Manus Founder Walks Through: How to Systematically Build Context Engineering for AI Agents?

If model progress is a rising tide, we want Manus to be the boat, not a pillar nailed to the seabed.

Z Talk is ZhenFund's column for sharing ideas and perspectives.
In "Manus in Conversation with YouTube Co-founder Steve Chen," Manus co-founder and chief scientist Peak (Yichao Ji) mentioned that whenever the team discussed the technical implementation of a feature, he would habitually ask himself: could this feature create network effects within the product?
As a general-purpose agent, every new capability added to Manus is designed to produce unexpected coupling effects with existing features. For instance, after adding image reading capabilities, they discovered Manus could debug its own generated data visualization code, and even miraculously fix issues in other modules. This compounding effect is precisely what they value most.
Yesterday, Manus published a new article on its website where Peak shared the pitfalls and lessons learned from building their context engineering system. It's a candid, in-depth, and highly practical record. Peak systematically organized the experience his team distilled through repeated trial and error, offering a referenceable path for developers building AI agents, and taking us through Manus's journey from zero to one.
Manus is still moving forward. As Peak wrote: "If model progress is a rising tide, we want Manus to be a boat, not a pillar nailed to the seabed."
If you're building your own agent, we hope these insights help you find your bearings faster. This article is republished from Founder Park, translated based on Moonshot AI K2. Here is the compiled original:
At the outset of the Manus project, my team and I faced a critical decision: should we train an end-to-end agent using open-source foundation models, or should we build an agent on top of frontier models by leveraging their in-context learning capabilities?
For the first decade of my work in NLP, we didn't have the luxury of this choice. Cast your mind back to the release of BERT (yes, that was seven years ago) — models had to be fine-tuned — and evaluated — before they could be transferred to new tasks. Each iteration often took weeks, even though model sizes were trivial compared to today's LLMs. For rapidly iterating applications, especially pre-PMF, such slow feedback loops were practically fatal. This was the painful lesson from my previous startup: I had trained models from scratch for open information extraction and semantic search. Then GPT-3 and Flan-T5 arrived, rendering my custom models obsolete overnight. The irony, of course, was that these very models opened the door to in-context learning and pointed us toward an entirely new path.
This hard-won lesson made the choice clear: Manus would bet on context engineering. This allowed us to ship improvements in hours rather than weeks, while keeping our product orthogonal to the underlying model: If model progress is a rising tide, we want Manus to be a boat, not a pillar nailed to the seabed.
Yet context engineering is far from smooth sailing. It is an experimental science. We have refactored our agent framework four times, each time after discovering a better way to shape context. We affectionately call this manual process of architecture search, prompt tuning, and empirical guesswork "Stochastic Graduate Descent." It is not elegant, but it works.
This article shares the local optimum we reached through our own "SGD." If you are building your own AI agent, we hope these principles help you converge faster.

