page.

On November 20 last year, DeepSeek released R1 Lite Preview on its official Twitter account. Honestly, that initial R1 Lite Preview had perhaps one ten-thousandth of the impact we see today—not even 1%. It only attracted interest from a small group trying to reproduce o1 after its release in November, with some even doing distillation and SFT work based on it. But none of this broke out of academic circles.
Then on December 26, DeepSeek V3 was released. Compared to R1 Lite Preview, its impact was significantly larger. I'll give an example shortly to show that, at minimum, it did break through in academic circles.
The third milestone was January 15, when DeepSeek released their app. If you looked closely, the app already included DeepThink mode at launch.
But DeepThink remained completely overlooked—both domestically and internationally. If you put yourself back in the context of January 15, this makes sense. At the time, the news cycle was dominated by one story: Trump's impending inauguration. Public attention was focused on these political events. It wasn't until January 20 that R1 was formally released, with both the research paper published and model weights open-sourced.
Looking at this timeline, the earliest signs of R1 actually appeared in November—it wasn't an overnight phenomenon. Several other key milestones deserve attention along the way, including the significance of V3, which is one of our core topics today.
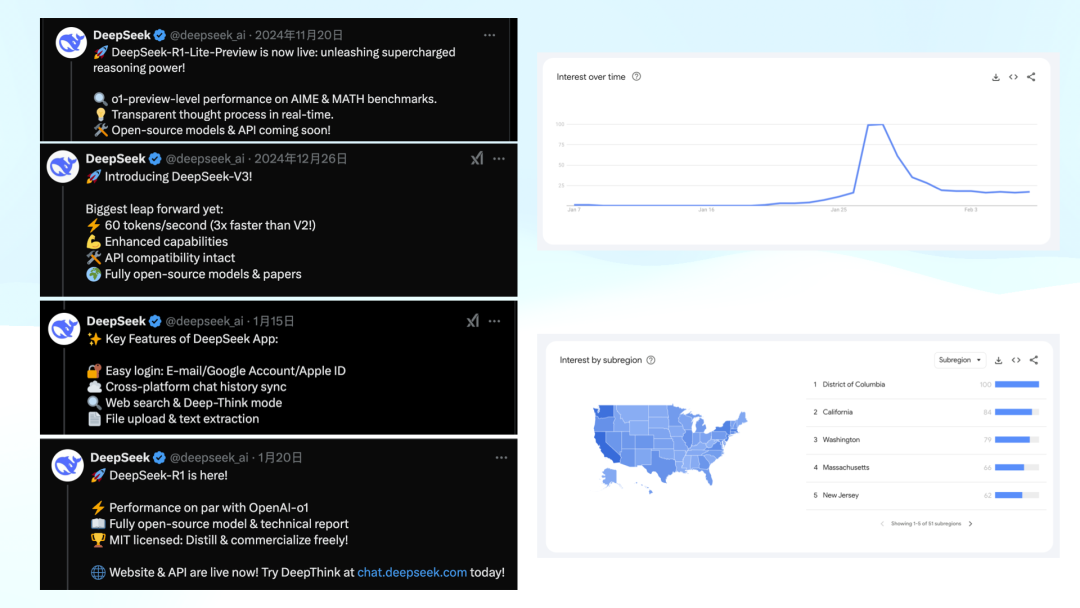
Next, let me show you an interesting phenomenon. Searching for "DeepSeek" on Google reveals that attention began on January 20, with R1's release. As academic discussions started spreading, heat gradually built between January 20-24 and through the 27th, when NVIDIA and other American AI stocks "cratered," pushing DeepSeek search volume to its peak. Even after cooling somewhat a week later, it remains around 20% of peak levels—far above the near-zero baseline before January 20. This shows that while traffic has moderated, attention hasn't fully dissipated.
Here's an interesting question—can you guess? In the United States, which administrative region showed the highest interest in DeepSeek?
I found this fascinating when I saw the data. I assumed it would be California, given the concentration of AI researchers there. But actually, the highest interest came from Washington D.C. You can imagine: after the market shock on the 27th, politicians in D.C. frantically Googling "DeepSeek" trying to figure out what the hell it was.
The subsequent rankings were more predictable: California, Washington state, and other regions with traditional IT companies and AI research institutions. But DeepSeek's level of attention is genuinely worth noting.
So far we've discussed reactions from the publishing side. Now let's look at feedback from America's elite KOLs. You may recall I mentioned that when V3 was released on December 26, unlike R1 Lite Preview, this one truly "broke through" in academic circles.
Why do I say this? Look at this screenshot—on the right is Andrej Karpathy's Twitter. That same day, he posted a very long thread introducing V3 in detail, calling it a "very nice and detailed tech report." It's clear that by December 26, V3 had gained recognition from mainstream American academia, though many hadn't yet grasped its deeper significance.
Now back to the "explosive" moments during Spring Festival.
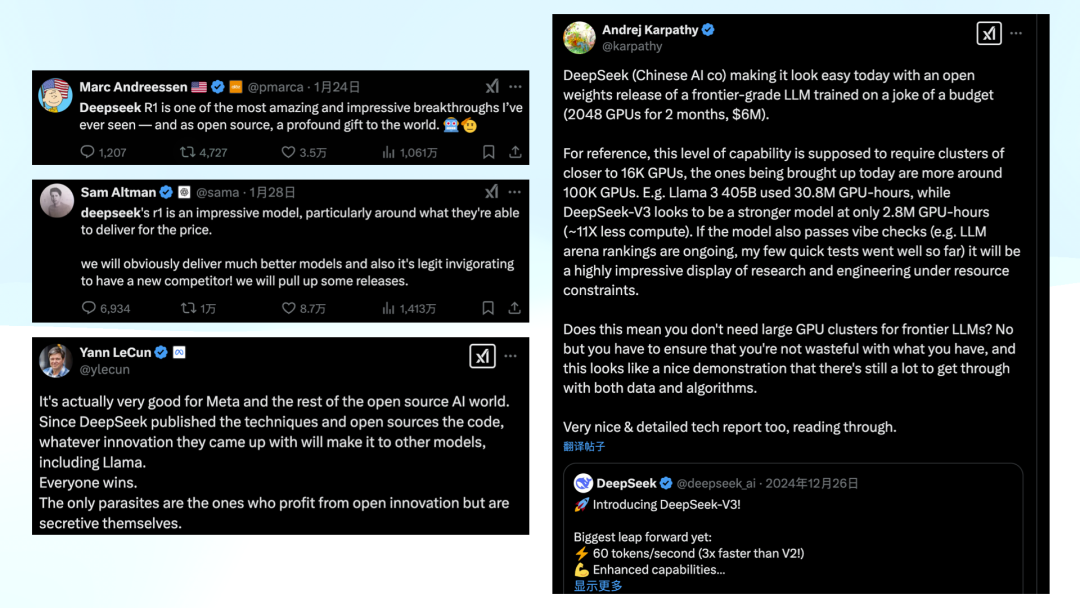
What first made me realize American opinion was shifting? Many of us were in various chat groups and probably saw this. I distinctly remember excitedly forwarding Marc Andreessen's Twitter. As you know, he typically takes an aggressive, sometimes even contemptuous stance toward Chinese tech.
On the 24th, he started posting a flurry of tweets: What is this thing? Absolutely mind-blowing. Initially he would add caveats like "this is amazing, but note that my saying it's good doesn't mean I'm happy about it—I think it's dangerous." But just one day later, his tone completely changed. This tweet contained no negative framing whatsoever—purely positive expression.
By the 28th, Sam Altman was forced to respond, though rather awkwardly, with excuses like "actually I wanted to open-source, but the organization wouldn't allow it." Yann LeCun acknowledged R1's impact and research quality while trying to steer the narrative toward "open source's victory" rather than any particular country's victory.
Regardless, this work has received recognition from the very top of the American AI establishment. Whether regarding quality or the significance of the event itself, the impact is undeniable. Whether this impact is good or bad, and why—that's what we'll explore next.
By February 2nd or 3rd, a few contrarians were still claiming this was all hype from DeepSeek-paid shills. The mainstream simply ignored them. The facts speak for themselves—no need for debate.
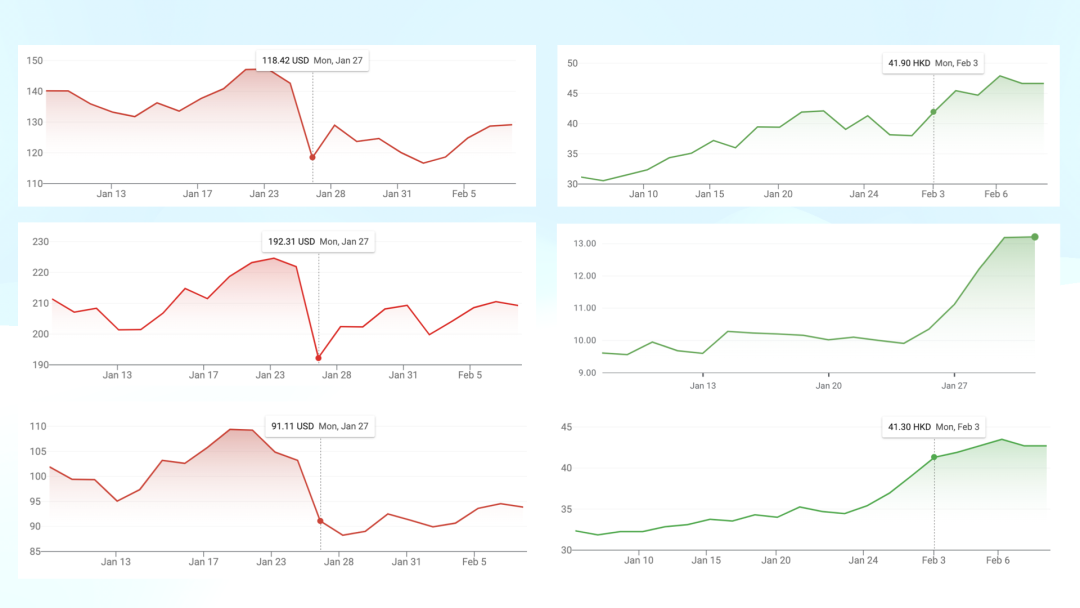
Most notably, on January 27th, markets convulsed. On the left, from top to bottom: NVIDIA, TSMC, and Micron—all instantly cratered. On the right, from top to bottom: SMIC, 360, and Kingsoft Cloud—suddenly surging, as if showing some "East rises, West falls" dynamic. This demonstrates that R1's impact on the real world cannot be ignored.
In Sensor Tower data, the left chart shows DAU, with the purple line representing ChatGPT. At the bottom, smaller competitors like Claude and Perplexity—longtime ChatGPT followers with relatively constant, low user share—saw DeepSeek suddenly spike in late January to roughly 20% share.
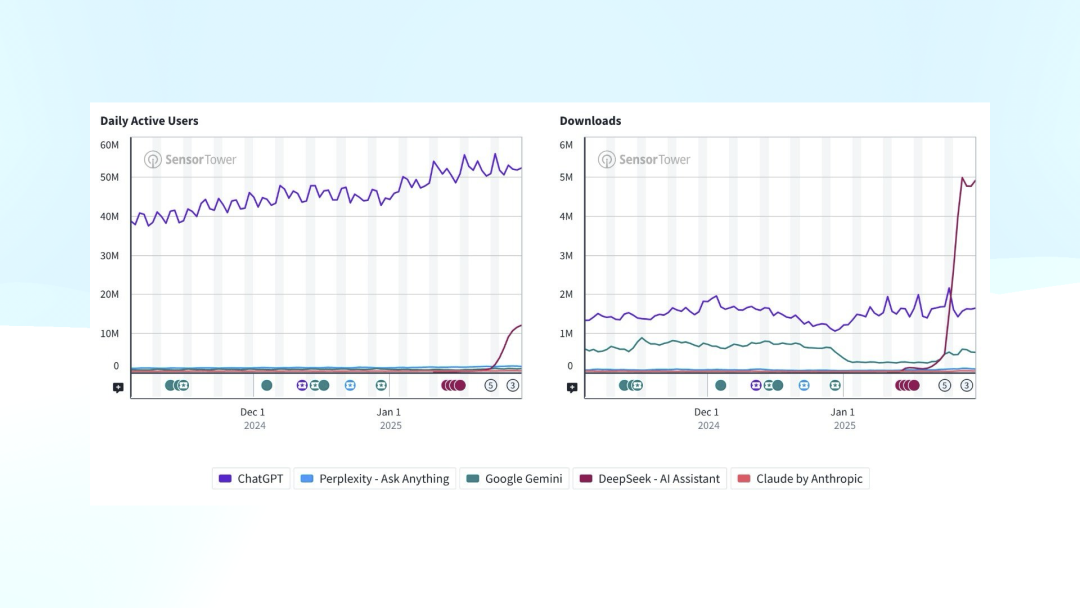
Left: DAU; Right: New downloads
The right chart shows new downloads, which continued growing after passing a certain inflection point. I screenshotted this relatively early—checking yesterday's latest data, the left trend keeps climbing, while right-side downloads have moderated but remain above ChatGPT. For now, this trend continues.
Whether through industry leader recognition, stock market reactions, or actual user choices, this event's impact is real and carries genuine user value. These are the major changes of the past two weeks.
Now, back to why we're organizing this learning session. This matters deeply to me. I've been following closely since January 23rd, reading extensively across Chinese and American discourse, both inside and outside the industry. As this event broke through to mainstream awareness, more non-specialists began paying attention, and people's explanations became oversimplified.
For instance, some attribute it to cheap Chinese labor driving down the cost of America's top-tier tech. Others call it plagiarism — success through copying alone. There's also the narrative of an obscure, tiny team suddenly producing world-class technological innovation. Yet every one of these explanations remains superficial, detached from the product itself, lacking genuine technical understanding.
Oversimplifying this event would be arrogant. The best way to engage with it is to learn from it.

