Professor Lu Cewu's Speech: Has Embodied Intelligence Found Its Own Scaling Law? | Z Talk

Starting from first principles in embodied intelligence.
Z Talk is ZhenFund's column for sharing ideas and perspectives.
Here, we discuss the latest industry observations, cutting-edge entrepreneurial developments, and reconnect with old friends from the ZhenFund community. We believe in continuous learning and evolution, and that the deepest insights come from practice.
Noematrix was founded in 2023 as a frontier technology company focused on developing and applying embodied intelligence technology. It was strategically incubated by Flexiv, a general-purpose intelligent robotics company, and co-founded by Professor Cewu Lu, a professor at Shanghai Jiao Tong University and recipient of the 2023 Xplorer Prize. ZhenFund participated in Flexiv's Series A funding round.
At the 2024 World Artificial Intelligence Conference (WAIC), Professor Cewu Lu delivered a speech titled Noematrix Embodied Brain and the Scaling Law of Embodied Intelligence. The following is the full transcript:
In the field of AI large models, the Scaling Law is a crucial empirical discovery — it describes how model performance continuously improves as model size, data volume, and training time increase.
OpenAI validated the success of Scaling Law in language and vision large models through ChatGPT and Sora. So, has the rapidly evolving field of embodied intelligence found its own "Scaling Law"? How can embodied intelligence large models achieve generality and robustness? And how should data be acquired, trained, and measured for growth?
At the 2024 World Artificial Intelligence Conference, Noematrix co-founder Professor Cewu Lu delivered a speech titled Noematrix Embodied Brain and the Scaling Law of Embodied Intelligence at a concurrent forum, sharing his perspective on the key elements, commercial products, and future trends in developing embodied intelligence.

01
Can the Language Model Scaling Law
Be Replicated in Embodied Intelligence?
We know that embodied intelligence is an intelligent system based on physical embodiment for perception and action, where cognition, learning, decision-making, and action emerge through interaction between the agent and its environment. Due to the lack of physical interaction data between actual executors and the world, current language and vision large models do not fully cover the physical world laws required for embodied intelligence research. Therefore, simply increasing data volume on top of these models cannot satisfy the needs of embodied intelligence development.
So if we replicate the language model Scaling Law and massively fill end-to-end "vision" to "control" data for model training, can we obtain an embodied intelligence large model with sufficiently superior performance?
The answer is that even if this is a logically valid approach, it still faces many bottlenecks at the current stage. The biggest problem is the vastly different levels of difficulty in data acquisition. Examining the evolution of past language and vision large models, we find that the booming development of the internet provided massive amounts of vision and language data, and the filling of such data was essentially a mass, grassroots behavior.
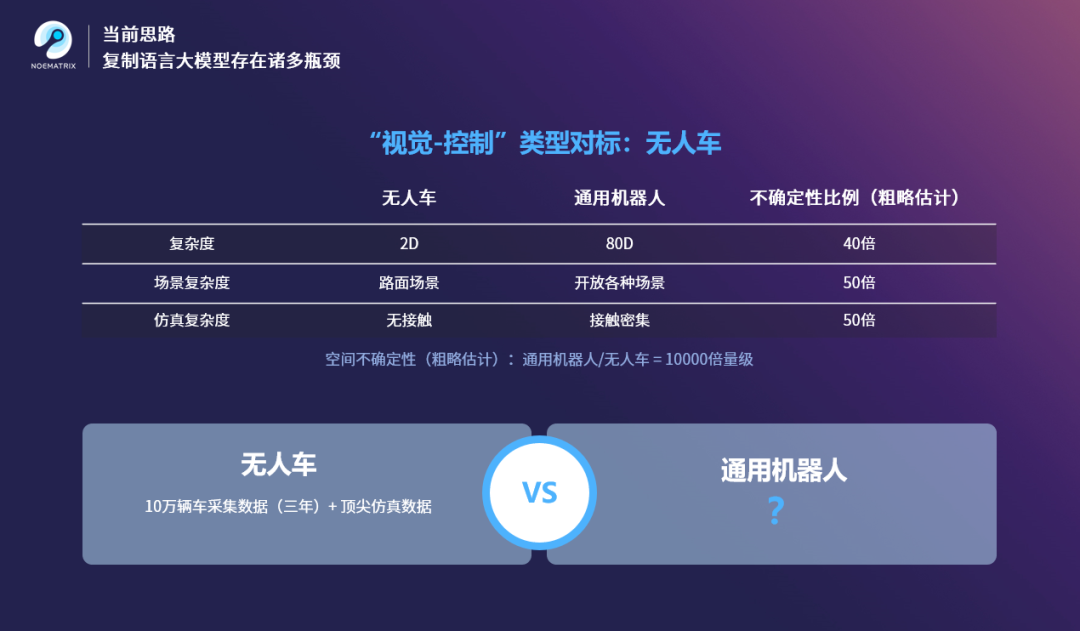
However, embodied intelligence data requires 1:1 collection, and its data space is enormous, generating prohibitively high costs on top of massive data demands.
Take the autonomous vehicle sector, which similarly requires collecting "vision" to "control" data: over the past three years, roughly 100,000 vehicles equipped with advanced simulation capabilities have collected such data, barely reaching a somewhat usable level. Yet in terms of operational, scenario, and simulation complexity, embodied intelligence executors (such as general-purpose robots) face at least several dozen times more uncertainty compared to autonomous vehicle data.
This enormous uncertainty makes the required data space for embodied intelligence massive, creating a data curse. Therefore, when trying to effectively and rapidly advance embodied intelligence, we can step outside the "approach" itself and start from first principles to think about what the key factors are for completing embodied intelligence tasks.
02
Building a Two-Stage Rocket Large Model
From First Principles
Starting from first principles for embodied intelligence large models, it must first understand the physical world — knowing "what the world is"; second, it must know "how to make decisions" in order to exhibit sufficiently robust behavior. Combined with pre-training or assistance from language and vision large models, and through joint training of operation-related physical commonsense and force feedback embedded in the agent's behavioral decision-making process, embodied intelligence can grow rapidly.

