Attention转个方向,Transformer动到了骨髓

Kimi新架构AttnRes


自 2017 年问世以来,Transformer几乎成了现代AI的通用底座。 它有两个核心机制:Attention负责在序列维度上选择信息——面对一段话,决定"看哪个词";残差连接(Residual Connection)负责在深度维度上传递信息——把前面层的计算结果一路传下去。
前者被反复研究和改进,后者则一直以最朴素的形态存在:每一层的输出直接加到下一层的输入上,权重恒为 1,所有层不分主次。
这个设计来自 2015 年的ResNet。它解决了深层网络的梯度消失问题,让上百层乃至上千层的网络成为可能,也间接让Transformer成为可能。但它的工作方式极其"平权"——每一层的贡献被同等对待,没有优先级。
打个比方:一个学生上了40节课,期末复习时把所有笔记等量地堆在一起——不管哪门课跟考试相关,每门课都占同样的复习时间。
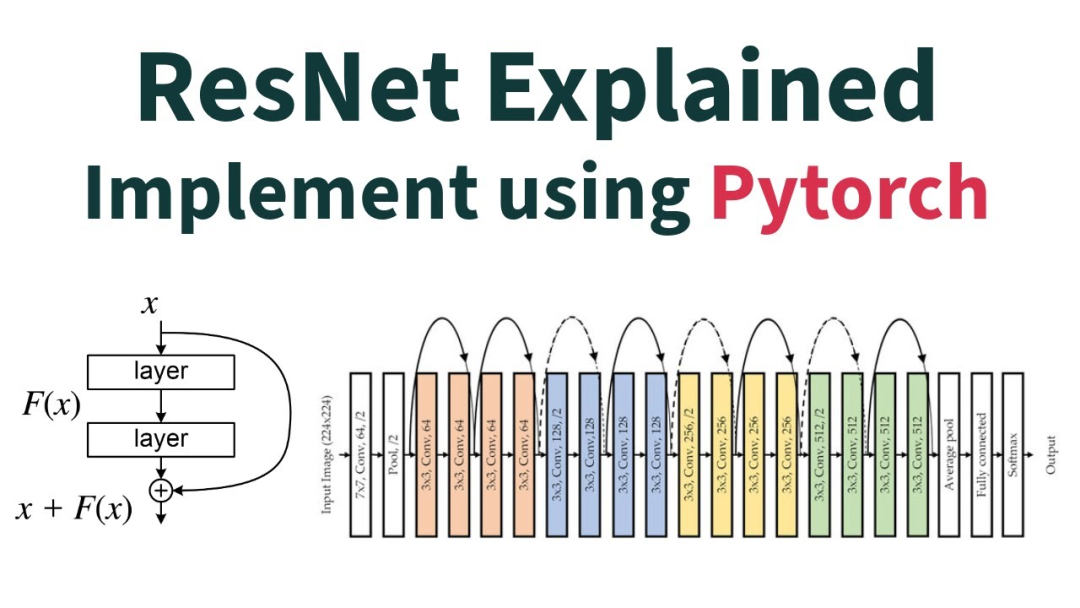
随着模型越来越深,这种"平权"的代价越来越高:早期的重要信息被后来的噪声稀释,不同层之间的重要性差异被掩盖,整体效率持续下降。
实证研究甚至发现,许多大模型中相当一部分层可以被直接删除而几乎不影响性能——换句话说,模型并没有在有效地使用自己的全部深度。
Kimi团队(Moonshot AI)发布的论文Attention Residuals(AttnRes),针对的正是这个问题。
他们的核心思路非常直觉:既然Attention在序列维度上已经证明了"让模型自己选择看哪里"远好于固定规则,那同样的逻辑能不能用在深度维度上——让每一层自己选择"听谁的"?
