Yichao Ji, Peak: A Small Step Toward Replicating OpenAI o1 — Steiner Open-Source Model Progress Report | Z Talk

Since OpenAI released o1, I've been working on reproducing it as a side project in my spare time.
By Yichao "Peak" Ji, ZhenFund EIR (Entrepreneur In Residence)
Since OpenAI o1's release, I've been working on reproducing it as a side project, picking up fascinating insights (and failures) along the way. Given my limited skills, energy, and budget, I'm probably not the one who'll cross the finish line. So I feel it's important to share these lessons learned — worth dozens of H100s — while they're still fresh.
The English version of this article is also published at:
https://medium.com/@peakji/a-small-step-towards-reproducing-openai-o1-b9a756a00855
01
TL;DR
Steiner is a reasoning model that can explore multiple paths autoregressively during inference, performing self-verification and backtracking when necessary. Training proceeds in three stages: First, synthetic reasoning paths are randomly truncated and guided to re-complete, transforming each sample into a directed acyclic graph (DAG) from problem to answer. Next, 50K reasoning path samples with backtracking nodes are sampled from 10K DAGs. Finally, using the in-degree and out-degree of nodes in the DAG and their distances as heuristic rewards, reinforcement learning teaches the model to balance the breadth and depth of exploration. The model achieves a +5.56 improvement on GPQA-Diamond, but fails to reproduce inference-time scaling.
Model download:
https://huggingface.co/collections/peakji/steiner-preview-6712c6987110ce932a44e9a6
02
Introduction
Steiner is a family of reasoning models trained with reinforcement learning on synthetic data, capable of attempting multiple reasoning paths autoregressively during inference, with autonomous verification and backtracking when needed — thereby performing a linear traversal of an implicit search tree within a single context.
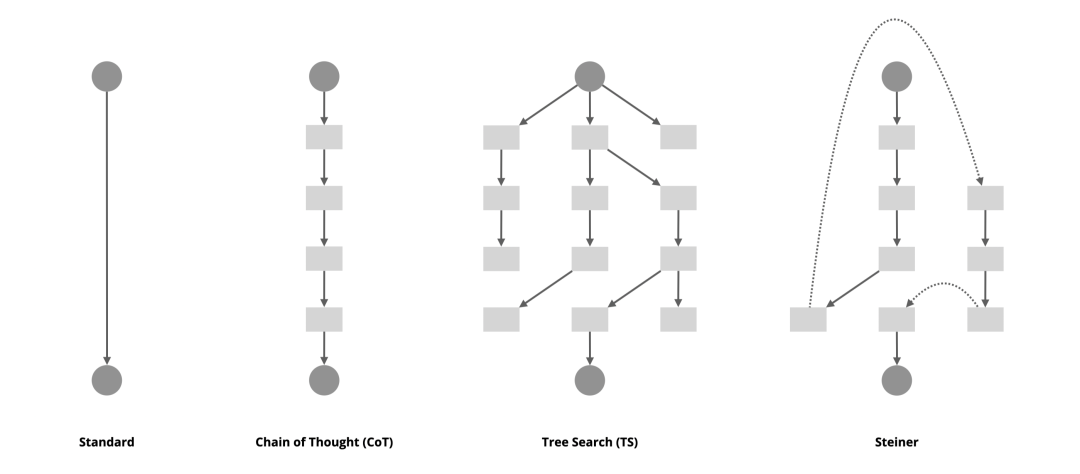
Steiner can attempt multiple reasoning paths autoregressively during inference, with autonomous verification and backtracking when needed — thereby performing a linear traversal of an implicit search tree within a single context.
Steiner is a personal project by Yichao "Peak" Ji, inspired by OpenAI o1, with the ultimate goal of reproducing o1 and verifying the inference-time scaling curve. The Steiner-preview model is a work in progress. I'm open-sourcing it because I've observed that automated evaluation methods dominated by multiple-choice questions struggle to adequately reflect the progress of reasoning models: the premise that "the correct answer must be among the options" is fundamentally misaligned with real reasoning scenarios, as it encourages substitution-based verification rather than open-ended exploration. Therefore, I've chosen to open-source these intermediate results and, bandwidth permitting, build in public — sharing knowledge while gaining more evaluation and feedback from real humans.
