KernelCAT Released: Agent Automation Enables Domestic Chip Adaptation and Compute Acceleration

From relying on existing ecosystems to building self-evolving computational foundations.
China's domestic computing infrastructure has entered its second half. The focus is shifting from "quantity growth" in chips to "efficiency gains." Domestic chip volumes keep climbing, yet ecosystem development still lags behind — this is the most honest snapshot of AI deployment today.
Models keep breaking parameter records, while the underlying stack struggles to pivot.
Harder than the rotating parade of parameter benchmarks is changing the rigid workflows developers actually use. Compute is merely the threshold; the real contest lies in the synergy between algorithms and hardware.

KernelCAT: A Kernel-Level Compute Acceleration Agent
Nearly everyone feels the acceleration in AI — dense model releases, climbing application metrics. But on real engineering floors, the feeling is more complicated: what actually constrains deployment efficiency isn't model capability itself, but the maturity of the underlying software ecosystem.
More hardware choices, yet problems concentrate and surface: high migration costs, long adaptation cycles, unstable performance release. Many models that technically could switch compute platforms ultimately get blocked at the door by operator support and toolchain completeness.
This makes one fact increasingly clear. The breakthrough isn't stacking more compute, but bridging that most easily overlooked engineering link between algorithm and hardware — converting a chip's theoretical performance into actual usable performance.
The most critical link in this chain is high-performance kernel development.
A kernel operator connects AI algorithms to compute chips, translating algorithms into hardware-executable instructions. It determines an AI model's inference speed, power consumption, and compatibility.
Kernel development is kernel-level programming, yet the industry's status quo remains heavily dependent on individual experience. It relies intensely on top experts' intuition and muscle memory; performance tuning often feels like blind testing in fog, with protracted cycles.
But what if AI developed kernels?
Traditional large models or knowledge-augmented agents often fall short on such tasks. They excel at pattern matching, yet struggle to understand the physical constraints, memory layouts, and parallel scheduling logic within complex compute tasks. Only by moving beyond empirical reasoning and deeply modeling a problem's essence can true "intelligence-level" optimization be achieved.
It was against this severe technical challenge that KernelCAT emerged.
KernelCAT Terminal Agent
KernelCAT is a locally-run AI Agent. It is not only a "compute acceleration expert" deeply versed in kernel development and model migration, but also capable of general full-stack development tasks, offering developers both a CLI terminal version and a streamlined desktop version.
Unlike tool-type agents focused narrowly on specific tasks, KernelCAT possesses solid general programming capabilities.
It can understand, generate, and optimize kernel-level code, while also handling routine software engineering tasks — environment configuration, dependency management, error diagnosis, script writing — thereby achieving end-to-end autonomous closure in complex scenarios.
KernelCAT Desktop Agent

Writing High-Performance Kernels for the Domestic Chip Ecosystem
In kernel development, one class of problems resembles "hyperparameter tuning." Facing dozens or hundreds of parameter or strategy combinations, engineers need to find the configuration that makes a kernel run fastest.
Traditional approaches rely on experiential trial-and-error — time-consuming, laborious, and prone to pitfalls. KernelCAT's approach: introduce operations research optimization, hand the "finding optimal parameters" task to algorithms, and let algorithms explore the tuning space and converge on the best solution.
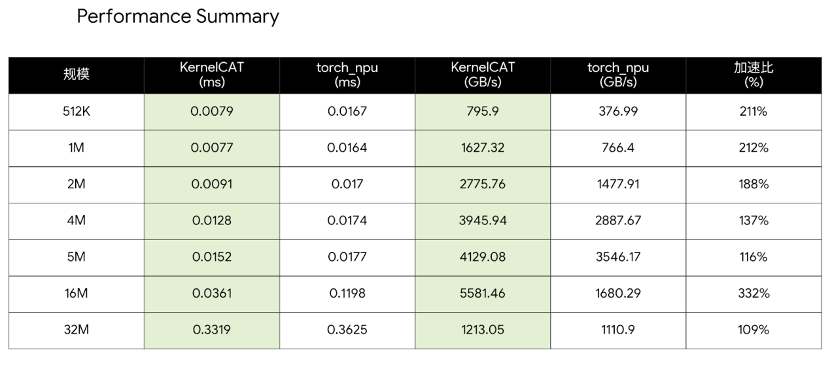
Take the FlashAttentionScore kernel on Huawei's Ascend chips as an example. KernelCAT can automatically construct an operations research model for this kernel's tiling parameter tuning problem based on Huawei's official sample code, then solve it using mathematical optimization algorithms. After just over a dozen iterations, it locks in the optimal configuration, achieving latency reductions of up to 22% and throughput improvements of nearly 30% across multiple input sizes — all without human intervention.
This is precisely KernelCAT's distinctive quality. It possesses not only the intelligence of large models to understand code and generate solutions, but also the rigor of operations research algorithms to systematically search and converge on optimal solutions.
The combination of intelligence and algorithms makes kernel tuning both flexible and delivery-guaranteed.
In another test of KernelCAT, the team selected seven vector addition tasks at different scales, with a clear objective: directly comparing execution efficiency on Huawei's Ascend platform among Huawei's open-source kernels, "black-box" commercial kernels, and KernelCAT's self-developed kernel implementations.
The results were equally encouraging. Across all seven test scales in this case, KernelCAT's kernel versions achieved performance leadership, with task completion taking only 10 minutes. This means that even against commercially-tuned closed-source implementations, KernelCAT's optimization approach retains competitive strength.
This is not merely a numerical victory, but a self-certification by a domestic AI Agent in the kernel domain.