具体做法是:每一层拥有一个可学习的查询向量(query),用它对所有前序层的输出做attention,得到一个加权组合作为自己的输入。哪些前序层对当前计算更重要,权重就更高;不重要的,权重自动降低。
回到刚才的比方:现在这个学生有了一套智能复习系统——做每道题之前,系统会根据题目内容自动从40节课的笔记中挑出最相关的几份重点看,而不是让你翻完全部。
工程上,为了避免深层模型的计算开销失控,论文提出了一个实用变体Block AttnRes:将连续若干层划为一个block,block内部仍用普通残差连接,block之间再做attention。实测大约8个block就能恢复绝大部分收益,推理延迟增加不到 2%——几乎是免费的。
效果相当扎实。
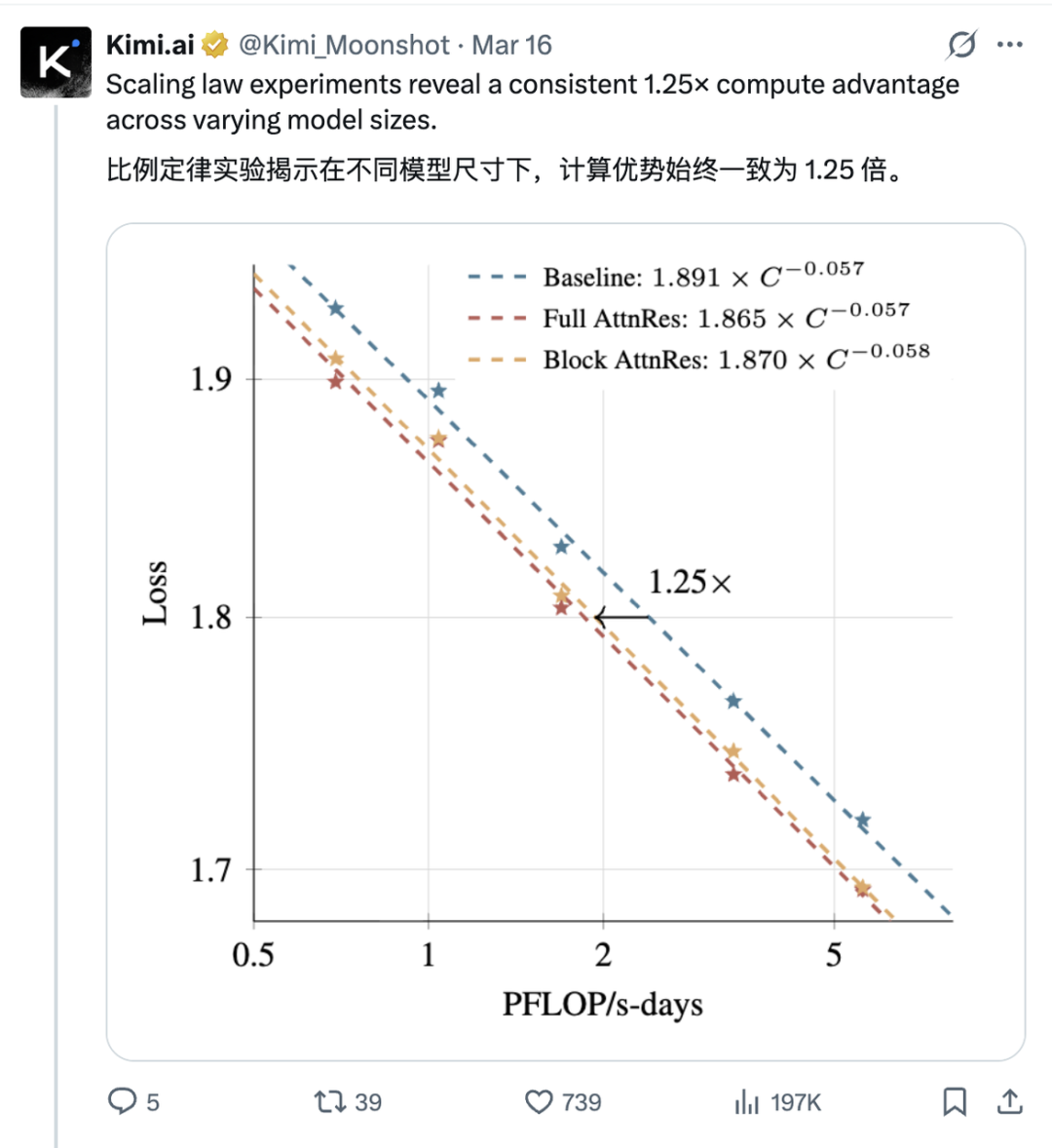
在scaling law实验中,Block AttnRes的表现相当于让基线模型多用了25%的训练算力。反过来说,达到同等性能所需的训练预算可以降低约20%。 对于正在激烈军备竞赛中的各家模型公司来说,这是实打实的成本优势。
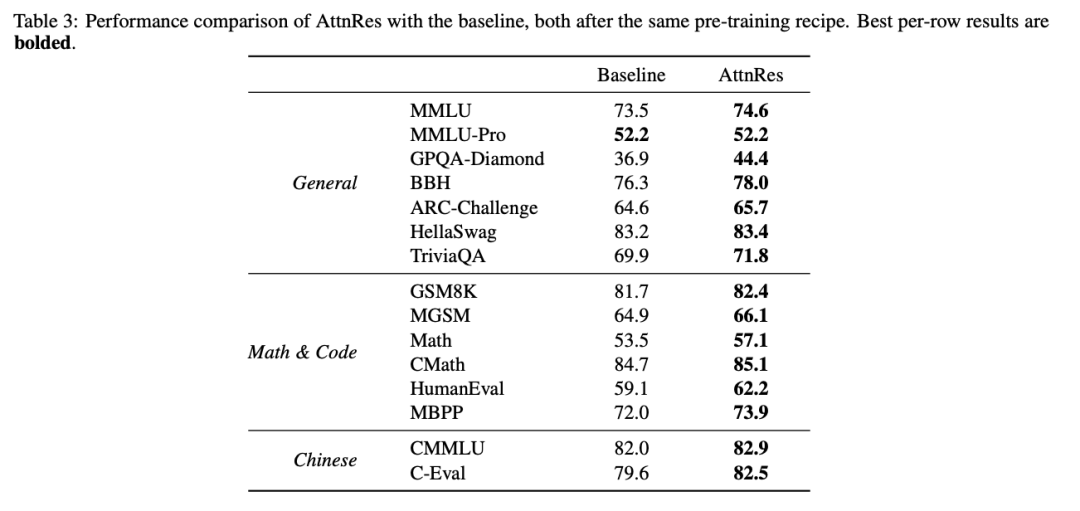