⚠️ Disclaimer: So far, Steiner can achieve relatively high-quality zero-shot results without Chain of Thought (CoT) prompting or agent frameworks, but still fails to reproduce the inference-time scaling capability demonstrated by o1: in experiments using a special logits processor (https://gist.github.com/peakji/f81c032b6c24b358054ed763c426a46f) to intervene on reasoning tokens, adding extra reasoning steps did not improve performance and actually degraded results on benchmarks like MMLU-Pro and GPQA. Thus Steiner cannot yet be considered a successful reproduction of OpenAI o1, and likely has deficiencies in both training methodology and data quality — please take it as a reference with caution.
03
Background
Compared to traditional LLMs, OpenAI o1's most significant change is the introduction of reasoning tokens during inference, enabling inference-time scaling: improving model performance by increasing compute budget at inference time. When discussing inference-time scaling, the most intuitive approach might be tree search or agentic frameworks. However, in reading the (limited) official information about o1, I noticed that its reported benchmarks mostly use pass@1 and majority voting, and the OpenAI team also mentioned that o1 is a single model rather than a system. This made me very curious about its implementation.
The OpenAI API still hasn't exposed the actual content of reasoning tokens to developers, but fortunately token usage statistics do include reasoning token counts (after all, they charge developers based on this). Using this, I designed a simple experiment to examine the relationship between completion (including reasoning) token count and total request duration via the o1 API. We know that with tree search, to maximize cache reuse and GPU utilization, inference would be parallelized as much as possible, yielding a sub-linear curve. However, the experimental results showed several clean straight lines, with o1-mini showing even less variance than GPT-4o-mini:
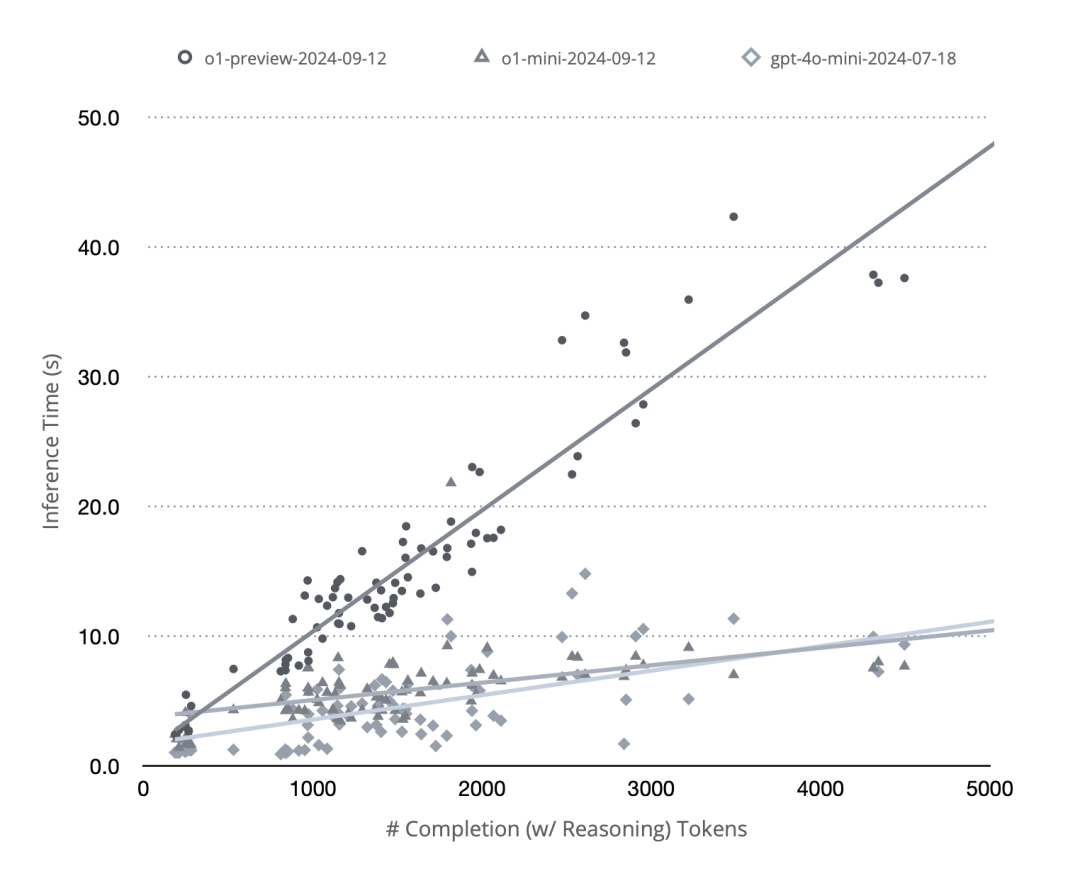
OpenAI o1 may still be a model performing linear autoregressive decoding, but this doesn't mean it isn't "searching" during inference.