Design Around the KV-Cache
If I had to pick one metric, I would say KV cache hit rate is the single most important metric for production-grade AI agents, directly impacting both latency and cost. To understand why, let's look at a typical agent workflow:
After receiving user input, the agent completes the task through a sequence of tool calls. In each iteration, the model selects an action from a predefined action space based on the current context, then executes that action in an environment (such as Manus's VM sandbox) and produces an observation. The action and observation are appended to the context, becoming the input for the next iteration. This loop continues until the task is complete.
As you can imagine, the context grows at every step, while the output — typically a structured function call — remains relatively short. This creates a severely imbalanced prefill-to-decode ratio compared to chatbots. In Manus's case, the average input-to-output token ratio is approximately 100:1.
Fortunately, contexts with identical prefixes can leverage KV caching, significantly reducing time-to-first-token (TTFT) and inference costs, whether you're using self-hosted models or calling inference APIs. This is no minor saving: for Claude Sonnet, cached input tokens cost $0.30 per million, while uncached tokens cost $3.00 per million — a 10x difference.
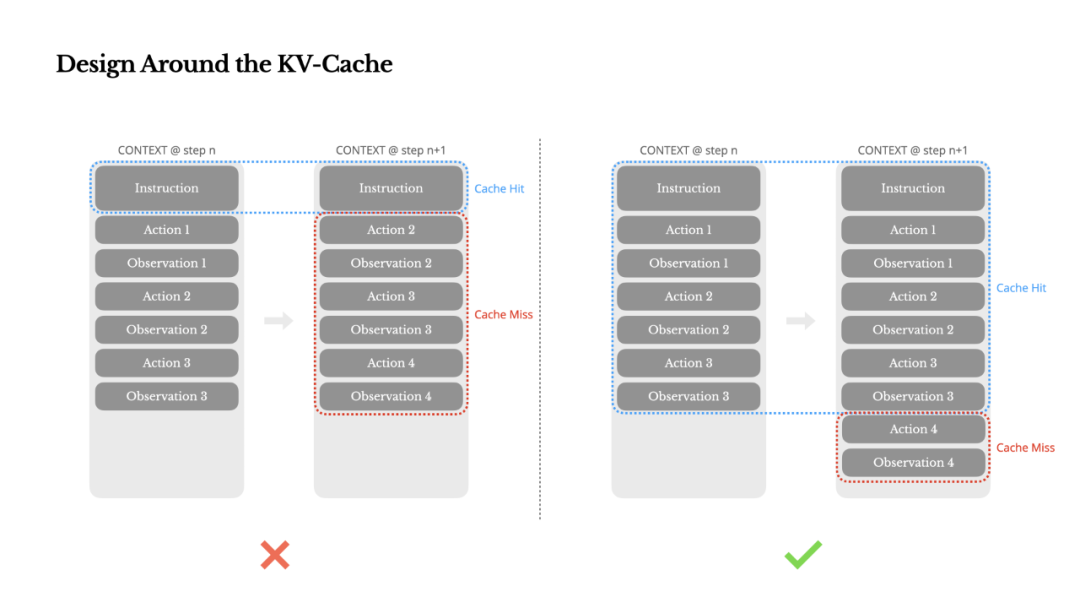
From a context engineering perspective, improving KV cache hit rate requires following several key practices:
1. Keep prompt prefixes stable. Due to the autoregressive nature of LLMs, even a single token difference can invalidate the entire cache from that point onward. A common mistake is adding timestamps to the beginning of system prompts — especially ones precise to the second. While this lets the model tell you the current time, it also drives your cache hit rate to zero.
2. Keep context append-only. Avoid modifying previous actions or observations. Ensure serialization is deterministic. Many programming languages and libraries do not guarantee stable key ordering when serializing JSON objects, which can silently break caching.
3. Explicitly mark cache breakpoints when needed. Certain model providers or inference frameworks don't support automatic incremental prefix caching, instead requiring manual cache breakpoints inserted into the context. When setting these breakpoints, consider potential cache expiration, and at minimum ensure the breakpoint includes the end of the system prompt.
Additionally, if you're self-hosting models with frameworks like vLLM, make sure prefix/prompt caching is enabled, and use techniques like session IDs to route requests consistently across distributed workers.

