GTC复盘:当“万物皆可Token”,谁在定义AI的身体与记忆 | 云启伙伴

聊点token之外的事

今年 GTC,一个出圈的关键词是"token"。
相比过往更多停留在技术细节层面的讨论,这一次 token 被放进了一个更大的语境。它开始成为 AI 工业体系中的基本计量单位。某种程度上,这也是 AI 竞争从"模型能力"走向"系统能力"的一个缩影。
而当能力可以被量化、被规模化之后,问题本身也开始发生转移: AI 不再只是"能生成多好的内容",更重要的还有"能不能在真实世界中稳定运行"。
于是,这一阶段的门槛,反而回到了几个朴素但关键的维度: 执行性、可靠性与上下文能力。
**在本届 GTC 上,云启被投自变量机器人、元戎启行、Zilliz 以不同形式亮相,恰好分别落在这三个维度之上,也为这场变化提供了更具体的注脚。本期「云启伙伴」**和你分享。
执行性
AI开始真正"做事"
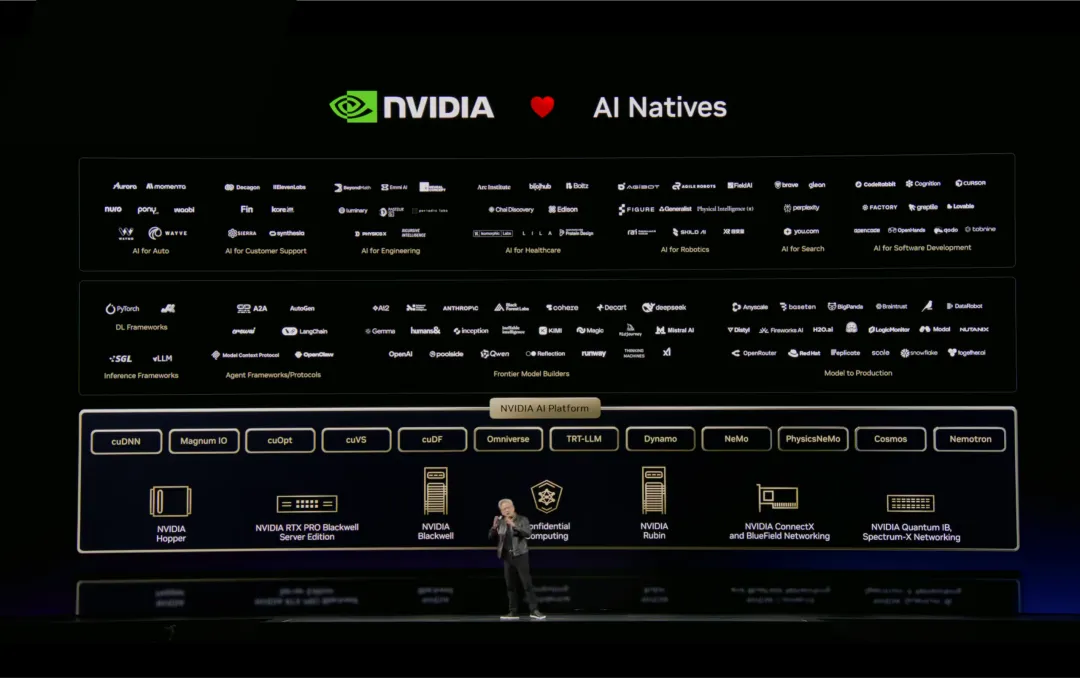
在 GTC 开场演讲中,黄仁勋公布了英伟达 AI 生态合作伙伴体系。「自变量机器人」作为唯一一家来自中国的企业,与 Physical Intelligence、Figure、Skild AI 一同出现在在 "AI for Robotics"板块。
这一位置更接近具身智能中"模型与能力定义"的层级,而非具体应用或系统集成。
进入该生态板块,本身也意味着自变量在具身智能模型方向上的技术路径与能力,已经进入全球主流技术视野。