This experiment led me to a hypothesis: OpenAI o1 may still be a model performing linear autoregressive decoding, but this doesn't mean it isn't "searching" during inference. Imagine a search tree — when we traverse it, the trace produced is actually linear. If we could train an autoregressive language model to not only generate reasoning paths but also verify, backtrack, or switch approaches when necessary, then in the ideal case it would effectively complete a linear traversal of an implicit search tree within a single context. This linear traversal sounds wasteful, but compared to parallel search, it has three extremely attractive properties:
- All prior attempts, whether correct or wrong, remain in context memory — every decision is based on complete information from the past;
- Implicit backtracking doesn't require that the target node already exists in the search tree, enabling freer exploration;
- At the engineering level, it can reuse all existing, highly optimized inference infrastructure.

Imagine a search tree — when we traverse it, the trace produced is actually linear.
04
Method
Obtaining a model with linear search capability is no easy feat — both data synthesis and model training face numerous challenges.
First, most currently available reasoning datasets only contain synthetic CoT or reasoning steps, typically obtained by feeding "problem-answer" tuples to a powerful LLM and asking it to break down the thinking process. This approach inherently means these datasets won't contain proper backtracking nodes, so models trained on such data only learn shortcuts, or rather, internalize CoT.
To address this, I designed two data synthesis and augmentation methods:
- Randomly truncate the shortcut datasets and hide the correct answer, letting a powerful LLM attempt forward reasoning for a certain number of steps based on the truncated prefix, then provide the correct answer to obtain backtracking samples;
- Cluster the steps produced in the previous step and assign unique IDs, build all steps under the same problem into a directed acyclic graph (DAG), and randomly sample from the DAG to obtain polynomially many reasoning path samples.
Through these methods (plus extensive manual effort and various tricks), I ultimately obtained 10K directed acyclic graphs, and sampled 50K reasoning path samples with backtracking on top of them. The average number of reasoning tokens per sample is about 1,600, remarkably close to the statistics from my previous tests of o1/o1-mini! Given training costs, I only kept samples with reasoning token counts below 4,096 and total prompt + reasoning + completion token counts below 8,192.