From this, we have built two large models that can be viewed as a two-stage rocket propelling embodied intelligence development:
The first stage is the Physical World Large Model. It enables robots to acquire commonsense, low-dimensional operational physical representations during training, thereby understanding objective physical facts and aligning with human concepts.
The second stage is the Robot Behavior Large Model. It fully couples operational physical commonsense representations with the executor's (taking robots as an example) high-precision force feedback capabilities, enabling human-like force-position hybrid behavioral decisions with excellent robustness and generality in operation.
When the two-stage rockets are串联 together for end-to-end joint training, data volume requirements are significantly reduced and the growth slope becomes more pronounced, making training sufficiently low-cost and scalable.
03
An Attainable Data Paradigm:
Low-Cost, Scalable Data Acquisition
To continuously train the Physical World Large Model, we need to effectively acquire object manipulation structure data.
On one hand, we discovered the duality between human hand manipulation and object embodied knowledge. Therefore, we developed a human hand manipulation learning platform. By observing large amounts of hand operations, we can discover manipulation representations from them, helping the model acquire commonsense about manipulation topological structures.

On the other hand, an effective virtual environment that simulates the real world and supports physical interaction is essential. We independently developed the embodied intelligence simulator RFUniverse (RSS 2023 & IROS 2022 Best Paper). Combined with a series of machine learning techniques, RFUniverse can accelerate simulation of the physical world by 500x with error within 1mm, making simulated scenarios closer to real physical laws, and enabling large models to understand commonsense in a task-centric manner, achieving coupling between simulation and learning.
At this year's WAIC, our on-site demonstration of robotic arm-powered clothes folding showcased top-tier task-centric physical commonsense understanding capability. In the world of AI, the essential understanding of manipulation objects increases with their degrees of freedom: completely rigid bodies with no movement are six-dimensional, articulated bodies are 6+k dimensional, but flexible objects like clothes have infinite degrees of freedom. Therefore, completing folding operations from arbitrary initial states of clothing requires a tremendous breakthrough in object and manipulation commonsense understanding. This research also made us the first Chinese team in history to receive a Best System Paper nomination at the top international conference RSS 2023, and we believe we are also the first team globally to present complete clothes folding at a public exhibition.

Based on understanding operational physical commonsense, we also need to acquire sufficient force-position hybrid manipulation data. Traditional position control large models only need to acquire position information, but having only position without force makes terminal operations insufficiently robust and generic.
Currently, we are already using various combined data solutions and equipment. For example, through the world's only high-precision force-feedback teleoperation platform, we acquire high-precision aligned force-position hybrid data, achieving "Pao Ding's dissection of an ox" level precision. We also built a mechanical structure fully-mapped exoskeleton data collection platform that training personnel can wear anywhere, enabling convenient, scalable, and low-cost source data collection.

Using these data generation solutions as tools, we participated in building the largest open-source real robot dataset to date, the Open X-Embodiment Dataset, which already contains over one million real robot trajectories from 22 robots, cited repeatedly by many authoritative figures. We welcome everyone to use it as well.
04
Noematrix Brain:
Universal Agent Brain + Generalized Skill Library
Built upon all the technological积累 shared above, we officially released at this year's WAIC an embodied intelligence universal brain for the public: Noematrix Brain.
Noematrix Brain features a full-stack embodied intelligence technology framework, providing "force-centric" embodied intelligence large models (the Physical World Large Model and the Robot Behavior Large Model), the atomic skill library AnySkill, foundational software frameworks, and related developer toolchains. It can be organically integrated with various types of robot bodies and even industrial equipment, helping robots easily master more skills and enable more applications.
Beyond the brain itself, at the practical solution level, we can provide customers with highly generalizable, reusable software-hardware integrated platforms that meet diverse scenario requirements through modular combinations of different hardware forms.
Additionally, based on Noematrix Brain, Noematrix offers an ever-expanding robotic atomic skill library AnySkill, enabling agents to possess general manipulation capabilities. The general grasping skill AnyGrasp, first released in 2021, is a representative example. At its initial release, AnyGrasp was already unrestricted by object type or flexibility, capable of directly grasping unknown objects with extremely fast detection speed, becoming the first in the world to enable robotic grasping speed to reach human levels. Through continuous optimization, AnyGrasp now possesses various generalization capabilities including dynamic object grasping, high-precision force-aware grasping, and diverse texture handling.
AnySkill, in my view, is essentially a Scaling Law by skill. It can drive a capability leap by pushing the robustness and generality of foundational skills to 99.X%, producing an observable qualitative improvement in growth. And the vast majority of human task completion is achieved through combinatorial arrangements of foundational skills. Therefore, AnySkill can support rapid development for various scenarios through diverse combinations of the most streamlined atomic general skill set, combined with assistance from language and vision large models.
In the future, through the continuous growth of unified models and atomic general skills, the commercial tasks we can unlock will multiply exponentially, until the unified model forms a skill space where all skills are sufficiently general to cover the entire industry.
When executors are empowered by embodied intelligence, they can become human assistants across many industries: tedious tasks like installing a screw on an industrial production line, dangerous tasks like disassembly and demolition in extreme scenarios, delicate tasks closely related to daily life like housework, cooking, and patient care... We will continue to use technology to drive industry progress, and look forward to this day arriving soon.
Recommended Reading

