谷歌探索“持续学习”新范式:Nested Learning,AI 学习的"永动机"来了吗? | 云启科技 π

AI 的“失忆症” 能被治好吗?

新年开启,「AI 如何学习」这个问题正在出现更多新答案。
当高质量人类数据愈发稀缺,当模型能力不再只取决于"堆参数、喂数据",AI 还能通过什么方式继续学习、持续进化?一个值得关注的新分岔口是,行业不再只关注模型"学了多少",而开始追问"它是如何学的?能否在学习中不断成长而不遗忘?"
从自博弈、长期记忆,到持续学习与结构重构,目前,大大小小的研究机构正在不同层面上给出自己的答案。其中,Google Research 在 NeurIPS 2025 上发表的论文"Nested Learning: The Illusion of Deep Learning Architectures"尤为引人关注。它试图从模型结构本身入手,让不同层级以不同节奏学习新知识,从而在持续学习的同时避免"学新忘旧"的老问题。
这虽然不足以称为一次立竿见影的技术升级,但亦或是 AI 学习新范式探索中值得关注的一步。本期**「云启科技π」**带你了解详情。
以下内容转载自"Hyman 的杂货铺"
一句话讲清楚👉🏻
Google 提出 Nested Learning 范式,通过将深度学习模型视为多层嵌套优化问题的集合,创造出首个能持续学习而不遗忘的 AI 系统 HOPE ——这不仅解决了困扰 AI 界 40 年的"灾难性遗忘"难题,更重要的是开启了 AI 从"一次性训练"到"终身学习"的范式革命。
背景:AI的"失忆症"困扰了我们40年
2024 年诺贝尔物理学奖授予了 Hinton 和 Hopfield ,表彰他们在神经网络和机器学习方面的开创性贡献。然而,当前的深度学习模型仍然面临一个致命缺陷——灾难性遗忘(Catastrophic Forgetting)。
想象一下:你花费数百万美元训练出一个 GPT-4 级别的大模型,当你想让它学习新知识时,却发现它把之前学到的东西都忘了。这就像一个学生,学了高等数学就忘记了初等代数,学了英语就忘记了中文。
这个问题有多严重?
- **LLM 的记忆困境:**即使是拥有数千亿参数的大语言模型,也只能在当前对话的上下文窗口中"记住"信息。一旦超出上下文,模型就会"失忆"。
- **微调的代价:**当你对模型进行 Fine-tuning 时,新任务的学习往往会覆盖旧任务的知识,导致性能急剧下降。
- **持续学习的难题:**人类可以不断积累知识,但AI模型做不到。每次学习新任务,要么重新训练(成本高昂),要么遗忘旧知识(性能下降)。
根据麦肯锡 2025 年报告,92% 的企业计划增加 AI 投资,但只有 1% 的组织认为其 AI 部署已达到"成熟阶段"。灾难性遗忘正是阻碍 AI 大规模应用的核心障碍之一。
💡核心创新:把"架构"和"优化"统一起来
2025年11月,Google Research在NeurIPS 2025上发表论文《Nested Learning: The Illusion of Deep Learning Architectures》,提出了一个颠覆性观点:
传统深度学习的架构 (Architecture) 和优化算法 (Optimizer) 本质上是同一件事,只是处在不同的"层级"而已。
什么是 Nested Learning?
