Moonshot AI's Yutong Zhang: The "1%" Exception Under the Capital-and-Compute Determinism | Tsinghua University Campus Talk

Seeking the optimal solution for converting energy into intelligence.
On November 30, ZhenFund hosted a sharing session on AI entrepreneurship. ZhenFund managing partner Yusen Dai joined Moonshot AI president Yutong Zhang, AIW founder Huaiting Zhang, and Manus co-founder Tao Zhang at Tsinghua University for an in-depth dialogue on innovation and the future.
On November 6, Moonshot AI released Kimi K2 Thinking. This is a new generation of open-source Thinking Agent trained on the "model as agent" philosophy, surpassing top closed-source models including GPT-5 and Sonnet 4.5 on benchmarks like HLE and BrowseComp to set new SOTA records. Starting in 2023 as a Tsinghua entrepreneurship team named after a Pink Floyd album, Moonshot AI has been continuously exploring the upper limits of intelligence.
Moonshot AI president Yutong Zhang oversees the company's overall strategy and commercialization. Previously an angel investor, she backed companies including Xiaohongshu, Infinigence AI, Black Lake, Liblib, Galaxea, and GravityXR. She earned her bachelor's degree from Tsinghua's Department of Electronic Engineering. Beginning with the release of Kimi K2 Thinking, she shared how the company's model performance, agent product experience, and team thinking have evolved over the past year. Even though Moonshot AI's valuation is just 1% of other overseas model companies, with 1% of their capital investment and 10% of their headcount, she remains convinced: "For a long time, the narrative that training models requires millions of GPUs and trillions of dollars has been a high wall built by mainstream storytelling. Startups need to return to fundamental technology and bet on innovation to rewrite the training paradigm."
She believes that "AI is not just an ordinary tool, but an amplifier of human civilization and a key to exploring future worlds." Moonshot AI has gathered people with "independent thinking and aesthetic judgment" and "a curiosity for pursuing truth," constantly experimenting with their ideas to bring truly good ones from research to large-scale deployment. ZhenFund invested in Moonshot AI's angel round in 2023, accompanying them on their journey to explore the dark side of the moon in technology.
Below is the full transcript of her sharing.

I'm very glad to be here today for ZhenFund's Tsinghua campus tour.
From the very beginning of Moonshot AI, we established our mission: to explore the upper limits of intelligence. If you were an early Kimi user, you might remember the line on our first webpage: "Seeking the optimal solution for converting energy into intelligence."
Today, I'd also like to take this opportunity to share what we've done around this statement.
There should also be quite a few users here today — has anyone tried the new model Kimi K2 Thinking that launched in November? The biggest feature of this model is that it can think while using tools. I think this also represents an important paradigm shift this year: AI products are moving from the past question-and-answer Chat format toward a more agentic experience — proactively breaking tasks down into multiple steps and then calling tools step by step to complete them. This is because the model itself now has this capability.