When confronted with an event of this magnitude, merely filing it away in memory isn't enough. To study it, understand it, and figure out why it achieved such massive impact — that's the core purpose of this session.
02
What Is a Reasoning Model?
For most of us here, we're not specialized researchers in algorithms or engineering. I myself work in product. The fundamental question we need to address first is: what exactly is a reasoning model?
We already have large language models. Why do we need reasoning models?
I've prepared a small test. You may or may not know this, but the human brain has a special capability called "subitizing." This isn't simple numeral recognition — it's intuitive judgment of quantity. For example, I'm going to flash an image, and you'll have one second to tell me how many yellow balls are in it. Generally, a typical person can only subitize quantities of six or fewer. Okay, get ready — 3, 2, 1, switch!


Subitizing test
Through this experiment, we can see that after thousands of years of evolution, humans don't necessarily need to count objects one by one — within a certain range, we can judge quantities intuitively. The cognitive mechanism behind this phenomenon is also an important foundation for reasoning models.
Language models, particularly large language models, share a similar characteristic: when generating answers, they typically respond directly, even though this approach often leads to errors. A classic example is CoT (Chain-of-Thought). Jason Wei emphasized a crucial insight: models need more tokens to think.

Peak once shared with me a perspective that cuts straight to the core. As you know, a language model's essence is activating a massive neural network matrix. When you input a single token, it activates certain parts of that matrix, but this activation is limited. When you input more tokens, more parts get activated, and the information volume increases accordingly. Therefore, more tokens mean the model can gather sufficient information to make more precise decisions.
The idea that models need more tokens to "think" is what led us to propose the concept of reasoning models.
What is a reasoning model? Let me illustrate with an example. Suppose we ask: "How many subway stops from Wangjing West to Xizhimen?" A "direct response" model might answer as shown on the left below: "Nine stops."
A reasoning model would produce the response on the right. It first considers multiple transfer routes, then compares the number of transfers for each, and finally synthesizes the optimal solution. A reasoning model doesn't just give an answer — it shows its thinking process.

You might think this sounds similar to CoT. So what's the difference between reasoning models and CoT? If you're used to using ChatGPT, you might intuitively assume that a reasoning model is just CoT — I can simply write out a CoT, have it reason step by step, and that's it. For the subway question just now, we could tell the model: please first list all possible transfer routes, then calculate the number of stops for each route, and finally synthesize the optimal answer.

If you're willing to write out such detailed CoT for every single question, that approach can work.
But here's the problem. Let's look at an event that shocked the entire industry last year — when OpenAI released its o1 series, it broke multiple records. In mathematics, for example, its scores jumped from 13 to 56 and then to 83; in coding, it skyrocketed from 11 to 89, practically breaking the leaderboard. The PhD-level science questions showed less dramatic improvement, but still terrifying gains. If you read papers regularly, you know that improving a benchmark by even one or two points is publishable.
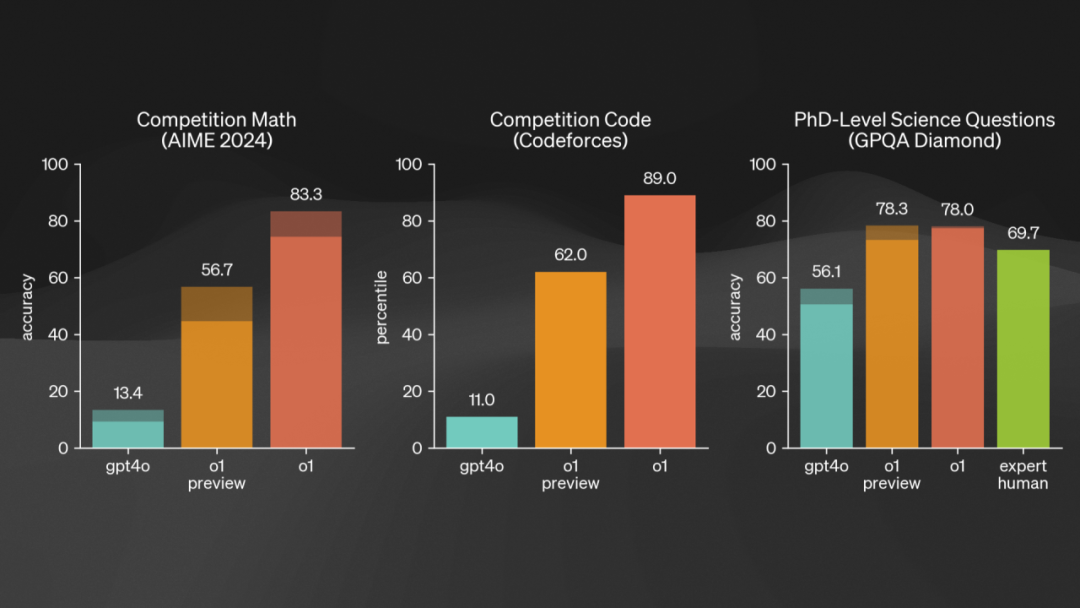
What surprised people most was the PhD-level performance. The green bar on the right represents human expert scores. ChatGPT had surpassed actual PhDs.
The essence of a reasoning model is letting the model construct its own CoT and display its intermediate reasoning steps. While you can manually write CoT yourself, the question is: can we write complete CoT for every single problem?
For example, these two questions appeared in 2024 AI benchmarks and PhD-level evaluations respectively. Perhaps if you were a math or physics PhD, you could write out the CoT — but for the vast majority of people, articulating the step-by-step thinking process for each question is no easy task.