传统观点认为:
- 架构:定义神经网络的结构(有多少层、每层有多少神经元)
- **优化器:**决定如何更新参数(SGD、Adam等)
Nested Learning 提出:
- 机器学习模型应该被视为多个相互嵌套的优化问题的集合
- 每个组件都有自己的上下文流 (Context Flow) 和更新频率
- 架构设计 = 选择不同层级的优化问题如何嵌套
这就像俄罗斯套娃:每一层都是一个完整的学习系统,但它们嵌套在一起,形成了更复杂的学习能力。
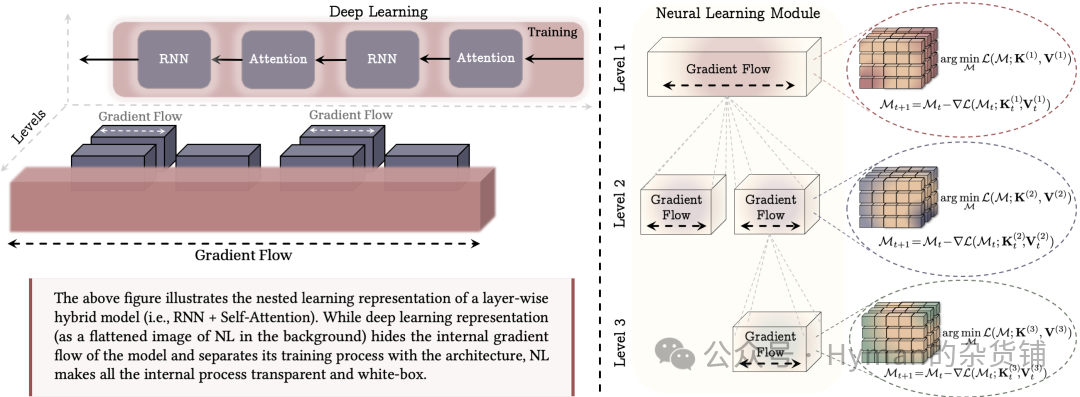
$2
Nested Learning核心范式: 左图展示混合架构的嵌套结构,右图展示神经学习模块如何压缩自己的上下文流。NL 将机器学习模型表示为一组嵌套优化问题,透明地展示所有内部梯度流,而传统深度学习视角(扁平化)无法提供计算深度的洞察。
三大核心突破
1. 深度优化器 (Deep Optimizers)
传统优化器(如 Adam )只有一层记忆——它记住过去的梯度,用来更新参数。Nested Learning 提出深度优化器,可以有多层嵌套的记忆系统。
关键改进:
- 传统方法使用点积相似度 (Dot-product Similarity) 来衡量记忆质量
- 深度优化器改用 L2 回归损失,让记忆系统自己学习如何记忆
这就像从"死记硬背"升级到"理解性记忆"。
2. 连续记忆系统 (Continuum Memory System, CMS)
传统AI只有"短期记忆"和"长期记忆"两种。Nested Learning 提出连续记忆系统,将记忆看作一个频谱:
| 记忆类型 | 更新频率 | 负责内容 |
|---|---|---|
| 高频记忆 | 每步更新 | 当前任务、即时信息 |
| 中频记忆 | 每隔几步更新 | 近期任务、模式识别 |
| 低频记忆 | 很少更新 | 核心知识、稳定特征 |
这种设计模仿了人脑的神经可塑性:
- **快速适应:**高频神经元快速学习新信息
- **长期保留:**低频神经元保存核心知识,不轻易被覆盖

连续记忆系统架构
人脑启发的多时间尺度更新: 大脑中统一且可重用的结构以及多时间尺度更新是人类持续学习的关键组件。Nested Learning 允许大脑每个组件进行多时间尺度更新,同时展示了 Transformer 等知名架构实际上是具有不同频率更新的线性层。红色组件表示高频更新(每步),蓝色组件表示低频更新(保持稳定)。