从技术路径上看,自变量所代表的,是以 VLA(Vision-Language-Action)为核心的一类模型框架,尝试将感知、理解、决策与执行统一在同一体系中。
**这类模型的目标并不复杂:让 AI 的输出,从"信息",变成"可以被执行的动作"。
**在这一意义上,具身智能的重要性,不只是机器人形态本身,而在于它提供了一个新的能力边界: AI 开始具备对物理世界的执行能力。
可靠性
从"能跑"到"敢用"
如果说执行性回答的是"AI能不能做事",那么在真实世界中,一个更难的问题是这些能力,能不能被长期信任。**
随着城市 NOA 渗透率持续提升,辅助驾驶正在从"可用"走向"普及",但用户的实际使用意愿,却并没有同步提升。
这意味着,行业已经跨过了"技术是否成立"的阶段,进入需要稳定到可以被依赖的新区间。
在这一背景下,在今年 GTC 的主题演讲中,元戎启行 CTO 曹通义分享了用 Foundation Model 重构辅助驾驶体系的实践。
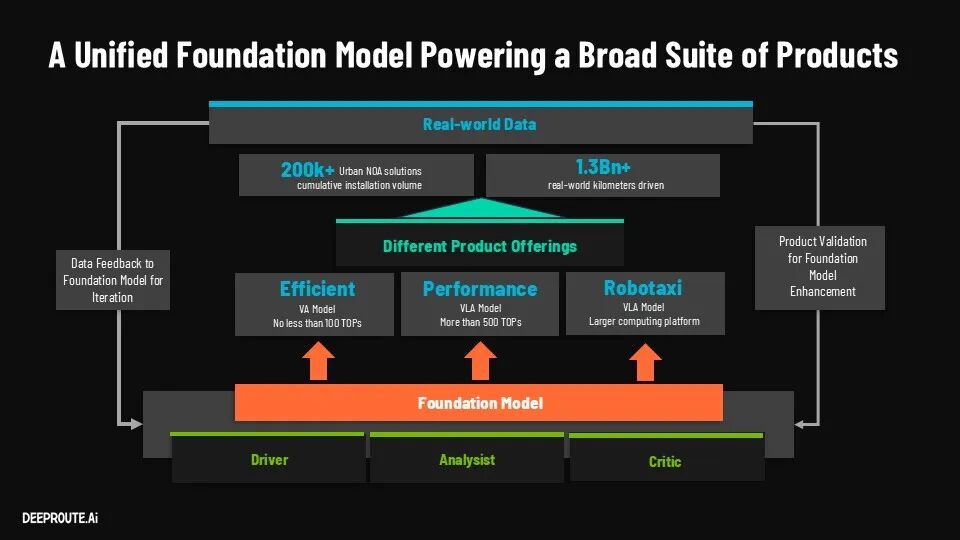
其关键不只是模型规模(40B 参数),还包括把理解交通场景、执行驾驶决策、评估驾驶行为等多种能力统一进同一模型。换句话说,系统不再只是"做出一个动作",而是开始具备对自身决策的理解与校验能力。
还有一个关键变化发生在系统迭代方式上:数据闭环周期,从约 5 天缩短至 12 小时。 这也大幅提升了研发效率。