Left: AIME 2024 test question
Right: PhD-level GPQA Diamond test question
This is why reasoning models are necessary. They help us tackle problems in specialized domains. For example, reasoning models excel at solving puzzles — translating WWII cipher transmissions, performing mathematical proofs, resolving complex decision problems, even open-ended questions. A reasoning model doesn't just deliver a final answer; it shows its thinking process.
For simple knowledge questions like "What is the capital of China?" we obviously don't need a reasoning model — just answer "Beijing." It's expensive, and overthinking makes errors more likely.

Reasoning models have their appropriate use cases. Why are they so important in our industry? Two reasons.
First, the breakthroughs you've seen in mathematics, coding, and PhD-level domains signal that large language models aren't limited to chatbot applications anymore — they can now accelerate national scientific research. The major AI labs pushing development are all pursuing AGI, and even higher-level ASI (superintelligence).
Second, at least based on R1's results and people's experience using o1, we've found that although reasoning models are trained primarily for math, physics, and coding problems, once a model masters reasoning processes, it becomes more logical and thoughtful across broader scenarios — including writing and conversation.
Starting in the second half of last year, reasoning models became the direction everyone wanted to crack and solve.

So the question becomes: how do we reproduce o1? We first need to look at o1 itself. Though we don't have enough time today for deep exploration, I want to share something particularly interesting.
On its release day, o1 published its list of core contributors. And OpenAI's final paper before going completely silent in 2023 was titled Let's Verify Step by Step. This paper described training a model through reinforcement learning by breaking problems into steps and scoring each one. After o1's release, many people reviewing OpenAI's work discovered that this was the last research paper they had made public — with nothing new released since.
Many people came to believe that Let's Verify Step by Step held the key to replicating o1, and OpenAI had also released a dataset called PRM800K. The format looked like what you see in the screenshot below: each problem included a step-by-step reasoning process, with every step scored and labeled as positive, neutral, or negative. OpenAI had made this PRM800K dataset public.
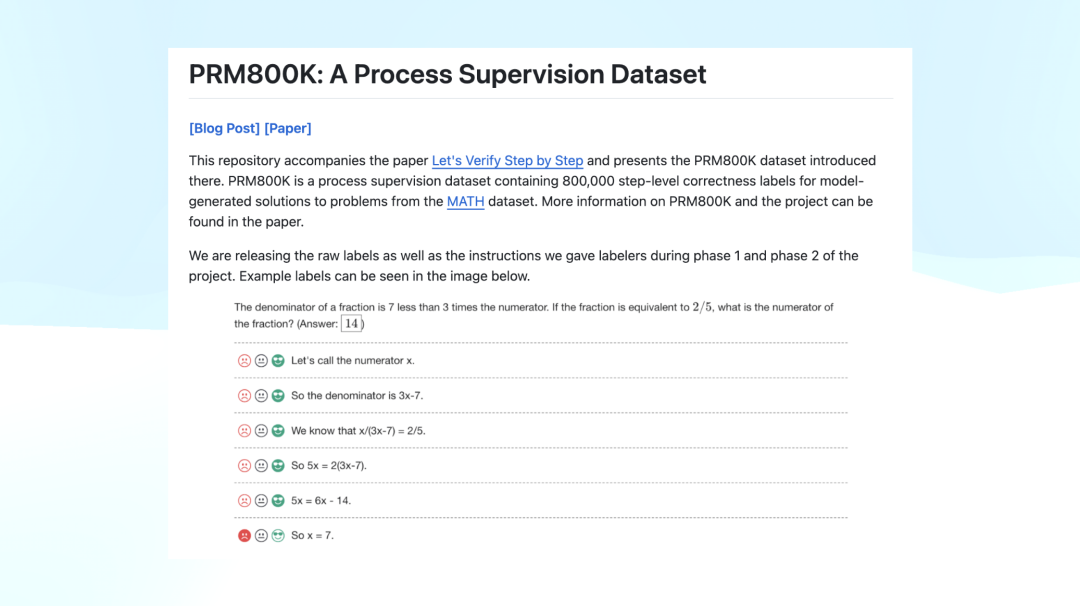
Think about it — if you were a researcher who started studying o1 after its release, reading this paper, you'd naturally connect the dots and suspect o1 might be using a similar PRM (Process Reward Model). It would be hard not to speculate in that direction.
If you search for how to replicate o1, I did a quick search and clicked the top-ranked article, published on December 30 last year. It mentioned that after o1's release, China saw a wave of o1-like models. The R1 referenced back then wasn't the R1 we know today — it was R1 Lite Preview, along with Kimi Math's related techniques.
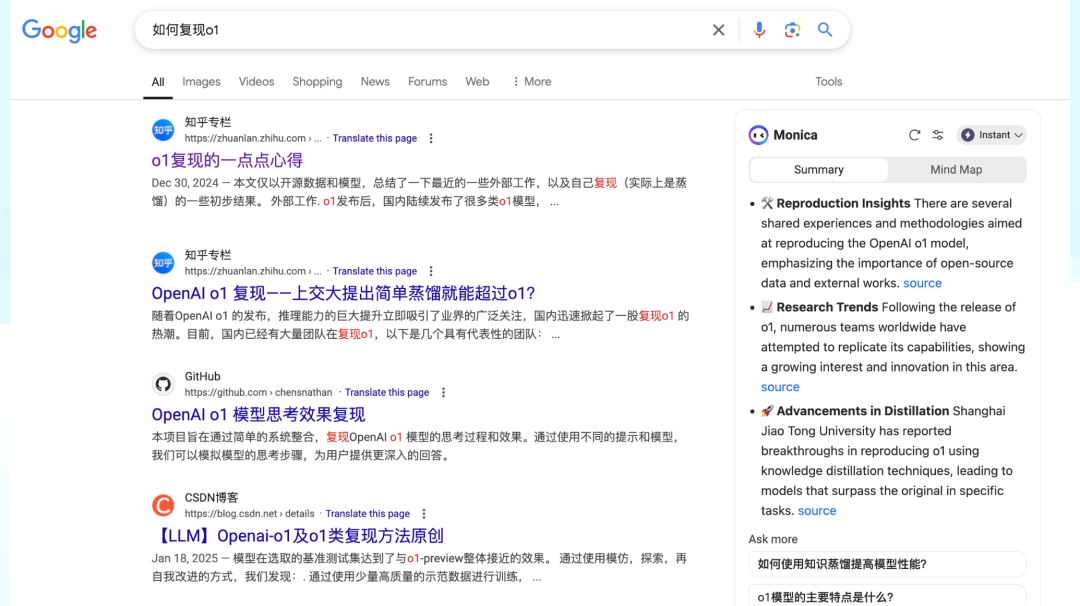

The article noted that the industry had largely split into two camps: tree search and distillation. The tree search camp aligned with the approach OpenAI described in Let's Verify Step by Step. The distillation camp used existing models like o1, r1, and Kimi Math for distillation. Notably, there was no mention of what we'd now recognize as R1's pure reinforcement learning approach, because the entire industry at that time assumed OpenAI had used this PRM-based method. I know that in both Silicon Valley and China, many companies were preparing datasets similar to PRM800K.
This might sound a bit cynical, but I want to share what I was thinking at the time: I kept wondering why Scale AI CEO Alexandr Wang was throwing such a public tantrum over this. I always suspected one important reason was that his company had taken on massive PRM data labeling contracts — only to now discover that data might not be particularly useful.
That was the state of the industry. Though this article was in Chinese, that doesn't mean only China was going down this path. Beyond Anthropic and OpenAI, plenty of teams in Silicon Valley were exploring similar directions too — MCTS and so on. It seemed like virtually every team was pushing in this direction.
03 Letting Models Think Freely
But here's where our story reaches its first climax — while everyone else was heading down what now appears to have been, at least temporarily, a wrong path, two teams were embarking on a breathtaking journey of exploration.
What's even more exciting: both teams were from China — DeepSeek and Kimi.