Constrain Action Selection Through Masking, Not Removal
As your agent takes on more capabilities, its action space naturally grows more complex. Put bluntly, the number of tools explodes. The recent popularity of MCP only adds fuel to the fire. If you allow users to configure their own tools, trust me: someone will plug a hundred mystery tools into your carefully curated action space. The result: the model is more likely to select wrong actions or follow inefficient paths. In short, the fully armed agent becomes dumber.
A natural thought is to design a dynamic action space — perhaps loading tools on demand in a RAG-like fashion. We tried this at Manus. But experiments yielded a clear rule: unless absolutely necessary, avoid dynamically adding or removing tools during iterations. There are two main reasons:
-
In most LLMs, tool definitions typically sit at the front of the context after serialization, usually before or after the system prompt. Therefore, any change invalidates the KV cache for all subsequent actions and observations.
-
When previous actions and observations still reference tools that no longer exist in the current context, the model becomes confused. Without constrained decoding, this often leads to schema violations or hallucinated actions.
To address this while improving action selection, Manus uses a context-aware state machine to manage tool availability. Rather than actually removing tools, it masks the logits of corresponding tokens during decoding, thereby blocking (or forcing) selection of certain actions based on current context.
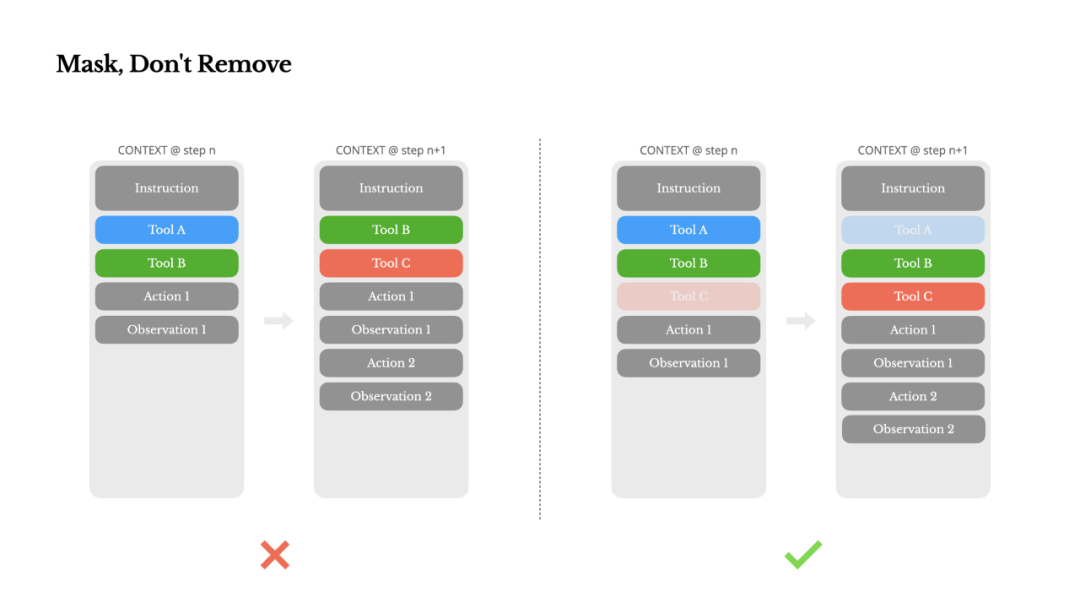
In practice, most model providers and inference frameworks support some form of response prefilling, allowing you to constrain the action space without modifying tool definitions. Function calling typically has three modes (using NousResearch's Hermes format as an example):
- Auto — the model can choose whether to call a function. Implementation: prefill only the response prefix:
<|im_start|>assistant - Required — the model must call a function, but which function is unrestricted. Implementation: prefill up to the tool call token:
<|im_start|>assistant<tool_call> - Specified — the model must call a function from a specific subset. Implementation: prefill up to the beginning of the function name:
<|im_start|>assistant<tool_call>{"name": "browser_
We leverage this to restrict action selection by directly masking token logits. For example, when a user provides new input, Manus must respond immediately rather than execute any action. We also deliberately designed unified prefixes for action names — for instance, all browser-related tools start with browser_, and command-line tools start with shell_. This allows us to easily constrain the agent to select only from a specific group of tools in a given state, without relying on stateful logits processors.
These designs help ensure the Manus agent loop remains stable, even in a model-driven architecture.

Treat the File System as Context
Modern frontier LLMs now support 128K or even larger context windows. But in real-world agent scenarios, this is often still insufficient — and sometimes even becomes a burden. There are three common pain points:
-
Observations can be extremely large, especially when the agent interacts with unstructured data like web pages or PDFs. It's easy to exceed context limits.
-
Model performance often degrades beyond a certain context length, even if the window technically still supports it.
-
Long inputs are expensive; even with prefix caching, you still pay to transfer and prefill every token.
To address this, many agent systems implement context truncation or compression strategies. But overly aggressive compression inevitably leads to information loss. The fundamental problem is this: an agent must, by its nature, predict the next action based on all previous states. You cannot reliably predict which observation will become critical ten steps later. From a logical standpoint, any irreversible compression carries risk.
This is precisely why we treat the file system as the ultimate context at Manus: infinitely capacious, natively persistent, and directly manipulable by the agent. The model learns to read and write files on demand, treating the file system not merely as storage, but as structured, externalized memory.
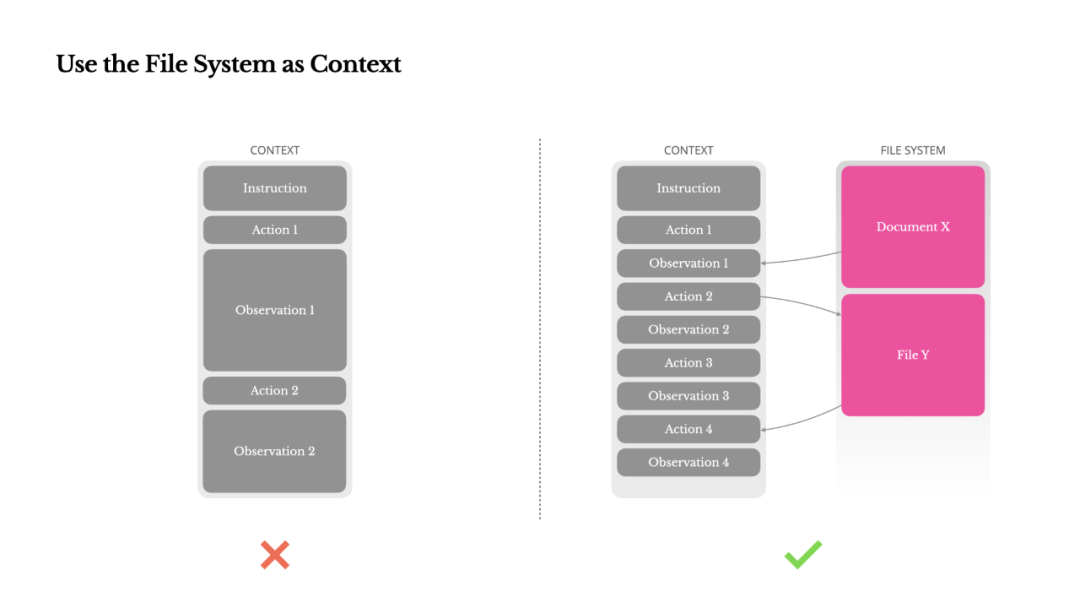
Our compression strategies always guarantee reversibility. For example, web content can be removed from context as long as the URL is preserved; document content can be omitted as long as the path remains available in the sandbox. This allows Manus to shorten context length without permanently losing information.
In developing this capability, I began to imagine what would be required for state space models (SSMs) to operate efficiently in agent environments. Unlike Transformers, SSMs lack full attention mechanisms and struggle with long-range backward dependencies. However, if they could master file-based memory — externalizing long-term state rather than holding it in context — their speed and efficiency might enable an entirely new class of agents. Agentic SSMs could become the true successors to neural Turing machines.