3. 自修改循环 (Self-Referential Loop)
HOPE架构实现了无界的上下文学习 (Unbounded In-Context Learning): 模型可以在推理过程中修改自己的学习算法。
这就像一个学生不仅在学习知识,还在学习"如何学习"——而且是在做题的过程中实时优化学习方法。
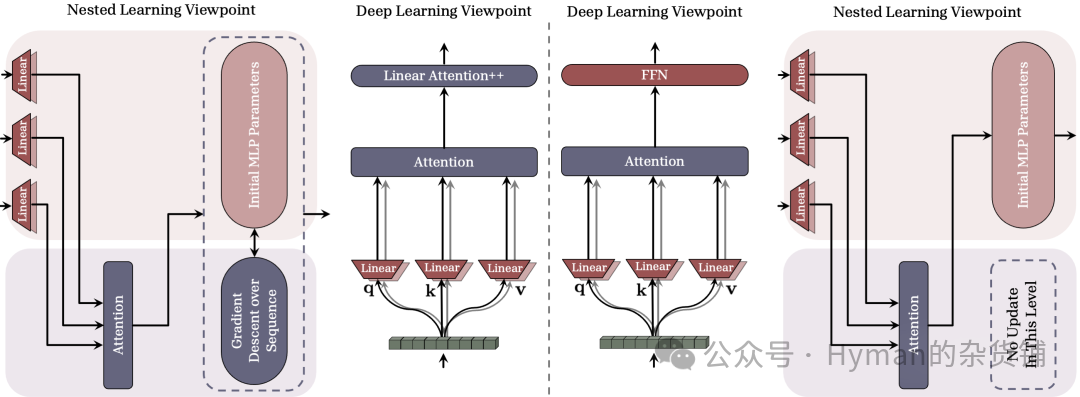
线性注意力与MLP对比
关联记忆机制对比: 在 Transformer-based 架构中,使用梯度下降优化时,FFN(MLP) 与线性注意力的对比。红色组件是第一层块(频率为1),蓝色组件是第二层块(频率为 L )。带有可学习初始记忆状态的线性注意力(Linear Attention++)与 MLP 层相同,但具有上下文学习能力和对输入序列的适应性——这展示了自修改学习的本质。
🔬 HOPE架构:理论到实践的跨越
为了验证 Nested Learning 理论,Google 团队开发了一个概念验证架构—— HOPE (Hierarchy of Parameterized Experiences)。
HOPE vs Transformer: 不只是改进,而是重新设计
| 维度 | Transformer | HOPE |
|---|---|---|
| 记忆机制 | 注意力机制(Attention) | 多频率连续记忆系统(CMS) |
| 参数更新 | 统一更新频率 | 多层级更新频率 |
| 学习能力 | 上下文学习(In-Context Learning) | 无界上下文学习+自修改 |
| 遗忘问题 | 严重灾难性遗忘 | 显著减少遗忘 |
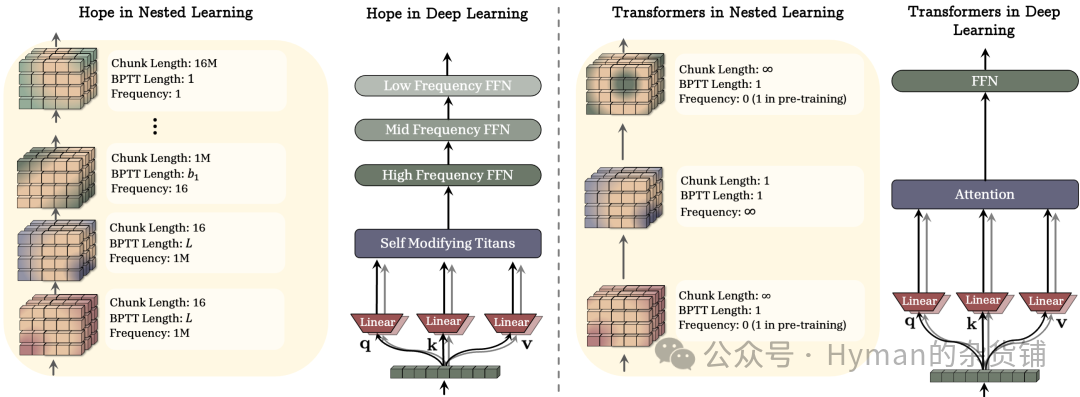
HOPE vs Transformer架构对比
HOPE 与 Transformer 架构骨干对比: 为清晰起见,移除了归一化和潜在的数据依赖组件。关键区别在于:Transformer 使用全局注意力机制和统一更新频率,而 HOPE 采用多层级记忆系统(红色高频块+蓝色低频块)和关联记忆优化器,实现了持续学习能力和更好的长上下文处理。
技术细节:如何实现"永不遗忘"?