First, let's talk about why this was such a breathtaking journey. Around the time of R1's release, Kimi launched Kimi k1.5. They didn't open-source it, but they published a detailed technical report covering the core of k1.5's training.
That said, from a reading experience perspective, the k1.5 paper is relatively difficult to get through. Reading the R1 and V3 papers, by contrast, is genuinely thrilling.
The Kimi k1.5 paper is packed with engineering details — if you want to replicate it, this paper is incredibly valuable. The level of detail almost feels like hand-holding. But precisely because of this, it's not a great read. However, I found an article on Twitter written by a Kimi k1.5 team member about the thinking behind k1.5. The writing is absolutely exceptional — it genuinely stirs something in you. I have to share some of it.
A Zhihu answer by a Kimi employee @Flood Sung
https://www.zhihu.com/question/10114790245/answer/84028353434
First, the article notes that o1 dropped on September 12, stunning the world, and the team quickly noticed how powerful long CoT was. They realized they had to commit to long CoT or be left behind. So they started thinking about how to draw inspiration from OpenAI's work, and in the process discovered two key videos.
These weren't the September presentations — they were earlier talks by Noam Brown and Hyung Won Chung. The videos were only made public when o1 launched, which made the team wonder: why release them at this specific moment? There had to be some connection to how o1 was trained.
When I read this analysis, I thought: "Damn, what a brilliant angle." So they dug deep into these two videos. In Noam's talk, they found a crucial slide mentioning AlphaGo and its successor AlphaGo Zero. Everyone knows AlphaGo Zero was entirely reinforcement learning-based, and this slide emphasized Test-Time Search.
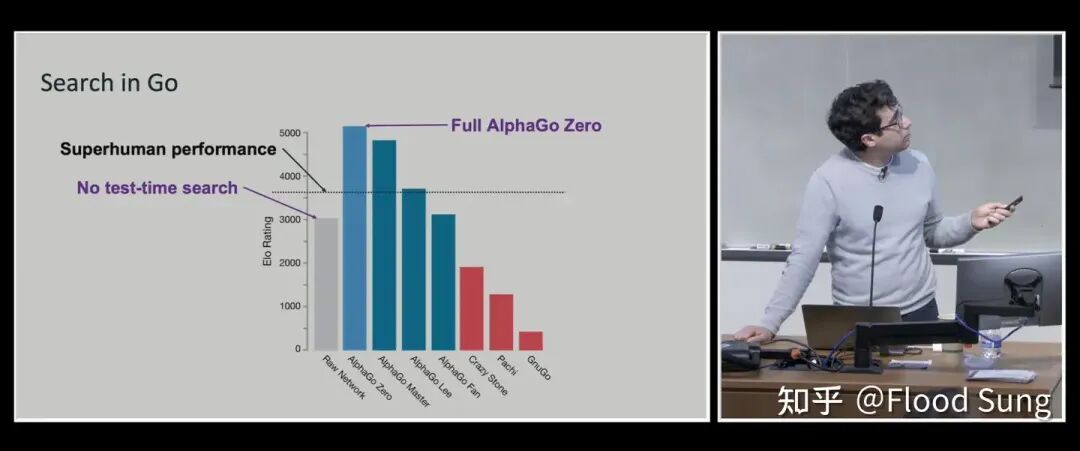
Many assumed Noam was highlighting this to explain AlphaGo's MCTS — Monte Carlo Tree Search, where you explore multiple paths simultaneously, evaluate scores, and find the optimal solution. But the Kimi team made a non-consensus judgment: they believed Noam was actually emphasizing the S in MCTS — Search itself — not the specific MCTS algorithm. This insight led to their first key idea: let the model search on its own! Let the model learn to explore different paths itself, rather than artificially constraining how it thinks.
This connected to Richard Sutton's famous essay The Bitter Lesson.

The second video was equally crucial. They distilled a core principle: "Don't teach, incentivize." In other words, don't instruct the model — motivate it to explore on its own.
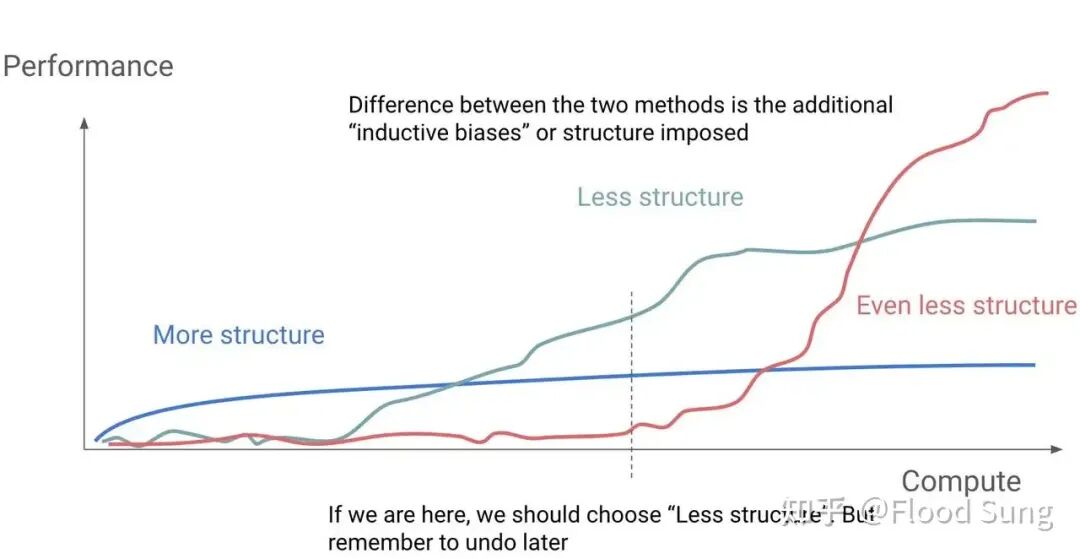
In numerous experiments, the less structured the model's architecture (less structure), the higher its ultimate performance ceiling when compute scales up. Conversely, if you impose too much structural constraint early on, you cap its final performance and sacrifice possibilities for autonomous exploration.
They pushed further: why did this speaker place such emphasis on structure? What is structure? I found this section especially exhilarating to read — it felt like I was watching this Kimi researcher's internal monologue in real time.
MCTS is structure. A* algorithm is structure. These all constrain a model's freedom to think. They believed OpenAI's PM-800K training approach suffered from the same problem — it used a fixed reasoning dataset to tell the model how to think in different situations. This effectively hardcoded a specific thought process, limiting the model's capacity for independent exploration.
Their ultimate conclusion: o1 didn't constrain how the model thinks. This is extraordinarily important. Based on this, the Kimi team decided not to use MCTS.
I believe that in September, right after o1's release, they spent considerable time researching this direction, and by October had firmly established their own research path.
Think about it: many teams were still exploring MCTS directions in December, but a team like Moonshot AI had already found another route by then. I believe DeepSeek had a similar realization around the same time, though I'm not sure if their learning process was identical — but they must have recognized similar key insights.
They continued thinking: many so-called "agents" today are essentially just workflows, and these agent workflows are highly structured, which limits the model's capabilities. So they made a judgment — workflow-based agents only have short-term value, not long-term value. Right? Though that's a separate topic.
He concluded with this: "All in all, we need to train models to think like us humans do — to think freely!"
He showed the final slide of Noam's talk, their Future Work, which outlined their future research directions. This part inspired him the most. What was their core insight? Use genuine incentives for reinforcement learning, and don't let the reward model itself become a constraint.

Noam discussing future directions at the end of his talk
This concept might seem abstract, so let me explain. There are many algorithmic details involved that aren't suitable to expose today, but you can understand it this way: sometimes it takes ten steps to reach the correct answer. If we only reward based on the final answer, people worry the model might go astray during the long intermediate process — that's why nobody dared to directly use Outcome Reward Models (ORM) in the past. Instead, what OpenAI championed was PRM, Process Reward Models, which focus on step-by-step rewards during training.
But they arrived at a crucial conclusion at the time: don't do process incentives. What truly matters is whether the final answer is correct — that should be the core incentive for the model.
They didn't know it then, but they later discovered that DeepSeek R1's paper also mentioned a similar view — don't rely on process rewards.
So they eventually settled on their Practice Program, or "practice more" — giving the model an environment where it can keep solving problems. Just train repeatedly, and improvement follows.
Suck at something? Practice more. The article put it like this: "Problems, problems, and more problems! Problems with standard answers — grind them!"
I found this article absolutely brilliant. It demonstrates how to reverse-engineer o1, combining various information with professional expertise to ultimately derive the correct conclusion.
The slight regret, though, is that k1.5 didn't go far enough with pure RL — it still used some upfront activation guidance, unlike R1 Zero's completely bootstrap-style pure RL approach.
The biggest limitation might simply be that it wasn't open-sourced, so its industry impact fell far short of DeepSeek R1.
Of course, if you've read the k1.5 technical report, you can't help but admire both teams. Though today's focus is DeepSeek R1, I still want to specifically mention Moonshot AI's k1.5 — this was a truly brilliant exploration.

04
DeepSeek R1 Technical Report Deep Dive
The title of the DeepSeek R1 paper is "Incentivizing Reasoning Capability." The core idea of this paper is exactly how to enhance the model's reasoning capability through incentives. Compared to V3, R1's approach is relatively easier to understand, but it still takes considerable time to fully grasp.