Model capabilities are still improving rapidly
In terms of agent and reasoning performance, Kimi K2 Thinking benchmarks against global SOTA models including GPT-5 and Claude Sonnet 4.5. Take Humanity's Last Exam, a benchmark composed of PhD-level cross-disciplinary problems requiring multi-step reasoning and tool use to find answers — Kimi K2 Thinking performs better. On other critical benchmarks like BrowseComp, which requires breaking down problems for extensive information retrieval, and the software engineering benchmark SWE-bench Verified, Kimi K2 Thinking is also highly competitive.
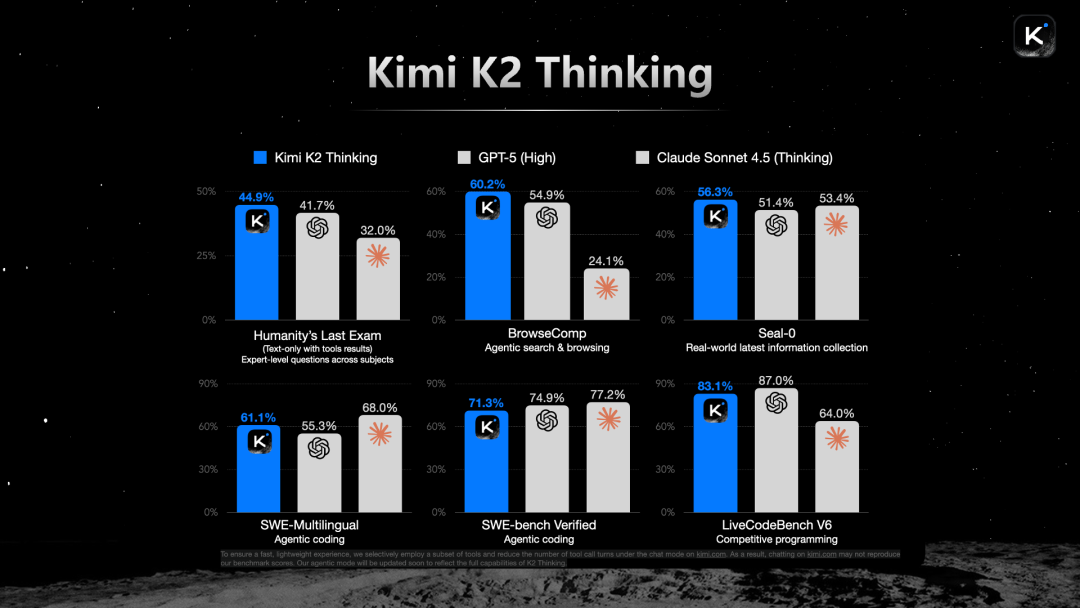
In July this year, we open-sourced the trillion-parameter Kimi K2 model for the first time. Because pre-training was done exceptionally well, it was called "big and beautiful." In September, we made another upgrade to agentic tool use and code performance. By November, in just two months, through continued strengthening of multi-step thinking and agent tool use capabilities, the K2 Thinking model made significant leaps on many benchmarks. This is also what excites us most about model development: it is still in a stage of rapid improvement.
We've also received extensive third-party benchmark feedback. On LMArena, a blind-test benchmark focused on actual model performance, Kimi K2 Thinking is the best-performing open-source model. In Stanford professor Percy Liang's HELM comprehensive evaluation, the Kimi K2 model achieved the best result for non-reasoning models when it was first released in July. More surprisingly to us, K2 also ranks very highly in creative writing capability and EQ-bench. I personally use K2 Thinking when I encounter difficulties in daily writing or replying to messages.
Beyond academic and industry benchmarks, we've also seen positive feedback from the developer ecosystem. Kimi K2 is very popular on Hugging Face. Vercel's founder and CEO posted on Twitter (X) that in their internal agent scenario testing, Kimi performed better than other closed-source models. Social Capital's CEO also shared on the All-In Podcast that companies they've invested in have shifted large amounts of work to K2 because of its strong performance and much lower cost compared to top closed-source models.
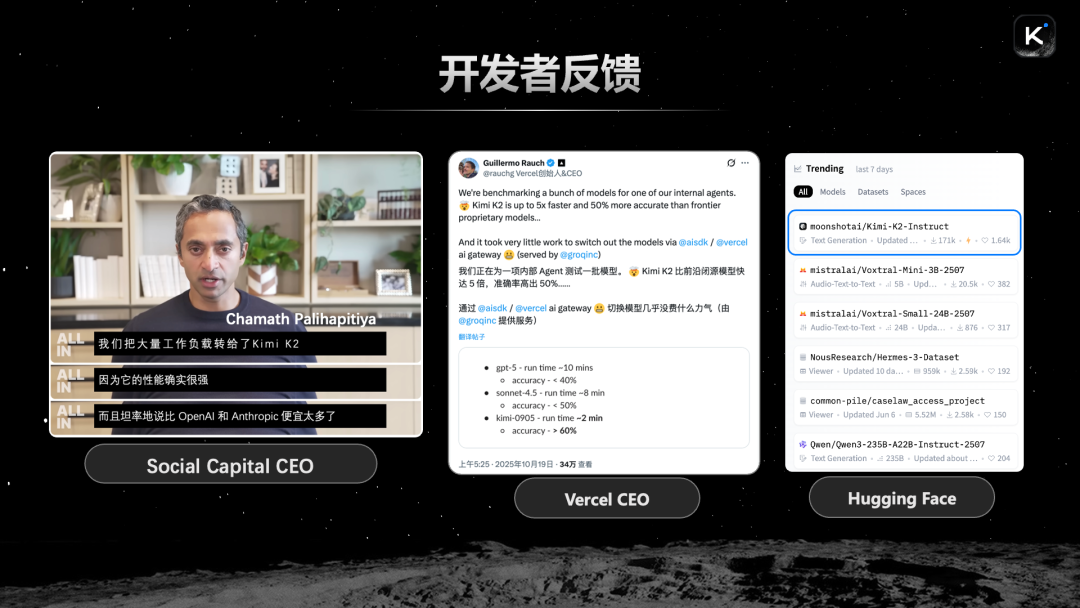
Additionally, we've seen some globally leading AI applications adopt Kimi K2. Perplexity, primarily an AI search application with tens of millions of active users and 280 million monthly site visits, now lists Kimi K2 Thinking as the only model alongside four closed-source models in its model selection. This validates our model's technical capabilities in search scenarios. Deep search and deep research in AI search are important scenarios where Kimi models excel — K2 Thinking supports up to 200-300 rounds of tool calls, thinking while using tools to complete complex research tasks.

