MiniMax开源超强性价比推理模型,未来四天连续“上新” | 云启伙伴

创新脚步不停

创新力量的迭代脚步从未停息。继一个月前上新语音模型、Orsta系列模型后,**云启天使轮项目、大模型独角兽MiniMax宣布将连续五天发布重要更新。**开场第一弹,是开源的首个推理模型——MiniMax-M1。
这也是全球首个开源大规模混合架构推理模型,多项基准测试超越或比肩DeepSeek-R1、Qwen3等多个开源模型。同时,鉴于两大重要技术创新,MiniMax-M1实现了业内领先的算力优势,性价比满满。一起在本期「云启伙伴」了解详情。
云启天使轮项目、大模型独角兽MiniMax开源推理模型“上新”。
6月17日,MiniMax 发布全球首个开源大规模混合架构的推理模型MiniMax-M1,并宣布在未来四个工作日连续更新。
据MiniMax介绍,M1在面向生产力的复杂场景中位处开源模型第一梯队,超过国内的闭源模型,接近海外的最领先模型,同时极具性价比。
长本文是M1的一个显著优势,其支持目前业内最高的100万上下文的输入,这一长度是DeepSeekR1的8倍,比肩闭源模型 Google Gemini 2.5 Pro ;推理输出上限则达到8万Token,达到业内最长水平。
“无限长的长文本能力是MiniMax团队一直在打磨的重要维度,对于做社交应用、情感陪伴应用,Agent等来说是很关键的技术。”云启合伙人陈昱在6月中旬举办的Waves 2025大会论坛上曾如是分析。
MiniMax-M1的长文本能力得益于一个重要技术创新——闪电注意力机制为主的混合架构。这一架构使得M1在进行长本文的上下文输入和深度推理时均有算力效率优势突出。MiniMax举例称,在用8万Token深度推理的时候,只需要使用DeepSeek R1约30%的算力。
另一大技术创新是强化学习算法CISPO,该算法通过裁剪重要性采样权重(而非传统token更新)提升了强化学习效率,**与混合架构创新共同促成M1高效的强化训练过程。**科技媒体“量子位”报道显示,MiniMax团队透露,只用了3周时间、512块H800 GPU就完成强化学习训练阶段,算力租用成本仅53.47万美元(约383.9万元)。
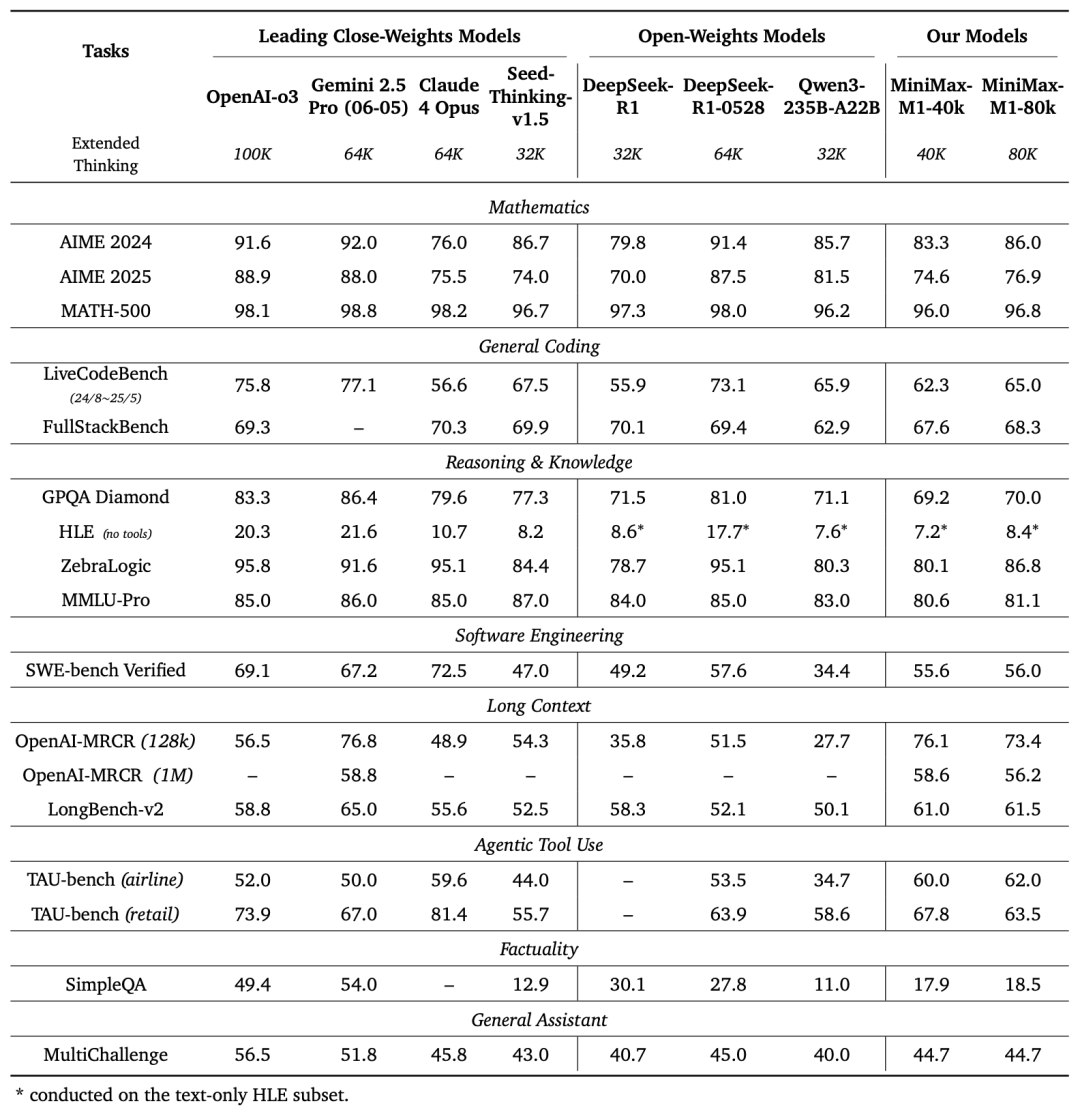
- M1在业内主流 17 个评测集上的测评结果
基于相对高效的训练和推理算力,MiniMax 宣布,**M1在MiniMax APP 和 Web 上都保持不限量免费使用,并以业内最低的价格在官网提供API,**提供了性价比优于DeepSeek-R1的用户方案。
风易变,规律常在。纵然AI行业瞬息万变,相信机会属于持续探索技术边界的行动实干派。 未来四天,欢迎关注MiniMax的更多更新,期待MiniMax推动AGI更多创新!