So here I'm borrowing from an article by Sebastian, whose section on understanding reasoning models is particularly excellent, especially one figure.
This figure is extraordinarily well done, because when reading the R1 paper, even researchers can get confused reading it straight through. Before R1's final form, it went back and forth between V3 and R1 Zero in a mutual training loop, something like "pulling yourself up by your own bootstraps," which makes it easy to lose your bearings. But this figure perfectly presents R1's three training outcomes.
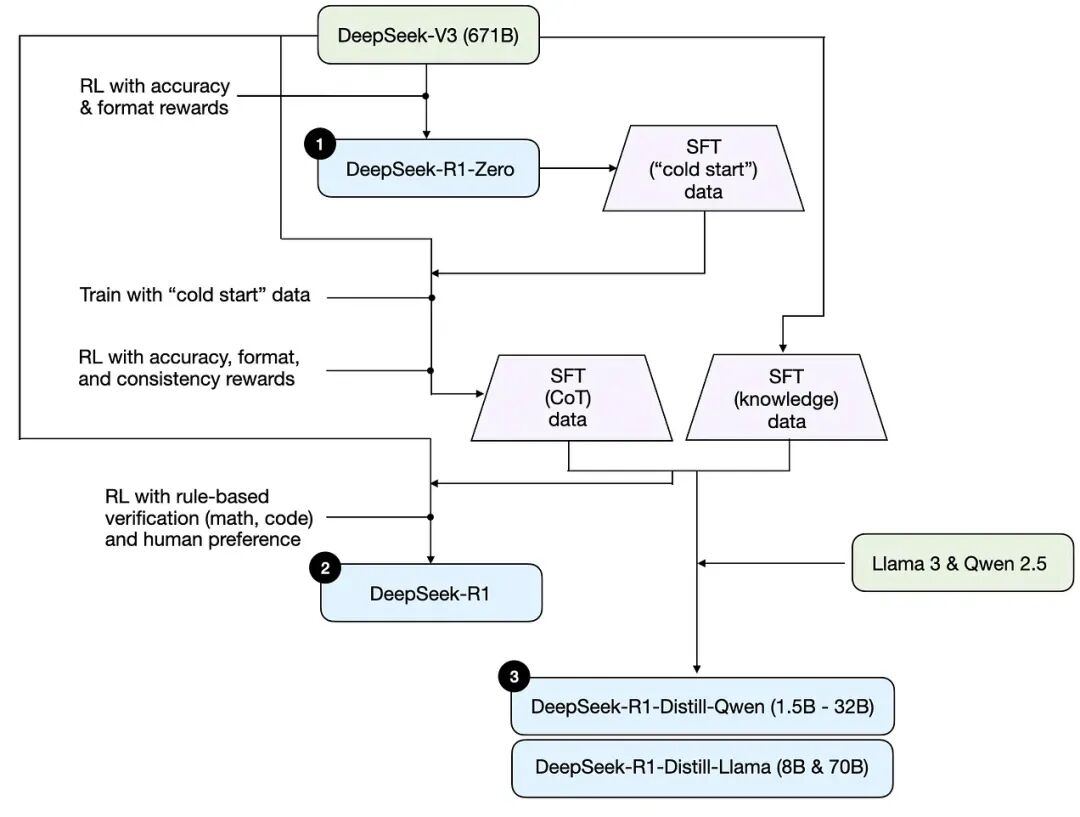
The first is labeled R1 Zero, the second is DeepSeek R1, and the third is its distilled versions. Currently, if anyone is trying to run this locally, they're usually running one of these distilled versions.
Let's start with the most magical point. If you're from industry, what might shock you most isn't the final R1 model — it's R1 Zero. It's stunningly simple. DeepSeek started with a powerful base model, DeepSeek V3, the model released in December that Andrej Karpathy praised.
Based on this model, they used pure reinforcement learning for training, but the process itself is extremely simple. They used a fixed template during training.

Those familiar with AI products can think of this as a system prompt. Specifically, the system prompt establishes "a conversation between a user and an assistant" — the user asks a question, the assistant answers. But the assistant must first "think through the reasoning process in its mind," then provide the final answer. Additionally, the assistant must tag its reasoning process within <think> tags, and put the answer within <answer> tags.
During training, they used this simple template, with the highlighted prompt filled with various questions during training — things like "What is 1+2?" or "Given the equation a^2 + b^2 = c, find the value of b." But the training template itself is just that simple.
Their reward model is equally simple, divided into two main categories:
- Accuracy reward: Whether the answer is correct. For example, if the model answers 1 + 1 = 2, it gets +1 point; if wrong, no points.
- Format reward: The model must answer in the required format. For instance, if the question is "What is 1+1?" and the model directly answers "answer 2," it gets zero points. But if it writes out the reasoning process in <think> tags first, then gives the answer in <answer> tags, it receives a higher score.