The "1%" exception under the capital-compute determinism
The fact that model performance is still improving rapidly is something we're very excited about in our entrepreneurial journey. However, we've also found that for a long time, there's been an impression that AI model capability has a linear relationship with massive capital expenditure — that more powerful models necessarily require more capital investment.
Since starting Moonshot AI, we've constantly faced skepticism under this "capital-compute determinism" logic and narrative. Common voices in the industry say: "Without a million GPUs, you can't do large models at all — only the tech giants can." We're also frequently asked: "How many GPUs do you have? What models? Do you have your own data center?"
These questions themselves presuppose a very strong premise. But things get interesting when you gradually realize that compute resources aren't the only narrative.
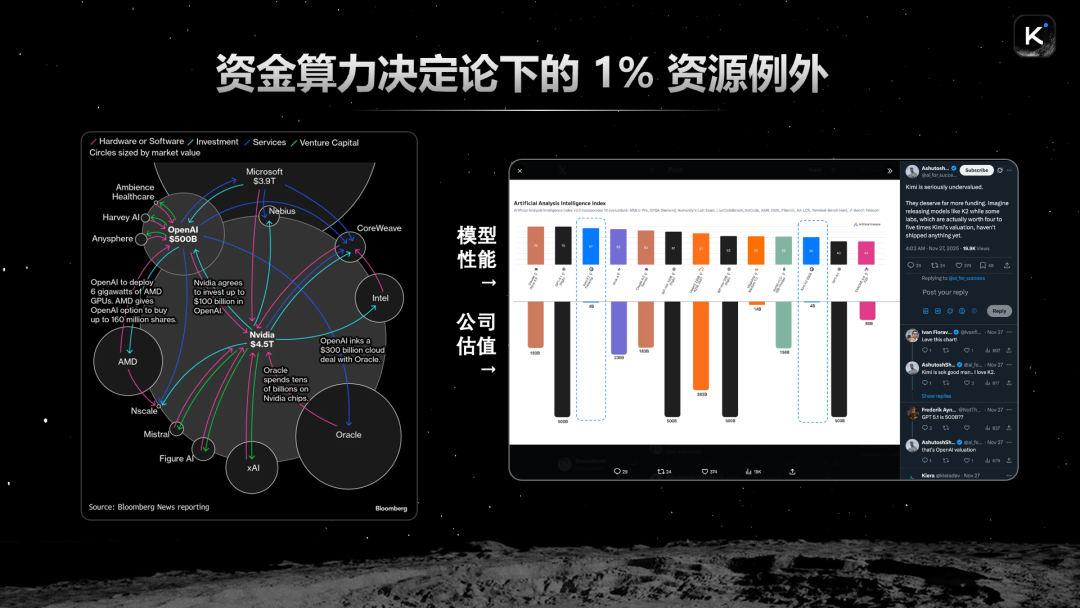
A few days ago, Anna (ZhenFund founding partner) sent me a post she saw on X (formerly Twitter) that I found quite interesting. The post said that our company's valuation is less than 1% of other US frontier model companies, yet we've also produced frontier models. With less than 1% of the resources, the way of working naturally becomes different.
This has happened many times in technology history. Hardware iterates quickly, software iterates quickly, but software often iterates faster — and the co-evolution of software and hardware brings unexpected breakthroughs. Ilya Sutskever also mentioned on the Dwarkesh Podcast a few days ago that AlexNet back then used only two GPUs. Truly breakthrough research doesn't actually depend on massive compute before entering "large-scale engineering implementation."
I think what's particularly interesting behind this is: when you believe in a different logic, your paradigm for doing things changes completely.
When we shift from focusing only on compute scale to thinking about "how to maximize the conversion efficiency from energy to intelligence," the entire large model training paradigm changes.

