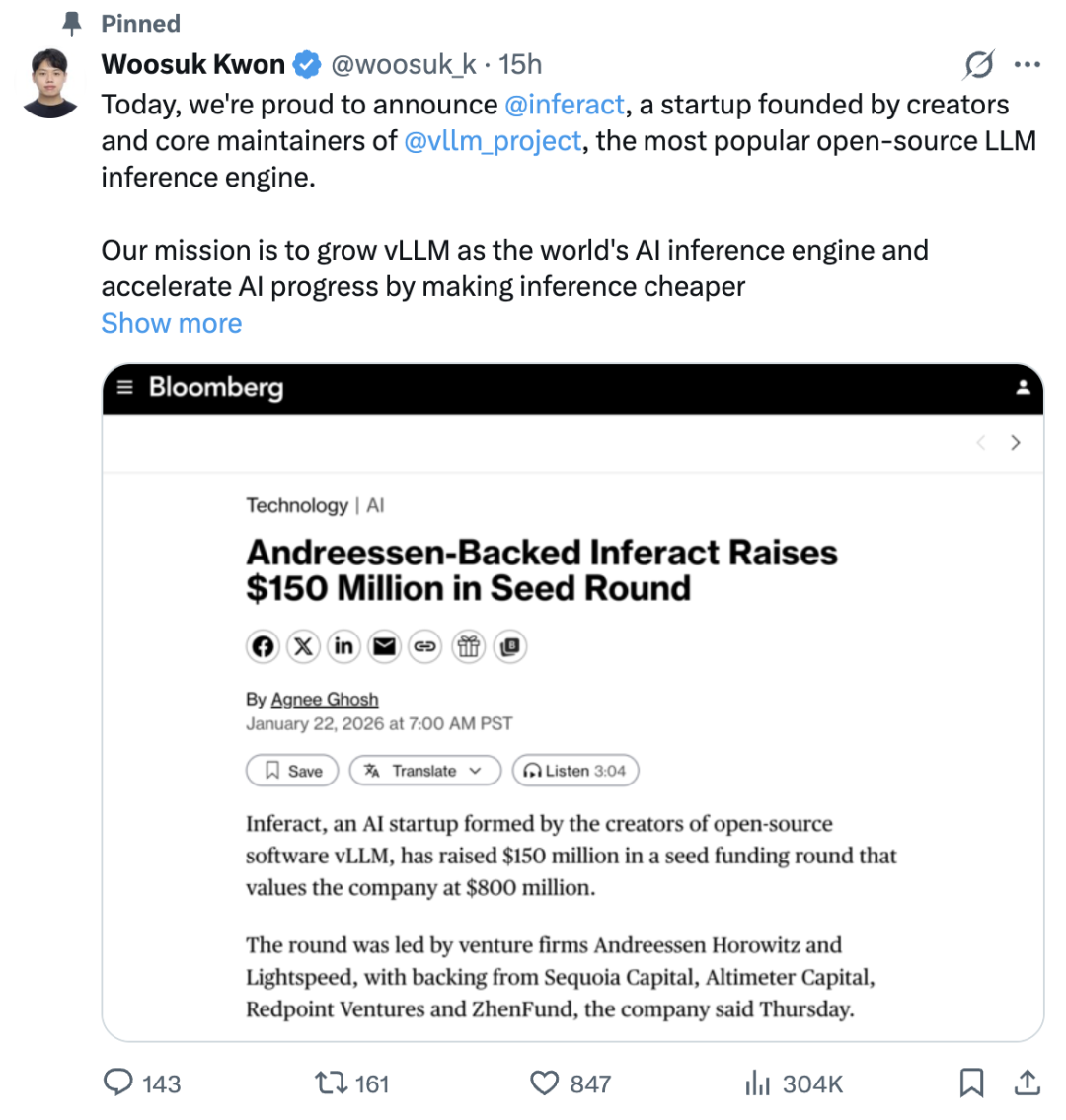
vLLM Team Launches Inferact and Closes $150 Million Seed Round, with ZhenFund Leading First Round

Building a world-class AI inference engine to accelerate the progress of the AI industry.

ZhenFund was an early donor to the open-source project vLLM. We've witnessed the team's forward-looking technical judgment and relentless pursuit of excellence, and we've been deeply moved by their outstanding contributions to the open-source ecosystem. We're thrilled to continue supporting Inferact, founded by the core vLLM team, from day one. Congratulations to founding team members Simon, Woosuk, Kaichao, Roger, Ion, and the rest! We look forward to seeing Inferact build a world-class AI inference engine under their leadership and accelerate progress across the entire AI industry.
Yusen Dai, Managing Partner, ZhenFund
On January 22, Inferact, an AI startup founded by the core team behind the open-source software vLLM, officially announced the completion of a $150 million seed round at an $800 million valuation. The round was led by Andreessen Horowitz and Lightspeed, with participation from ZhenFund, Sequoia Capital, Altimeter Capital, Redpoint Ventures, and other top-tier Silicon Valley VC firms.