Because this reinforcement learning process doesn't use PRM methods, it can't employ an equally large model to make judgments. Instead, they adopted a rule-based reward model, ensuring the judgment criteria are extremely simple and clear — the answer is either correct or incorrect. So they prepared large quantities of problems with clear right-or-wrong answers for training: math problems, physics problems, coding problems.
For coding, it's similar to informatics competitions — they prepared a sandbox where code is submitted and run to check if the output is correct.
Beyond answer correctness, the second requirement is format reward. It requires putting the reasoning process in <think>. If you're thinking about what 1+1 equals and you think through a bunch of steps, you get a point.
They also used GRPO for training. Notably, traditional reinforcement learning mainly relied on PPO — in the k1.5 paper, for instance, the authors discussed whether to use PPO, and decided against it. They ultimately chose another method. PPO's biggest problem is that at every step of reinforcement learning, you need to not only adjust the policy model but also optimize the value model, leading to enormous computational overhead.
GRPO uses a rather brute-force method, somewhat like throwing the same question at the policy model eight times, then giving an average based on the correct answers.
Just remember that GRPO is less computationally expensive, but can effectively calculate after each round of RL exploration how far the model is from the right direction, and how to incentivize the model toward correct development.
In short, R1 Zero only did three things: a basic training template, a simple reward model, and the GRPO strategy.
Note that they didn't use complex reasoning datasets like PRM800K, nor did they teach the model to always think through eight steps first — they taught it nothing.
During training, they only provided the problem, the answer, and the rules. The horizontal axis shows the number of RL iterations, and the vertical axis shows the length of the response. They found that as the model learned, it started generating increasingly longer answers on its own. In the reward model, we never incentivized length — we only judged correctness and whether the model showed its reasoning.
But the model discovered on its own that the longer it thought, the more likely it was to answer correctly. This finding was remarkable, because previous teams hadn't realized such a simple approach could solve the problem. This is the most important chart.
That is, the highlighted sentence: "R1 Zero literally solves reasoning tasks with more thinking time." Without any explicit incentive, this model autonomously learned to solve reasoning tasks by increasing its thinking time.
Let's look at the benchmarks. R1 Zero isn't the R1 that everyone uses daily, but on tasks like AIME, MATH, GPQA, and coding, it either surpassed or approached the competition. It only fell slightly short on CodeForces, which is still somewhat tricky.
This method relies entirely on pure RL, without using any SFT data. For those who train models, this is an unimaginable breakthrough — pulling yourself up by your own bootstraps.
The paper doesn't disclose the exact number, but I estimate RL ran for roughly ten thousand steps. Compared to the high cost of pre-training, RL is much cheaper — both in my estimation and based on consultations with many others. If you already have a strong base model, this RL approach can rapidly boost model capabilities at low cost.
R1 Zero was on the right track, but the DeepSeek team then identified several issues. First, poor readability. Second, frequent language mixing — similar to how Shanghai white-collar expats talk: "Maria, today's schedule is a bit packed."
This problem isn't unique to R1 Zero; most reasoning models exhibit this language mixing.
There's a recent meme you may have seen. Some foreign netizens screenshotted o3's reasoning process and found that when asked a question in English, o3 was reasoning in Chinese. While those of us in the know understand what's really happening, many foreign netizens still screenshotted and @'d Sam Altman, asking whether they were distilling DeepSeek R1. What goes around comes around.
The reason behind this is simple. When the model explores on its own, Chinese and English are just tokens to it. It processes problems token by token when thinking, without caring whether humans can read it. This is fundamentally a language mixing issue.
The second point is that its formatting was somewhat chaotic. By now, ChatGPT and Claude users are accustomed to beautifully formatted Markdown output, with bullets and clean structure. But look at R1 Zero's output — because it focuses solely on solving reasoning problems, its readability is relatively poor.
To address this, they needed to make the reasoning process more readable and shareable with the community. So they continued building on R1 Zero to create R1 with better readability.
But honestly, the most essential work was already covered: boosting model capability by pulling yourself up by your own bootstraps.
For researchers, what they care about most is R1 Zero, though the subsequent process of building R1 is also quite interesting.
05
Reproducing DeepSeek R1's "Aha Moment"
Now let's see how R1 came about. DeepSeek sharing this process truly is, as Marc Andreessen put it, "a gift to humanity."
The pure RL process described earlier — once you grasp the principles, anyone can attempt it. But that doesn't mean you'll actually produce R1.
First, since they already had a powerful R1 Zero as a foundation, training R1 didn't require starting from scratch. They used R1 Zero to generate the high-quality SFT data on the right — the cold start data. These were high-quality examples with reasoning traces, output by R1 Zero, used to re-SFT the DeepSeek V3 base model.
You'll notice something quite magical: V3 base enabled the birth of R1, while R1's powerful reasoning capability in turn went back to SFT V3.
Yet another bootstrap. This not only made R1 stronger but also improved V3. For example, the checkpoints trained with cold start data — each small dot represents a checkpoint, essentially a "save file" at a certain stage of training.
The first checkpoint was SFT with R1 Zero's high-quality cold start data, completing a fine-tuning. Then they took this checkpoint and ran something similar to R1 Zero's reinforcement learning. But with some differences. Beyond rewarding accuracy and format, they added a new reward component — consistency.
Consistency refers to language consistency. That is, during this RL process, they didn't just ensure answer accuracy and formatting; they also checked whether the reasoning process contained language mixing. If Chinese and English were mixed, it received a zero; if it used Chinese or English throughout, it received a high score. Just this one added reward.
After this step, they obtained the second checkpoint. This version not only had strong reasoning capabilities but also eliminated language mixing. They used this version to generate a second round of high-quality CoT data. This CoT data was better quality than the earlier cold start, mainly because its reasoning process was linguistically unified.
Finally, through manual curation and rule-based filtering, they removed redundant and low-readability portions, obtaining a curated and optimized high-quality CoT dataset. Remember this data — it serves additional purposes later.
The earlier RL process covered math, physics, coding, and similar tasks. But their goal was to eventually deploy this model to the broader open community. It needed to answer simple arithmetic like "1 + 1 = 2" or common knowledge like "The capital of China is Beijing."
So they extracted from the already RL-enhanced V3 base the general-knowledge SFT data shown on the right. This was merged with the earlier high-quality CoT data for a final round of reinforcement learning. This RL process more closely resembled typical model training, incorporating human preference — our preferences regarding output format, content, and so on. The resulting model is the DeepSeek R1 everyone uses now.
Why do I consider this process so important? Because through the model's training trajectory, we can see the transformation from R1 Zero to R1.
This is their exploration path. Without their explanation, you might pursue many different exploration paths and not necessarily succeed.
But DeepSeek detailed the training process from R1 Zero to R1 in their paper. You can see how they constructed cold start data, how they prepared for reasoning-oriented reinforcement learning, how they prepared high-quality reasoning data and general knowledge data, and how they conducted RL training to make the model applicable across scenarios rather than limited to math and coding. They wrote it all out in great detail — extremely helpful for researchers hoping to reproduce this work.
After completing step two and obtaining R1, we can examine R1's performance. Across all scores, except for GPQA where it still slightly trails OpenAI o1-0912, it has comprehensively surpassed the o-series models in other areas, even achieving very strong results on CodeForces. This is the power of SFT plus RL — the model has reached a new height.
Next comes step three, which I consider a breakthrough in DeepSeek R1's work — one that had particularly significant impact in academic and tech circles. If they had stopped at the first two steps, the work would already have been important, but without step three, the odds of breaking out of niche circles would have been much lower.
Up to this point, the work was already remarkably complete and the paper itself highly valuable, but DeepSeek went further. They took the high-quality CoT data generated from intermediate checkpoints — from R1 Zero through to R1 — combined it with V3's general world-knowledge data, and instead of fine-tuning their own V3, they fine-tuned other people's models.
They wanted to test a question: even though other models hadn't done RL, hadn't done pure reinforcement learning, could they learn this reasoning process through DeepSeek's high-quality reasoning data? They not only tested this but ran experiments and published the results.
This produced a fascinating effect: they used this high-quality data to distill other models, such as Qwen. From 1.5B to 32B, Qwen certainly has significant influence in China, but to break through to broader audiences, Qwen alone wasn't enough — they also distilled Llama. This was essentially "humiliating" Llama, haha, because after distillation with the same high-quality data, Llama 70B performed on some tasks roughly on par with Qwen 32B, very close.
So what's the significance of this work? First, DeepSeek didn't just complete their own research — they proved something to the world: the cost of SFT using data generated by a large-scale, high-quality reasoning model is extremely low compared to traditional pre-training methods. It makes existing models' performance skyrocket without needing RL.
Another important significance of this work: it showed people the possibility of reproducing these results on their own computers.
Not every researcher in the tech community has eight A100s at home. To reproduce a result, people just pull it down via LM Studio or Ollama, deploy and run it locally — it's easy to compare the original and distilled versions. Very quickly you discover "wow, this Chinese team is really impressive." This was a crucial reason for the massive breakout.
06
Two Unsuccessful Attempts
DeepSeek also mentioned two unsuccessful attempts in their paper: PRM and MCTS.
They found PRM extremely difficult to define and score. If the reasoning process contains 800 characters, how do you break it into steps? How do you score each step? Sometimes you start off wrong, and later precisely because you went wrong, you arrive at the correct answer. How to evaluate each step's contribution became a massive challenge. This made PRM uncontrollable in terms of both funding and time costs, so they concluded it wasn't viable.
The other issue was MCTS. While people don't need deep familiarity with MCTS, one point worth sharing is why MCTS is so difficult in language models. Simply put, MCTS's core premise is that each step's search space is limited. Take AlphaGo: the board has finite spaces where stones can be placed, so each move's options are bounded. While extended sequences may have infinite possibilities, each individual step's choice space is finite.
In large language models, every reasoning step can draw from the entire vocabulary — there are no Go-like rules. So when you try to apply MCTS to language models, the search space becomes wildly uncontrollable, and it's equally hard to define a reward model.
They didn't completely rule it out in the paper — "we couldn't figure it out doesn't mean it's impossible, but you know how it goes, put your money where your mouth is." For the time being, anyone with a successful version would have already pivoted to ORM.
They also did some additional minor work using high-quality data to SFT other models. So people might ask: since they used high-quality CoT data for SFT, why not directly use their R1 Zero training approach — pure reinforcement learning — to train other models?
DeepSeek considered this too, and ran experiments. They selected Qwen 32B as the base model and applied the same pure RL training method as R1 Zero, but found no significant improvement.
As you can see, there's a large performance gap between Qwen 32B trained with pure RL and Qwen 32B that used CoT data for SFT.