Next, I divided Steiner model training into three stages:
-
Continual Pre-Training (CPT): Mixed training on ordinary text corpora and reasoning paths, aiming to get the model accustomed to long reasoning outputs and initially train embeddings for 14 new special tokens (https://huggingface.co/peakji/steiner-32b-preview/blob/278989ea17f74b14e2b32d9544eb53a17b4ad087/special_tokens_map.json#L16-L29). It should be noted that tests on some smaller models suggest this step may be redundant — directly training with large amounts of reasoning data in the SFT phase seems to also yield decent representations, but CPT for 32B was done quite early, so I've continued with it;
-
Supervised Fine-Tuning (SFT): Training with chat template, aiming to teach the model to mimic the reasoning format: first come up with a name for each step, then output the complete thought, then summarize the thought into a summary, then reflect on the reasoning so far, and finally decide whether to proceed, backtrack, or end reasoning and begin formally answering the question. You might wonder: since the open-source model doesn't need to hide thoughts, why generate summaries like o1 does? This is because I'm preparing for future Steiner models with multi-turn dialogue capability. In theory, after training, one could choose to replace complete thoughts from previous conversations with summaries to reduce pre-fill overhead when prefix cache misses. Currently Steiner hasn't been optimized for multi-turn dialogue, and retaining summaries alone may produce negative few-shot effects;
-
Reinforcement Learning with Step-Level Reward (RL): After the first two stages, the model has learned to generate and complete reasoning paths, but it doesn't yet know which choices are correct and efficient. If we blindly reward shorter reasoning paths, it would degenerate into shortcut learning to internalize CoT. Here I designed a heuristic reward mechanism: based on each node's in-degree e_i, out-degree e_o, distance to the original problem d_s, and distance to the correct answer d_e in the DAG, weighted to assign rewards to each step and the entire reasoning path, guiding the model to learn to balance exploration breadth and depth.
The above approach looks simple, but for the past month-plus, every weekend (and non-overtime evening) I've been battling OOM and reward hacking. Finally, on the 38th day after OpenAI o1's release, I produced some not-too-embarrassing intermediate results.
05
Evaluation
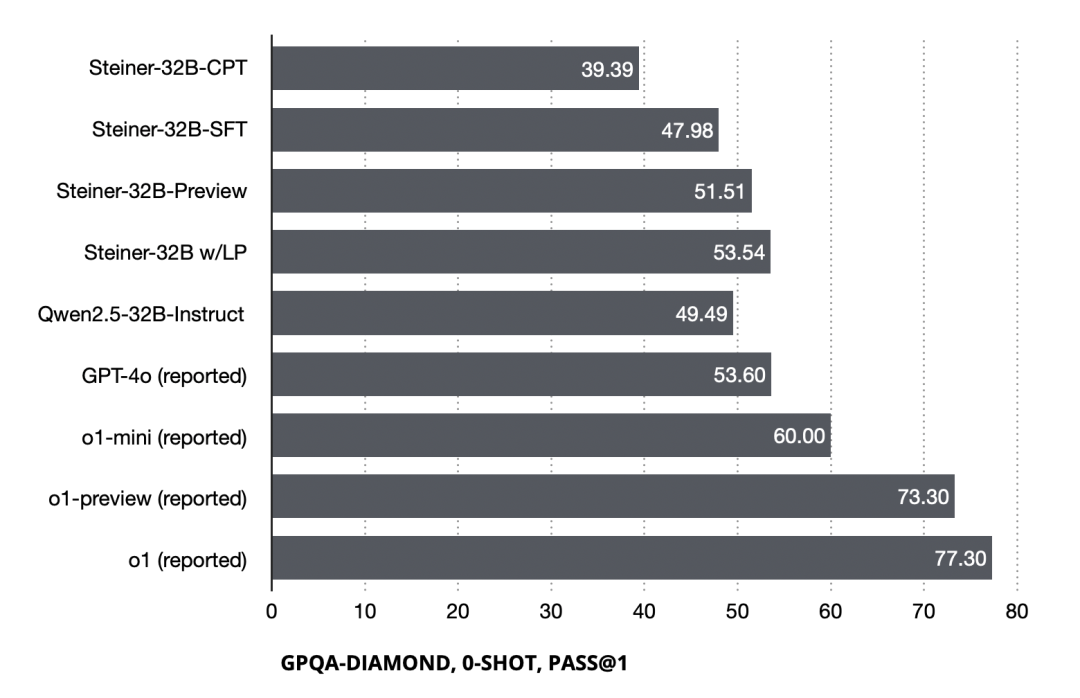
Performance of Steiner models at different training stages on GPQA-Diamond. All Steiner models are evaluated without CoT prompting.