在一个48B参数的MoE模型上,AttnRes在几乎所有下游任务上取得了一致提升——科学推理GPQA-Diamond提升7.5分,数学Math提升 3.6 分,代码HumanEval提升3.1分。与此同时,模型的梯度分布和隐藏状态幅度都变得更加均匀,训练动态显著改善——不只是结果更好,过程也更健康。
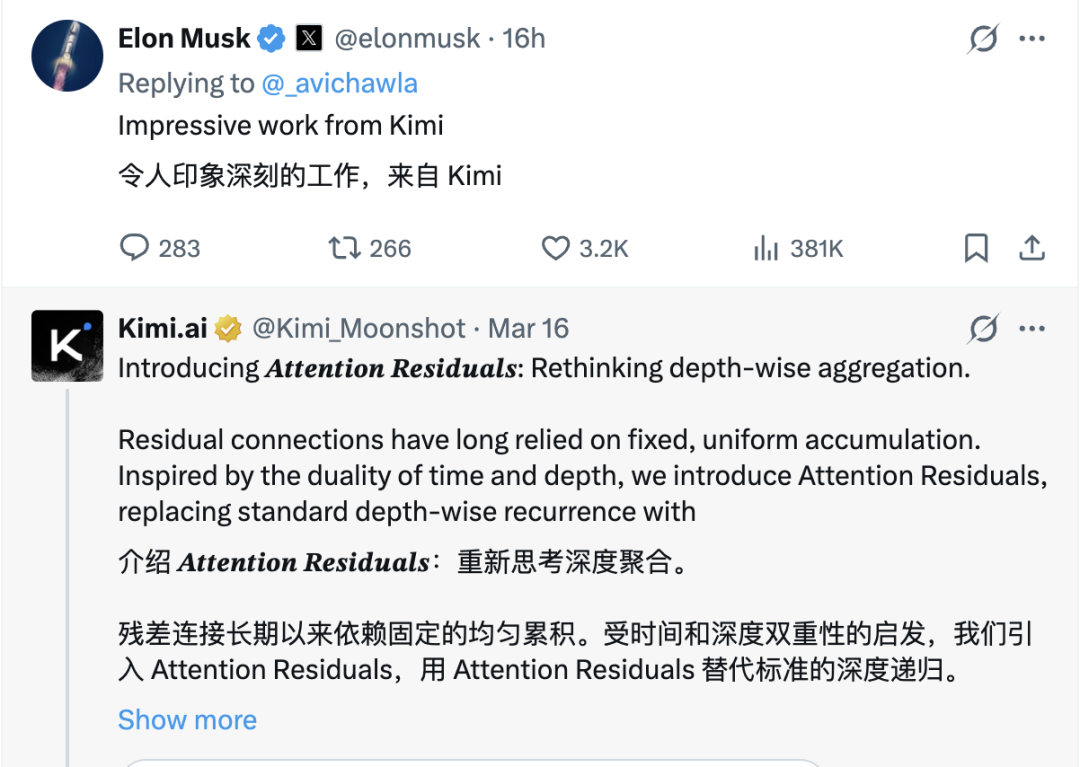
论文发布后迅速引发关注。Elon Musk在X上直接评价:"Impressive work from Kimi"。Andrej Karpathy的回应更耐人寻味——他半开玩笑地说,我们是不是没把"Attention is All You Need"这句话理解透彻?前 OpenAI 研发副总裁、被誉为“o1/o3系列推理模型之父”Jerry Tworek则直接称之为"deep learning 2.0 is approaching"。

Ilya Sutskever曾说过,LSTM就是旋转了90度的ResNet。AttnRes证明,Attention也可以旋转90度——从序列维度转向深度维度。
AttnRes给我们带来了什么启示?短期看,它是一种训练效率优化:同等算力下获得更好的模型,或者同等性能下花更少的钱,这是肉眼可见的成本优势。
长期看,它指向一个更大的可能性:如果深度维度也变成了可学习的、动态的,未来的大模型可能不再是固定深度的前馈网络,而是根据输入内容在运行时动态调度不同层次的计算资源——简单的问题用浅层解决,复杂的问题才动用全部深度。
回头看过去十年,AI领域最大的几次范式跳跃——从固定特征到学习特征(深度学习),从固定序列处理到动态序列处理(Attention),从固定推理到动态推理(Chain-of-Thought)——本质上都是把某个"固定"的东西变成"可学习"的,AttnRes延续的也是这条主线。
当然,论文刚发布不久,还没有经过大规模复现和检验。架构创新从论文到产业落地之间有很长的路要走。
不过值得一提的是,AttnRes的诞生印证了Kimi一直强调的理念:技术突破来自人才密度和留存率。这也展现了一种结构性的技术审美——敢于质疑十年未动的基础假设,并给出简洁的回答。只有人才密度、团队黏性、技术审美,三者叠加才能解释为什么是这个团队做出了这个工作。
我们期待下一次"旋转"。