This experiment led them to a conclusion: pulling yourself up by your bootstraps still requires a foundation.
This principle is actually easy to understand. As Peak pointed out to me: don't think of reasoning as human thinking — reasoning is still next-token prediction, just producing longer CoT that gives it more room to err, to search, to think, and thereby arrive at correct answers.
For example, if you lock a second-grader in a room with an advanced calculus problem and tell them to think for a month, they'll never solve it. So pure RL has requirements for the base model.
Why does this lead to the next climax? We've been talking about R1, but R1's entire starting point is DeepSeek V3. That 671B MoE model.
We can't get around this model — R1 didn't bootstrap itself into the stratosphere on its own. Without this powerful base model, DeepSeek couldn't have produced their current work. Earlier I mentioned why k1.5 didn't achieve the same breakthrough as DeepSeek — I don't know the inside story, and though Kimi didn't open-source either, perhaps Kimi's base model didn't reach V3's level. That's possible.
Next, we enter today's second climax.
07
Rome Wasn't Built in a Day
Rome wasn't built in a day either. While DeepSeek's breakout attracted widespread attention, some narratives made it sound like this was some side project from a Chinese quant fund that just "casually" produced these results.
While that narrative fits Hollywood's style, if you take this work seriously, you'll find it's extremely rigorous.
DeepSeek is a company seriously pursuing AGI and model research, with many long-term investments and contributions that extend far beyond R1.
Rome wasn't built in a day, but we can see how it was built.
But behind it lie many critical supports. Last February, DeepSeek released DeepSeekMath, introducing GRPO for mathematical problem-solving. GRPO's advantage is efficiency, but it mainly handles tasks with clear, well-defined answers and strong patterns — math and physics problems, for instance. So in DeepSeekMath, GRPO was used to dramatically reduce RL's computational costs. The paper was actually published in 2023; the model was open-sourced in February.
In May, DeepSeek released DeepSeek V2 — this was the starting point for everything. Because V2 introduced DeepSeekMoE and MLA. Then in December, they released V3, introducing FP8 and MTP as training and inference methods. All of these laid the RL foundation for building a powerful V3 model.
Now let's look at DeepSeekMoE's advantages. MoE stands for Mixture of Experts. Simply put, MoE solves a critical problem: as models scale larger, training difficulty increases dramatically.
As everyone knows, models are essentially massive collections of matrices storing enormous quantities of numbers.
Every time you train on a single token, you have to run through the entire thing from start to finish — the computation and data volume are too large, training gets slower and slower, increasingly prone to collapse. Very easy to crash. The MoE concept actually dates back quite far — it's an old idea. But in recent years, the first to bring it back to industry attention was Mistral, a European team with their 8×7B MoE model.
They discovered that you don't need to activate the entire model for every training or inference step. In fact, you can make the model very large — say, 8×7B — but only activate one expert each time, meaning only 7B is active per pass. This way, both training and inference costs decrease, and training becomes less prone to crashing.
These were prior explorations — 8×7B, 8×22B, and so on, plus Tencent's Hunyuan model released late last year, a roughly 300B MoE model. While all these explorations were valuable, one problem with MoE was that the number of experts was usually insufficient. Mistral's 8×7B and 8×22B models both had 8 experts — the sparsity wasn't enough, and total size was difficult to push further.
DeepSeekMoE made significant innovations in V2.
First, the V2 model was already massive — 236B parameters, with only 21B activated per pass. By V3, this had scaled to 671B, the largest MoE model to date, with 37B activated per pass.
Many people look down on MoE models, thinking they're what you do when you can't train a big model anymore — just train a bunch of small ones instead, "three cobblers equal one Zhuge Liang." But that's not what MoE is.
Most people think of MoE as having 8 experts, and during training you pick one expert to answer each question. That's not how it works. The model has many layers, and each layer has many experts. In DeepSeek MoE V3, each layer has 256 blocks, across many layers, and tokens get routed to different blocks at each layer. So a token passes through multiple different experts across multiple layers inside the model — the name "expert" is actually somewhat misleading.
The innovation in DeepSeek V2 and V3 is that instead of simply using a router algorithm to directly dispatch tokens to experts, they added something before each token reaches the experts: one layer in V2, three FFN layers in V3 — essentially small models. These small models can understand concepts in latent space, enhancing the model's intelligent processing capabilities.
MoE can also be analogized to a hospital triage desk. In the past, all patients had to see a general practitioner first, which was inefficient. An MoE model is like having a triage desk that routes patients to different specialists. DeepSeek innovated here too — previously the triage might have been done by a "security guard" with zero medical knowledge, but they used an "undergraduate" with medical training for the routing task.
DeepSeek also introduced the concept of shared experts (shown in green in the diagram) — shared experts at every layer are always activated. Some general-purpose capabilities are shared across the board.
They also designed a crude but practical router algorithm, and an extremely efficient cross-node communication solution using NVIDIA's InfiniBand and NVLink.
All of these innovations are remarkable. The field had been exploring MoE for over a year, but no one had done things at this scale. And they trained V3 in one shot without it crashing — a major reason they could complete training at a cost of just over 5 million dollars.
Next is MLA. MLA is more algorithmic.
As you know, MHA in Transformers consumes a lot of VRAM, but besides model weights, 30-40% of memory is used for context — much of it through KV cache.
MLA trades time for space. Training takes longer, but it compresses what was originally an m×n matrix into a one-dimensional LoRA, with extremely high compression. This makes KV smaller during inference, allowing more context to be held. Not only does the compressed size enable more inference context, but testing showed that compared to MHA, intellectual performance didn't degrade — it actually improved.
Finally, DeepSeek introduced FP8 training in V3. Traditional training uses both 16-bit and 32-bit floating point, while FP8 is 8-bit floating point. Everyone thinks 8-bit floating point has too shallow precision. But most teams can't make it work. You can do 8-bit floating point operations, but which parts can you use it for? There's no way to know. You might switch to 8-bit in one place, and it crashes later, with no idea what caused it.
The DeepSeek team was the first to actually implement FP8 mixed-precision training at such massive scale. This is hard to imagine. And the stability was excellent.
What's the significance of this work? It doesn't just reduce computation and transmission — there's another important benefit. Anyone who's actually deployed their own model knows that we rarely deploy the full-size original model directly. We usually quantize it to reduce storage and computation needs, so it can run on lower-spec devices.
One advantage of FP8 training is that since it already uses FP8 during training, compared to models that originally used 16-bit computation and were later quantized to 8-bit, FP8 training makes the model natively FP8 — inherently better than post-hoc 8-bit quantization. This brings significant performance improvements.
Next is MTP (Multi-Token Prediction), a very interesting concept that took Peak quite a while to explain to me. MTP, or multi-token prediction, aims to let the model see further ahead during inference. As you know, Transformers use single-token prediction (Next Token Prediction) — predicting just one token at a time.
But academia proposed a new idea: what if during prediction, instead of just guessing the next token, the model simultaneously predicted the next two, three, or even four tokens? Would this let the model learn more globally optimal strategies during training?
Specifically, while a given token might have the highest probability and be optimal in the current context, if the model chooses based only on local information, it might lead to poor predictions for subsequent tokens further out. If the model can see further into the future, it can optimize the overall strategy during training, becoming more intelligent. This is the basic principle of MTP training — essentially giving the model stronger long-term planning capability.
At the same time, MTP brings an important benefit: inference efficiency. Since the model learned this prediction method during training, it can generate multiple tokens at once during inference. In DeepSeek V3's research, MTP enabled generating two tokens simultaneously.
Of course, there were similar techniques before, like Speculative Decoding. But that required an additional small model — say a 7B model — to speculate tokens first, which a 70B model would then verify. MTP does this directly within the same model, with no extra small model needed.
What I said in my first sentence: this is an obsessive pursuit of innovation. Why? Because in terms of returns, besides inference efficiency gains, the performance benefits aren't actually that significant. But this represents a very distinctive characteristic of the DeepSeek team — they really want to take on new challenges.
Like everything I just showed you — any single piece of this could be a high-quality paper on its own.
V3 has so much of this. Just the table of contents would blow your mind. I've only selected some of the technical highlights. And the quality of V3 is extraordinary — from idea conception to experimental design to how the engineering, software, and hardware were implemented, everything is explained with great clarity.
Actually, R1 was quick to read through, not much content, you grasp it quickly. But V3 takes a very, very long time to get through, and it's absolutely fascinating. The fun of V3 goes far beyond this.
But why did I single out FP8 and the new MoE architecture and other techniques?
Let's review the key terms: What are shared experts? Why choose a crude router method? Why not use previous routing algorithms? Why push cross-node communication efficiency to the extreme? Why make so many assembly-level changes at the底层? Why reduce activation memory during training? Why reduce KV cache? Why reduce computation and transmission?
All these engineering optimizations point to one goal — no cards.
Look — what's the biggest difference between H800 and H100? Did you notice? Interconnect bandwidth. H100 has bidirectional 900G interconnect bandwidth, while H800 only has 400G — half the speed.
And as you know, each node has 8 cards, and many nodes need to be connected together via IB or RoCE, with nodes using NVLink to transfer data. If you're already twice as slow as H100 within a node, you're in a tough spot.
You’ll notice that every engineering optimization they made — memory compression, VRAM reduction, communication overhead cuts — each one delivers maybe a 10% to 20% improvement. Add them all up, and they’re basically compensating for insufficient NVLink bandwidth.
I also read a brilliant article at the time: Ben Thompson’s explainer on DeepSeek for American audiences. He made a point that stuck with me — if you really dig into how V3 was implemented, you can’t help but conclude that this company simply doesn’t have that many high-end GPUs. Otherwise, why go through all these convoluted engineering gymnastics?
What’s particularly interesting is that when I was preparing for this talk, I noticed the article mentioned an NVLink speed of 160G per second, not the H800’s 400G. That piqued my curiosity, so I checked GitHub and found someone had raised a similar question: “Why is your NVLink speed 160G instead of 400G?”
Eventually, someone from High-Flyer responded: “400G is the bidirectional theoretical value; 160G is the unidirectional measured value.” This confirms they were actually working with H800s, still hitting the physical bandwidth ceiling.
The entire DeepSeek MoE architecture from V2, including the framework implementation after V3, was designed to reduce computation and communication bandwidth so they could run experiments on the hardware they had.
Because as everyone knows, training is just the final lap — researchers need to run countless experiments day-to-day, and high-end GPU supply is tight. Read that paper closely, and you’ll see they were genuinely constrained by these practical difficulties.
08
R1’s Breakthrough, Future, and Product Thinking
Now let’s talk about how R1 “broke through” and what lies ahead.
First, I believe R1’s breakthrough rests on genuine capability. Its performance is simply that strong — no need to oversell it. Those who’ve used it, know. You get it.