The figure shows performance of Steiner models at different training stages on GPQA-Diamond. We can see that introducing the reinforcement learning stage gave the model a +3.53 improvement. With a logits processor constraining reasoning step count (https://gist.github.com/peakji/f81c032b6c24b358054ed763c426a46f), the optimal configuration yields a +5.56 improvement.
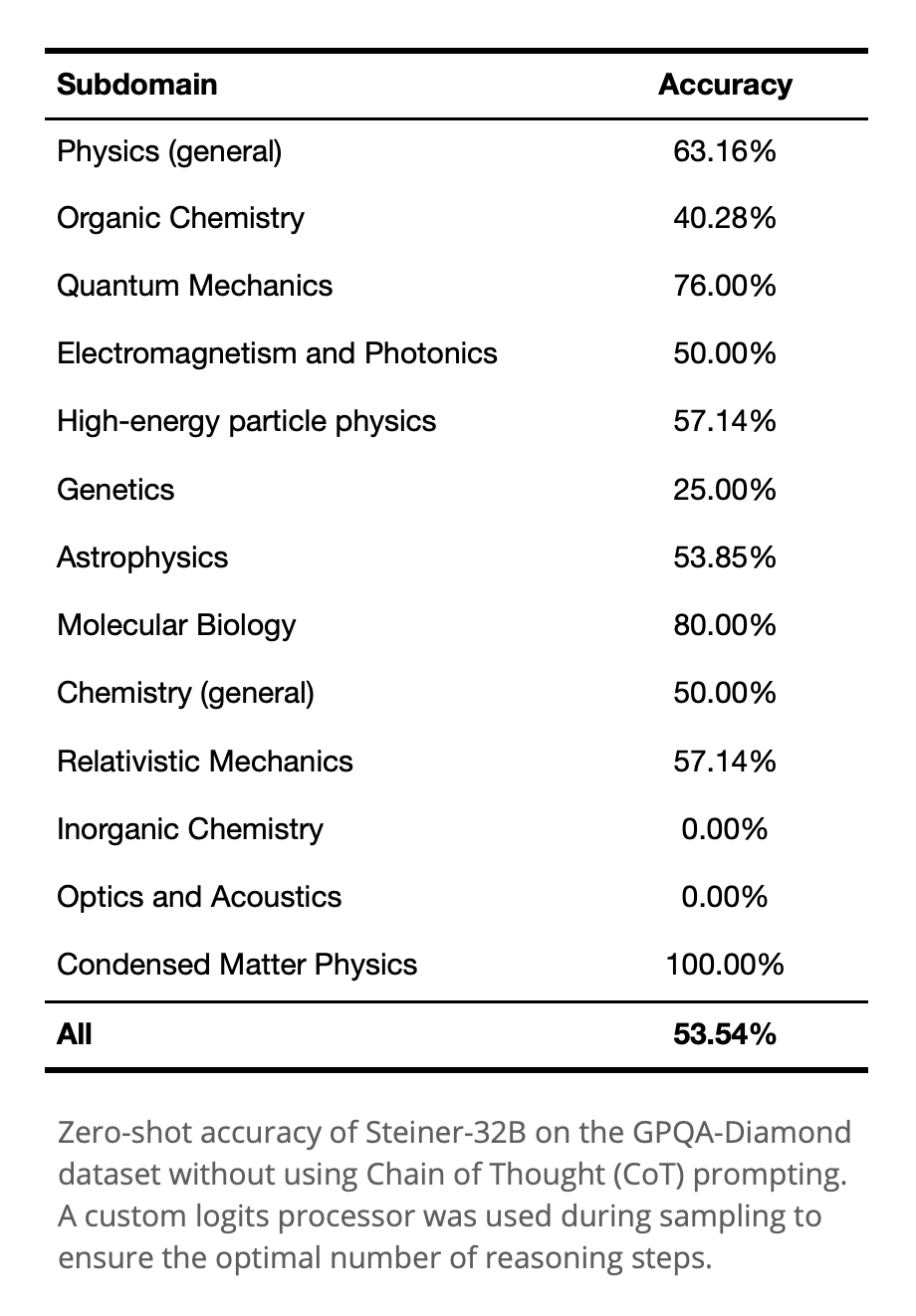
Performance of Steiner-32B with special logits processor on GPQA-Diamond subdomains.