Manipulate Attention Through Recitation
If you've used Manus, you may have noticed an interesting phenomenon: when handling complex tasks, it often creates a todo.md file and updates it progressively as the task advances, checking off completed items one by one.
This isn't a cute gimmick — it's a deliberately designed attention manipulation mechanism.
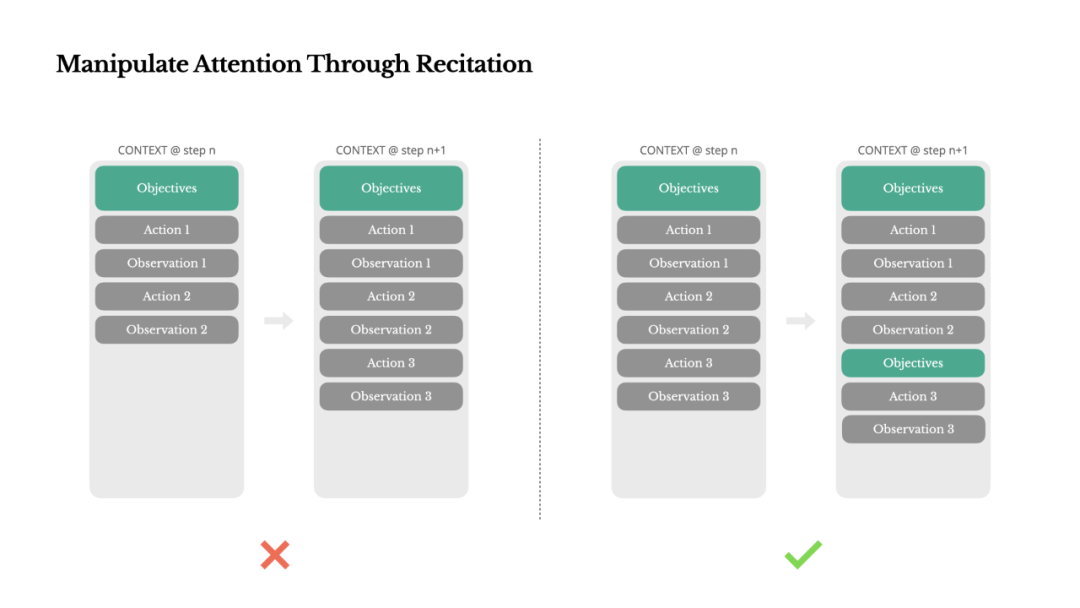
In Manus, a typical task averages about 50 tool calls. That's a long loop. Because Manus relies on LLMs for decision-making, it can easily drift off-topic or forget early objectives amid lengthy context or complex tasks.
By continuously rewriting the todo list, Manus "recites" goals into the end of the context. This pushes the global plan into the model's recent attention window, avoiding the "lost in the middle" problem and reducing goal misalignment. In effect, it's using natural language to bias its own attention toward task objectives, without any special architectural modifications.