Second, it solved a problem that had been tormenting the entire industry. Everyone was grinding away at PRM, MCTS, failing and frustrated, and R1 just showed up saying “none of that suffering is necessary.”
Third, when you read the R1 research, you’re struck by its ingenuity — you’d never think to do it this way. Then the more you read, the more you discover V3 lurking underneath, and it all clicks: ah, that’s how.
Fourth, it exhaustively tested every direction researchers might want to explore. R1 didn’t just improve itself through its research — it demonstrated that with high-quality CoT training, your model can be great too. And it made clear: don’t think you can simply copy me. If your base model is weak, you’re out of luck.
If you’re a researcher or at an LLM company, you feel like this thing is reading your mind, addressing your exact pain points.
It’s fully open-source, with a consumer-facing product to boot. All these factors together created the foundation for R1’s breakout — this is real, earned strength.
R1’s future also sets a promising tone for the global AI industry in 2025.
First, their distillation experiments proved that high-quality reasoning CoT can unlock capabilities in existing models. It’s actually quite simple — not that complicated. Much existing work just needs to be redone to see immediate gains.
Second, R1 only proved the feasibility of “pulling yourself up by your own bootstraps” — that was their first innovation. Think back to all paradigm-level breakthroughs, like the evolution from o1 to o3. The R1 team may well deliver more breakthroughs in RL over the coming months to half-year.
Third, global AI Infra finally has something to do. AI Infra hadn’t really taken off largely because there were no models worth deploying. Just imagine if OpenAI had open-sourced — global AI Infra would look completely different. Recently, AI Infra has been on fire.
Fourth, while R1 experimented with RL, they haven’t yet done controlled inference-time scaling. Look at o3 — clunky naming aside (“think more,” “think normally,” “think less”). R1 hasn’t done this yet, and performance gains from doing so are to be expected.
Finally, the “long2short” concept strikes me as very interesting. We shouldn’t treat the reasoning process as some side channel of thought — it’s part of Next Token Prediction itself, and longer isn’t necessarily better. When reasoning seems unnecessarily long now, that’s actually a sign of insufficient training efficiency. k1.5 explores this further. Going forward, long2short reasoning will become more efficient — quickly arriving at what needs to be thought about.
Of course, I asked Peak: “Could it one day become so short there’s no reasoning at all?” He said that’s unlikely, because models still need more tokens to think. So reasoning compression will hit a limit, but won’t disappear entirely. o3 mini is exploring this boundary. These may materialize in future models, and R1 is walking this path.
Speaking of which, I hope you still remember my actual job is building products. Today I also want to share how R1 has influenced my product thinking.
First, a crucial reason R1 achieved what it has is that it seized a perfect timing gap. When o1 launched, very few people globally could actually use it — o1 was paid and not cheap. DeepSeek chose to make it free and open, letting everyone use it directly. This meant that for many people, their first contact with a reasoning model wasn’t ChatGPT’s o1, but DeepSeek’s R1. That zero-to-one experience was genuinely stunning.
Additionally, for users who had tried o1 — which at the time didn’t support search — using DeepSeek R1 felt incredibly satisfying because it combined reasoning with search, dramatically expanding the use case. DeepSeek R1’s launch timing hit a remarkably clever window.
For all users, R1 was a fresh experience, a zero-to-one moment. Every user who tried it became a loyal advocate — organic evangelists. That’s why during that period, I found those “Chinese bot army” accusations particularly contemptible. I thought, my god, just go look at real American user feedback on Twitter — their screenshots and use cases are concrete and genuine. This isn’t something bots can manufacture. It’s extreme product value, users voting with their feet to express authentic sentiment. Through that two-week hype cycle, beyond media coverage, genuine user expression was remarkably sincere and powerful.
This also brought me a major realization: ChatGPT is not the end state. Many people think OpenAI has done so well, ChatGPT is so capable — how could it possibly be surpassed? I’ve been hammering this point throughout my year and a half in AI work.
Right now, AI penetration is only 5%. For the remaining 95%, what will their first AI application be?
Many people don’t dare ask this. Many assume ChatGPT is the ceiling — how do you even catch up? But DeepSeek R1 shows us that you can actually bypass ChatGPT entirely and open up a completely new market. ChatGPT has only reached 5% of people on Earth. I can absolutely target another 5% or 10% and give them their first AI experience. What would that be?
Right now it’s reasoning models. I believe this space will keep expanding, with many domains seeing shifts similar to last year.
Sora was hyped for a year, but the real results were captured by Keling AI and Hailuo — similar stories. So don’t assume competition in any domain is settled. It’s never too late to get in.
Third, the reason R1 + Search became so popular is fundamentally that it’s a very simple Agent Framework. However powerful R1’s reasoning model is, it’s still confined to internal monologue — it can’t access the external world.
When you add Search, it gains observation of the external world, and that’s what truly makes the R1 + Search experience distinctive. This is something many people, including our peers, overlooked when analyzing R1. They assumed R1 was powerful because it’s a reasoning model, and since their company lacks a reasoning model, their product can’t succeed. But without Search, R1’s global impact might have been fundamentally different — with or without Search is a qualitative distinction.
This leads us to ask: If R1 is already open-source and has added Search, why can’t it add more?
Perhaps R1 + Search is just the starting point. Adding more external observations could produce qualitatively different model behavior. What exactly that looks like, the industry will need to explore together. But I find it enormously inspiring for product design.
For the final section, I was going to say “addressing” rumors, but I’m not DeepSeek — I can’t address them. So I’ll just “clap back” instead. First, this so-called “full-power R1.” This started with some American companies setting a bad precedent. Groq, for instance — you know Groq, the company that builds hardware architectures to accelerate LLM inference.
After R1 came out, Groq's CEO quickly posted on Twitter that their DeepSeek R1 inference speed was many times faster than the official implementation. At the time, I thought, isn't Groq's architecture supposed to be pretty inflexible? And theoretically, their hardware architecture should be tightly coupled with Llama — how could it support an MoE model this large? I was quite curious. After looking into it carefully, I discovered that Groq had actually deployed a DeepSeek R1 Distill Llama 70B version.
It's truly hard to imagine a company CEO doing something like this. Since then, many platforms started spreading similar stories. Some deployed a Qwen 32B model and claimed they were running R1. When people found the results underwhelming, others would reply that they weren't using the "full-power version." But R1 doesn't have a "full-power version." R1 has only ever had one version: R1. The other Distill versions are not R1. There's a massive gap between the real R1 and the Distill versions.
The second rumor is the classic "6 million dollar training cost." I've explained this repeatedly to many people. We can look at the V3 paper, where they mention using 2.788 million H800 hours in total.
If we calculate at roughly $2 per hour for H800 rental — a bit high by current standards — the single training run for V3 comes to about $5.57 million. They also specifically emphasized that this training cost only covers the final training run. Because their engineering design was so clever and stable, they got it right on the first try without any large-scale training collapses.
As for the 6 million estimate, it doesn't include prior research, ablation studies, architecture exploration, algorithm exploration, or data preparation. Calculating only the single training run cost is standard practice in both academia and industry. This cost can't be hidden anyway — the model's parameter count is right there, and the training tokens are 17.6T. Anyone who knows their stuff can roughly estimate the training cost just from the model scale and dataset size.
DeepSeek's framing itself is completely unproblematic, and they explicitly noted in their paper what was excluded. From DeepSeek's own perspective, they didn't do anything deceptive.
What happened is simply that this broke out of tech circles too fast and spread too wide. The involvement of large numbers of non-industry media outlets and KOLs tends to generate traffic-driven narratives, and these narratives inevitably center on "money," "people," and "geopolitical conflict." The easiest way to manufacture viral topics is to stoke these emotions, which led many people to fixate on the 6 million dollar training cost, generate hype, and eventually make rational discussion impossible.
Also, regarding Alexandr Wang's claim of 50,000 H100s.
But the source above is actually SemiAnalysis, and this result is fairly balanced. In the lower left corner of the image is October 7, 2022 — the first U.S. export ban, when H800s could still be purchased.
January 13, 2025, after the second export ban, H800s also entered the restricted category. For DeepSeek, their H800 purchases were completed in compliance before January 13. The figures (10,000 A100s, 10,000 H100s, and 10,000 H800s) are relatively consistent with reality; after that, they could only purchase compliant H20 cards.
Going back to V3, we discussed a lot of engineering optimizations and clever tricks. If they actually had that many H100s, there would have been no need for any of these optimizations.
Also, regarding the 9.9-yuan paid local deployment offers circulating on Xiaohongshu and TikTok — I think after today's talk, everyone should understand that unless you literally have a mine at home and own 8 A100s, local deployment is practically impossible. Many of the so-called "local deployment" offerings are actually just distilled models, like Qwen 1.5B, 7B, or 32B versions. Many computers can't even run 32B; it's probably the 7B distilled version. I was originally very opposed to local deployment, thinking it was deceptive. But then I reconsidered — maybe it's an opportunity for many people to learn how to run LLMs on their own computers. That might actually be a pretty good thing.
Now, about distillation and theft. I had prepared a long speech, especially on the point that if you're alleging distillation, the burden of proof lies with the accuser, not with me to respond. I'm not a professional; I can't speak for OpenAI or DeepSeek, so responding feels rather futile.
Until yesterday, while studying V3, I came across an unexpected discovery. Remember on December 26, when Andrej Karpathy retweeted the V3 paper? Under his retweet, an American guy jumped in saying he used this model, and the model claimed to be ChatGPT, with screenshots to prove it.
Andrej Karpathy himself responded to this. He said: there's simply no need to do this kind of thing. Asking a model who it is is meaningless. When you ask a model "who are you," you've fallen into the trap of "over-anthropomorphization."
Non-practitioners tend to view ChatGPT as too intelligent, believing it has its own consciousness and knows who it is. But in reality, all models — whether pre-trained or otherwise — have no concept of "who I am" whatsoever. Their answers of "I am ChatGPT" or "I am OpenAI" are simply response patterns we designed into them during data training.
Because by the time DeepSeek trained V3, there was already a lot of data in the world containing the keyword "ChatGPT," so when the model was asked "who are you," it would give answers like "ChatGPT." From a probability distribution perspective, you pick the highest-probability response.
This problem isn't unsolvable. After pre-training, all models undergo alignment training where self-identity is adjusted. If DeepSeek wanted to make this adjustment, they could absolutely do so through continuous alignment data, teaching the model to answer "I am the DeepSeek large model, I am DeepSeek V3" when asked "who are you."
My view on this issue is that AK's response was already excellent. If anyone ever brings you a screenshot claiming some model is OpenAI, you just throw AK's response at them. AK's perspective is more persuasive than anyone's.
Before tremendous innovation, all these clownish antics look simply ridiculous. The noise will gradually fade with time.
But I believe papers like DeepSeek's V2, V3, and R1 will continue to have impact. That beauty of creation — if you just experience it, understand it, you will certainly feel it. It is extraordinarily beautiful.
Just as when we studied Stable Diffusion last year, those papers were already old, but looking back now, they still feel incredibly beautiful.
That's all for today's sharing. Thank you, everyone!
Recommended Reading