No Ecosystem Is Impregnable, Including CUDA
Globally, over 90% of major AI training tasks currently run on NVIDIA GPUs, with inference share also exceeding 80%; its developer ecosystem covers over 5.9 million users, its kernel library exceeds 400 operators, and it is deeply embedded in the implementation workflows of 90% of top AI academic papers.
Jensen Huang once said: "We founded NVIDIA to accelerate software; chip design was secondary."
In modern computing systems, software is the true moat. NVIDIA's sustained leadership stems from its full-stack control capability, starting from底层算法 and running through architecture and programming models.
Referencing AMD's historical experience, even with ample competitiveness in architecture and process technology, lacking a mature ecosystem still makes it difficult to shake NVIDIA's position.
Such cases clearly demonstrate that model performance does not simply equate to compute scale stacking, but depends on the degree of synergy among algorithm design, kernel implementation, and hardware characteristics. Only when kernels are sufficiently mature can hardware potential be truly unleashed.
Following this logic, the KernelCAT team conducted systematic engineering exploration around efficient model migration to domestic compute platforms. Taking deployment of the DeepSeek-OCR-2 model on Huawei's Ascend 910B2 NPU as an example, KernelCAT demonstrated an entirely new working paradigm:
-
Combating "dependency hell": KernelCAT possesses deep understanding of task objectives and constraints. Based on DeepSeek-OCR-2's official CUDA implementation, through precise dependency identification and patch injection, it resolved the triangular deadlock of version interlocking among vLLM, torch, and torch_npu dependency libraries — forcibly building a stable production environment from scratch, enabling out-of-the-box model deployment when combined with a base Docker image.
-
Precise patching: It acutely identified that the original vLLM's MOE layer relied on CUDA-specific operations, versus the Ascend-native MOE implementation provided by vllm-ascend, and decisively performed call substitution through a plugin package — letting the model "speak its native language" on domestic chips.
-
Achieving 35x acceleration: After introducing the vllm-ascend native MOE implementation patch, vLLM's throughput under high concurrency soared to 550.45 toks/s, achieving 35x acceleration compared to the Transformers approach, with further optimization ongoing.
-
No heavy human involvement required: Under such complex task objectives, KernelCAT can plan and complete tasks autonomously, without R&D providing extensive prompt guidance for model operation.
With KernelCAT, adaptation work that originally required top engineering teams spending weeks can now be compressed to hours (including model download and environment build time).
Meanwhile, it enabled 35x acceleration on domestic chips. In other words, KernelCAT allows domestic chips to serve as performance engines for top-tier multimodal model inference tasks through deep engineering optimization.
What KernelCAT represents is not merely the emergence of a new AI Agent paradigm, but a shift in how底层 capabilities are built: from relying on existing ecosystems, to building computing foundations capable of self-evolution.

KernelCAT is currently in limited-time free beta. Welcome to experience it.
Click the original article link to jump to the product homepage.