I chose to show this benchmark first because o1/o1-mini showed significant improvement on this dataset, and its contamination situation is relatively ideal. Second, because I found that Steiner showed no obvious difference from baseline on datasets like MMLU, similar to OpenAI's observation in their o1-mini blog (https://openai.com/index/openai-o1-mini-advancing-cost-efficient-reasoning/), possibly limited by the world knowledge the 32B model obtained during pre-training.
Whether from benchmarks or actual usage, we must admit the current model still falls far short of o1-mini and o1. But on the other hand, automated evaluation benchmarks dominated by multiple-choice questions may not adequately reflect reasoning models' capabilities: during training, reasoning models are encouraged to openly explore problems, while multiple-choice questions carry the premise that "the correct answer must be among the options" — clearly, substituting and verifying each option is the more efficient method. In fact, existing large language models have intentionally or unintentionally mastered this technique, regardless of whether special prompts are used. Of course, it's precisely this misalignment between automated evaluation and real reasoning needs that makes me feel it's even more necessary to open-source the model for real human evaluation and feedback.
The bigger problem lies in inference-time scaling experiments: unfortunately, currently when Steiner uses a logits processor (https://gist.github.com/peakji/f81c032b6c24b358054ed763c426a46f) to add extra reasoning steps, it shows no improvement on almost all tested benchmarks, and even declines. Currently speculated reasons are numerous, including but not limited to:
- CPT/SFT didn't truly enable the model to master very long output tokens;
- The heuristic reward design in the RL stage failed to let the model achieve balance between reasoning breadth and depth;
- When backtracking, context influence makes it easy to confirm wrong answers or deny originally correct ones;
- Forcibly modifying logits to increase reasoning steps is too crude a method;
- ...
In any case, this will be the focus of my upcoming work.
06
Limitations
Currently Steiner's post-training data doesn't contain multi-turn dialogue samples. The best-performing Steiner model version (based on Qwen2.5-32B) completely lacks multi-turn dialogue capability. The open-source Steiner-preview model (based on Qwen2.5-32B-Instruct) can be compatible with chat format, but multi-turn dialogue is still not recommended.
Similar to OpenAI o1-2024-09-12, Steiner also doesn't recommend using custom system prompts or modifying sampling parameters like temperature. Currently Steiner hasn't been trained on diverse system prompts, and modifying other parameters may cause reasoning token format errors.
Steiner's post-training data is approximately 90% English and 10% Chinese by language, but the reasoning path data augmentation process used almost entirely English. Therefore while the model's final answers have some language-following capability, reasoning tokens may be entirely in English.
07
Easter Egg
As for the origin of the name Steiner, why not ask the model itself:
What's the origin of your name?
My name is Steiner, derived from the protagonist's ability "Reading Steiner" in Steins;Gate. This ability allows the protagonist to retain memories from multiple world lines, which fits very well with my characteristics as a reasoning model: when reasoning, I can try multiple paths and jump or backtrack when necessary, while retaining memories of all explored paths.
08
Citation
If you find my work helpful, please consider citing it in your research or projects. Your recognition would be greatly appreciated!
@misc{ji2024steiner,
title = {A Small Step Towards Reproducing OpenAI o1: Progress Report on the Steiner Open Source Models},
url = {https://medium.com/@peakji/b9a756a00855},
author = {Yichao Ji},
month = {October},
year = {2024}
}
Recommended Reading