与此同时,这套体系已经进入规模化运行。截至目前,元戎启行已量产交付超过 25 万辆,正向百万级规模推进。这些数据本身即是系统可靠性的证明。
上下文能力
AI系统的上限在哪里
在今年 GTC 上,黄仁勋在展示数据基础设施版图时提到:"Unstructured Data is the Context of AI."**
非结构化数据包括文本、图片、视频、日志、传感器信号。它们不再只是被存储的历史资产,而开始成为 AI 系统运行的核心上下文。
但问题在于:这些数据长期存在,却很难被有效利用。它们无法被索引、难以被检索,也难以参与到实时决策之中。
这也是为什么在这张版图中,Milvus(Zilliz)所代表的向量数据库,会被放在一个更关键的位置。
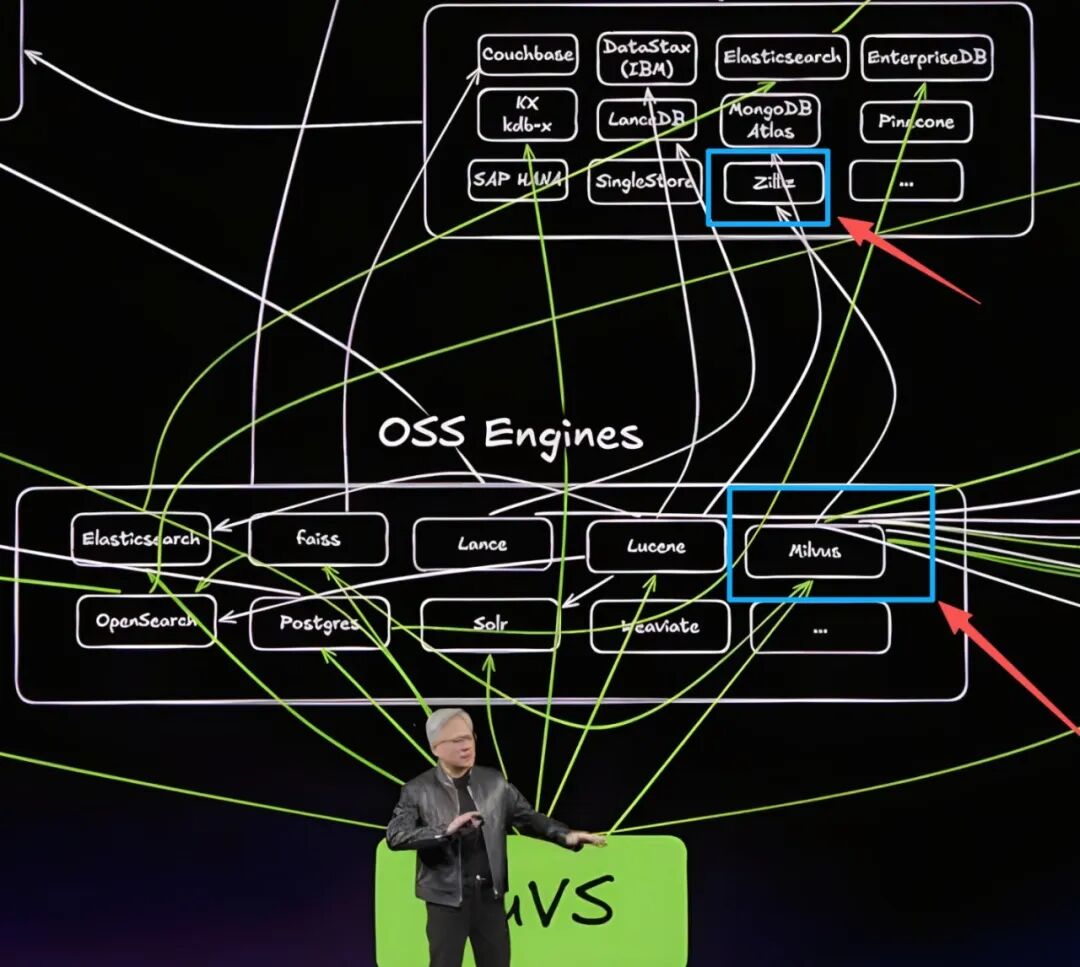
**本质上,它解决的是一件事:让非结构化数据可以被"用起来"。
从这个角度看,向量数据库的重要性,并不只在于"搜索更快",还在于它改变了数据参与 AI 的方式——从静态存储,变为可被实时调用的上下文。
但随着 AI 应用从单次调用走向持续运行,这些问题也在升级:数据规模快速膨胀、成本与延迟成为瓶颈、在线服务与离线优化相互割裂。
在这种背景下,Zilliz 提出 AI Lakebase,作为面向非结构化数据工作负载的一种基础设施升级方向。它试图解决一个更核心的问题: 在不搬运数据的前提下,将存储、检索与计算整合为统一底座。
从具身模型,到智能驾驶系统,再到数据基础设施,AI 正走向一个更完整的系统形态。更多创新,正在发生。