Founded in November 2025, Inferact emerged from the long-term work of the vLLM community. vLLM is one of the most important open-source inference engines today and among the largest projects in the entire open-source world. It now supports more than 500 model architectures, runs on over 200 types of accelerators, handles real-world, large-scale inference workloads globally, and has accumulated more than 2,000 contributors. Companies including Meta, Google, and Character.ai have deployed vLLM in production. In July 2024, ZhenFund announced its donation to support vLLM, accompanying the core team all the way from an open-source project to where they are today.
Following Inferact's founding, Simon Mo from the vLLM core team will serve as CEO, Woosuk as CTO, and Kaichao (You Kaochao) as Chief Scientist. The team also includes co-founders Roger Wang, UC Berkeley computer science professor Ion Stoica, and more than a dozen founding members. Their mission is clear: to build vLLM into a world-class AI inference engine, accelerating progress across the entire AI industry by making inference cheaper and more efficient.
In a post on X announcing the company's launch, Inferact co-founder and CTO Woosuk Kwon wrote:
The AI industry is currently undergoing a clear shift: from insufficient and unstable training capabilities, it's rapidly moving toward resource constraints and execution efficiency at the inference stage. This has triggered an explosion in inference demand, likely superlinear in growth. As agents execute more steps and each step requires more tokens, inference workloads themselves are becoming increasingly complex.
Model sizes continue to grow, and new architectures keep emerging. From MoE to multimodality to agentic systems, nearly every breakthrough in model capabilities creates entirely new infrastructure requirements. Hardware is also fragmenting, with more types of accelerators, more programming models, and more combinations that need optimization.
A widening gap is forming between model capabilities and the systems that support them. The most powerful models are constrained by compute bottlenecks, with their full potential unlocked only by a handful of teams with customized infrastructure capabilities. And this problem is intensifying. Inference is evolving from a "small portion" of compute resources to the "absolute majority": test-time compute, RL training loops, and synthetic data generation are all driving inference demand higher.
Only by closing this gap will new possibilities truly open up.
This philosophy traces back to vLLM's origins.
In 2022, before ChatGPT's release, the vLLM team had built a large language model demo internally at UC Berkeley. What they deployed on their servers was Facebook's OPT-175B, intended to showcase alpha, a research project on automated model serving and inference. But during deployment, the team quickly found the demo ran sluggishly with extremely low GPU utilization. This led them to realize: the bottleneck for large language models wasn't just the models themselves — system-level issues during inference were equally critical. As models scaled, optimization at the model layer alone was no longer sufficient.
In a 2024 appearance on ZhenFund's podcast "True Words," Inferact CEO Simon Mo shared: "During inference, single-point operator optimization certainly matters, but what truly moves the needle is system-level optimization across requests and tasks. At the time, there was virtually no open-source system specifically designed for LLM inference optimization, so we decided to build one ourselves from scratch."
Through subsequent work, the team further identified GPU memory management as the core bottleneck. Traditional memory management approaches involved massive waste, severely limiting throughput and concurrency. After multiple iterations, the vLLM team proposed a new attention computation method called PagedAttention, drawing on paging and virtual memory mechanisms from operating systems to manage the KV Cache used in Transformer attention. This significantly reduced memory overhead and improved overall throughput. This technical breakthrough became a foundational moment for both vLLM and Inferact.
vLLM sits at the critical intersection of models and hardware, a position built up over years of painstaking refinement.
Much like Apache Spark, Ray, and other Berkeley-born projects that grew into unicorns, Inferact has gathered extensive contributions from exceptional developers through the sustained operation of an open-source community used by top global companies, while forging a team that pushes the boundaries of intelligence with a clear sense of mission.
Berkeley's open-source tradition is fundamentally a "collision mechanism" — one where the latest academic ideas meet real production environments and use cases, and where exploratory research thinking constantly rubs against pragmatic engineering orientations from industry. Both sides learn from each other, ultimately producing open-source projects that are both practical and capable of driving paradigm shifts.
This mechanism is evident in vLLM's growth trajectory. When model vendors release new architectures, they collaborate with vLLM first to ensure day-zero support. When hardware vendors design new chips, they integrate directly with vLLM. And whether it's frontier research labs, cloud providers, or startups serving millions of users, vLLM is what runs in production when they deploy at scale. This ecosystem, built collectively by more than 2,000 contributors, constitutes the most solid and most difficult-to-replicate foundation for both vLLM and Inferact.
Inferact has stated that the company's top priority remains supporting vLLM as an independent open-source project, with all improvements contributed back to the community. At the same time, Inferact will develop commercial products to help enterprises run AI models more efficiently and reliably across different types of hardware.
The future Inferact envisions: AI deployment and serving will become as effortless as infrastructure.
In the closing of his announcement post, Woosuk Kwon offered this outlook: "Deploying a frontier model at scale still requires an entire team of infrastructure specialists. In the future, this should be as simple as spinning up a serverless database. The complexity won't disappear — it will be absorbed into the infrastructure that Inferact is building."