Preserve Errors
Agents make mistakes. This is not a bug; it is reality. Language models hallucinate, environments return errors, external tools fail, and unexpected edge cases abound. In multi-step tasks, failure is not the exception — it is part of the loop.
Yet a common impulse is to cover up these errors: clean up the trace, retry the operation, or reset the model state, then hope for the best with a mysterious "temperature" parameter. This seems safer and more controllable, but it comes at a cost: erasing failure means erasing evidence. And without evidence, the model cannot adapt.
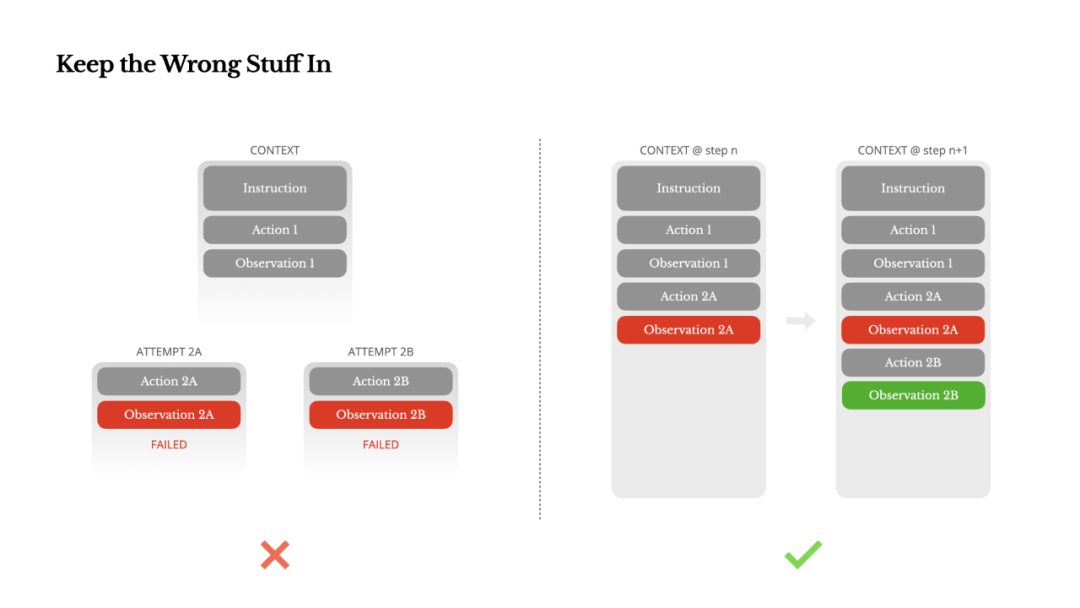
Based on our experience, one of the most effective ways to improve agent behavior is deceptively simple: leave the wrong turns in the context.
When the model sees a failed action, along with the resulting observation or stack trace, it subtly updates its internal beliefs. This shifts priors away from similar actions, reducing the probability of repeating the same mistake. In fact, we consider error recovery to be one of the clearest indicators of truly agentic behavior. Yet it remains undervalued in most academic research and public benchmarks, which tend to focus on task success under ideal conditions.

Don't Let Few-Shot Backfire
Few-shot prompting is a common technique for improving LLM outputs, but in agent systems it can backfire in subtle ways.
Language models are excellent imitators; they will mimic behavioral patterns present in the context. If your context is filled with many similar action-observation pairs, the model will tend to follow that pattern, even when it is no longer optimal.
This can be dangerous in scenarios involving repetitive decisions or tasks. For example, when using Manus to assist with reviewing a batch of 20 resumes, the agent often falls into a rhythm — repeating similar operations simply because they appeared in context. This leads to drift, overgeneralization, and sometimes even hallucination.

The solution is to increase diversity. Manus introduces small structured variations in actions and observations — different serialization templates, alternative phrasings, slight perturbations in order or format. This controlled randomness helps break fixed patterns and fine-tunes the model's attention. In other words, don't trap yourself in a few examples. The more homogeneous the context, the more fragile the agent.
Conclusion
Context engineering remains an emerging discipline. But for agent systems, it is already indispensable. Models may become more powerful, faster, and cheaper, but even the strongest native capabilities cannot replace memory, environment, and feedback. How you shape context ultimately determines agent behavior: how fast it runs, how well it recovers, and how far it can scale.
At Manus, we learned these lessons through repeated rewrites, dead ends, and real-world testing with millions of users. What we share here is not universal truth, but patterns we have validated. If they save you even one painful iteration, this post will have been worth it.
The future of agents will be built one context at a time. Design them well.