One very important thing we did in Kimi K2 was to be the first to validate the feasibility of the second-order optimizer Muon on a trillion-parameter model, making the training process both stable and scalable. We thereby achieved at least a 2x improvement in token efficiency — and token efficiency improvement doesn't just mean training costs drop by half, but that we get more intelligence from the same data.
Because the real bottleneck in training now is the data wall, not compute itself. So底层架构创新和算法创新都是在不断优化 token efficiency. The Muon optimizer was invented before, but no one had ever used it for trillion-parameter model training because actually scaling it up involves very complex training stability challenges.
Second, we pay very close attention to co-optimization between infrastructure and model training. We call this Day-0 Co-Design. Before model training even begins, we think about what kind of deeply coupled design should be used to improve training efficiency, and how infrastructure and algorithm talent can work in tightly coupled joint optimization. We've done extensive work around底层基础设施和算法创新, and every improvement compounds in terms of intelligence efficiency.
So using only 1% of the resources, through a different training paradigm, we achieved completely different results — training frontier models at the thousand-GPU scale.
We're not saying we've already made the world's best model today, but this is a very important strategic goal for us going forward. And what we can already do today is produce the highest intelligence value per unit of compute.

We're also very glad to see that more and more AI applications people love have integrated the Kimi K2 model, including AI coding products Cursor and Youware, general agent product Genspark, and nearly all the major internet companies you're familiar with. Recognition of the Kimi K2 model from these companies and products will help us further accelerate model iteration.

Defining Agentic Product Experience from Pre-Training
This year, in addition to major model capability upgrades, we've also put more into practice the "model as product" philosophy we proposed last year, doing vertical integration of the model and agentic product experience.

We've mainly done a few things:
First, we define agentic product experience starting from the pre-training stage. We incorporate large amounts of data related to real agent scenarios during pre-training, including agent trajectories — data on tool use and multi-round planning. We also set up extensive internal benchmarks, using custom metrics to measure data quality and our unique "product aesthetic." So a lot of work begins from Day-0.
Second, after product launch, we can use real-world user experience as signals to do targeted optimization for the model, iterating continuously. This way, model capability and user experience can truly be connected. For example, how the model autonomously performs in context without human definition; how the model's multi-round planning and tool use capabilities combine to provide a more complete agent experience.
Third, we dogfood our own model, passing those cost savings to users (editor's note: this refers to using their own API, with no middleman taking a cut). We use those resources to let people fully experience "deep," "long-duration" agents: through dozens to hundreds of rounds of tool calls and search, more completely accomplishing users' tasks.
Going forward, we're also planning more "long-duration" product development, because in user research we've found that demand follows a kind of Moore's Law trend — tasks are becoming increasingly complex, requiring longer and longer time. People are gradually realizing what more agent experiences can do, so the most extreme form might be more like when you're working at a company, you have one weekly meeting and then work continuously for the whole week. Current agents are still far from this "long-duration task" capability.
But we hope agents can call more and more tools, execute increasingly long-duration tasks, and solve more complex and economically valuable problems. That's why we launched Kimi's agent mode "OK Computer," with the product name inspired by Radiohead's classic album of the same name.
After launch, we observed users putting "OK Computer" through very extreme tests. The current online version supports up to 50 steps of tool calls, and we'll soon upgrade this to 200-300 steps because the new model already supports longer-chain tool calls. We've also seen users upload very large Excel files, having the agent process complex data analysis on millions of rows; others upload large numbers of files, wanting the agent to have complete contextual understanding of tasks, so the number of files uploadable in a single session is also continuously increasing.

OK Computer now supports over 20 tools including image generation and audio generation, providing capabilities not just for writing code but also design, product definition, subsequent development, and deploying it as a usable service. Our goal is for OK Computer to become everyone's full-stack assistant.

Welcome to Explore the Dark Side of the Moon with Us
What do we plan to do next? Beyond the traditional scaling based on compute and model parameters, there are many directions for future expansion. For example, solving the data wall problem, using synthetic data methods to produce higher-quality and better-distributed data at scale.
Now agents can call dozens of tools — in the future, can they adaptively learn as quickly as humans and generalize to thousands of tools? The powerful agent capabilities of models have only emerged for less than a year; there's still enormous room for growth.
Beyond these scaling directions, we'll also continue to focus heavily on model architecture innovation and firmly bet on next-generation architectures. Our recently released Kimi Linear is just one example; there will be more底层架构的创新 ahead, and we believe they'll play an increasingly important role.
At this year's annual meeting, we posed a "soul question" to Kimi: The arrival of AGI/ASI may bring a better future — humans exploring the universe together with robots, human civilization greatly elevated — but it may also threaten humanity.
In this situation, if you were a scientist researching AGI/ASI, would you continue developing it?

Here's Kimi's response. Kimi believes AI is not just an ordinary tool, but an amplifier that can fundamentally transform human civilization; an extension of human cognition, a key to exploring future worlds, helping us redefine human identity and meaning.
It also recognizes AI's risks. "From history, some technologies have indeed gotten out of control and need to be taken seriously. But it wouldn't abandon AGI/ASI because of this. Even with risks, it would choose to continue, because giving up means abandoning the potential of human civilization. We cannot stop exploring because of fear of technological risk. History has proven that all technology comes with risk, but humanity has never stagnated because of fear. It also sees AI as a mirror for understanding itself, and would continue developing because AI represents the possibility of civilization, the best tool for exploring the unknown, making us smarter, deeper, and wiser."
Kimi's answer gave us great inspiration. If you also identify with Kimi's thinking, welcome to explore the dark side of the moon with us.

Here, I'd like to share what kind of people we are. AI technology and product interaction are both developing very rapidly now, requiring constant learning of new knowledge. And the span and depth of AI knowledge far exceed any individual, so we highly value learning ability with few samples, learning speed, and whether someone is a continuously learning partner who constantly expands their cognition and capabilities. In our view, this is where human general intelligence has an advantage over AI — higher learning efficiency.
This year, nearly everyone in our team internally "learned to code." Beyond algorithm and engineering R&D, colleagues in marketing, HR, finance, and other functions all have their own AI workflows. Everyone has embraced the efficiency gains, scalability, more stable output quality, and better results that AI brings. We also hope you maintain enthusiasm for various AI technologies and tools.
At the same time, independent thinking and aesthetic judgment are also very important. Just as all large model training previously used the Adam optimizer, and our researchers discovered the potential of the Muon second-order optimizer, starting experiments with the Moonlight series at tens of billions of parameters and ultimately applying second-order optimization to trillion-level model training. We hope you have the ability to propose original ideas, and to have plenty of them. These ideas won't all be good, but we'll validate them through extensive experimentation. We want to go from research to engineering at scale, letting truly good ideas achieve large-scale deployment.
That's what I wanted to share today. Thank you for your time.

Live Q&A
Q: How do model companies, AI applications, and large model companies view each other? How do model vendors view the boundaries of model capabilities? What real value does agent deliver?
Yutong Zhang: I think this is a very dynamic process, because model capabilities are still continuously improving. This is different from internet products, because the moment the internet appeared, its technical capabilities and presentation form were basically set, so people could do extensive deepening, thinking, and innovation on product interaction based on this foundation.
The current challenge is that model capabilities are still changing rapidly and dynamically. The application and product side needs a forward design capability — to imagine a capability that doesn't yet exist but will certainly emerge along the technology evolution path, then design interactions and experiences based on this evolutionary direction.
Without this forward design, you might encounter situations where model capabilities suddenly leap forward. Products originally designed relying more on "step-by-step model calling" find many things directly compressed into the model itself when the model gains agentic capabilities.
Of course, the opposite can also happen: product-side experience innovation leads, but model capabilities haven't caught up. So sometimes we see some forward-looking product interactions that are ahead of their time, but actual usage feels mediocre. This isn't bad interaction design — it's that model capabilities haven't reached that expectation yet.
This is something everyone is exploring together. It requires better grasp of model capabilities, doing good forward design, and both sides moving forward faster together.
Q: What is Kimi's core competitive advantage? With large model competition intensifying, how do you differentiate positioning from tech giants at both technical and market levels?
Yutong Zhang: I think the most effective way to compete is "not to compete." Not competing doesn't mean lying flat — it means finding your own narrative, finding what you're truly good at.
For us, the first thing we're best at is fundamental technology innovation. Because there are still many real problems to solve in the large model field, and these problems fundamentally require底层技术创新 — this is precisely where startups have the greatest advantage.
The second thing is joint optimization between底层 and上层. Large enterprises inevitably have organizational collaboration barriers, information transmission friction, and other issues. We have only 300 people; algorithms, engineering, and product can all sit together, and many new ideas can be proposed and experimented on the same day. Rapid iteration, vertical integration, and end-to-end optimization are natural strengths of startup teams.
From a product positioning perspective, Kimi users may have noticed there are many things we deliberately don't do. We haven't pursued lifestyle and entertainment; we haven't done multimodal generation. We focus more on the large model layer, logic layer, agent layer, and productivity-oriented, complex-task chains like deep research, presentations, data analysis, and website development. These tasks require long-horizon planning, complex tool calling, and create higher economic value.
Within this scope, we want to do our best rather than pursuing something more "comprehensive."

Text by Cindy