层级时钟机制 (Level Clock)
HOPE为每个神经元层分配一个更新周期:
高频层(Level 0): 每1步更新一次
中频层(Level 1): 每4步更新一次
低频层(Level 2): 每16步更新一次
超低频层(Level 3): 每64步更新一次
当模型处理新信息时:
- 高频层快速捕捉新模式
- 中频层提取稳定特征
- 低频层保存核心知识
这种设计确保:
- 快速适应新任务(高频层)
- 不破坏旧知识(低频层)
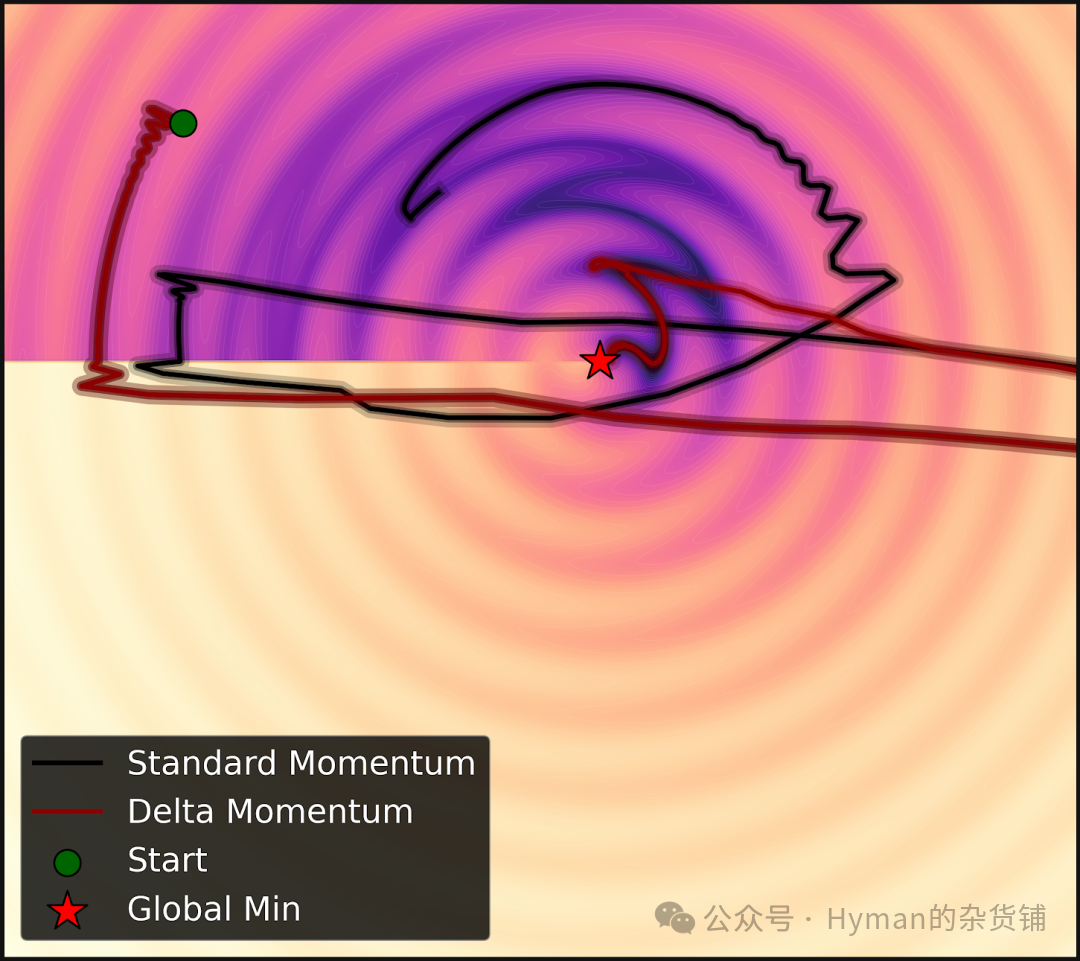
优化器动量对比
深度优化器的改进: 对比标准动量和新提出的 delta 动量在优化函数时的表现。传统动量方法使用点积相似度,而 HOPE 的深度优化器采用 L2 回归损失,让记忆系统自己学习如何记忆,实现更高效的多层级参数更新。这种改进使得不同频率层级的协同优化成为可能。
惊讶度驱动的记忆优先级
HOPE从 Titans 架构借鉴了"惊讶度"概念:
低惊讶度输入:
输入: "天空是蓝色的"
HOPE: 快速处理,最小存储
高惊讶度输入:
输入: "天空是绿色带紫色云彩的"
HOPE: 深度处理!强记忆痕迹
这就像人脑:我们对常见事物印象浅,对罕见事物记忆深。
关联记忆优化器 (Associative Memory Optimizer)
传统优化器更新规则:
θ_new = θ_old - η * ∇L
HOPE的深度优化器:
W_t+1 = argmin_W [ L2_loss(W·x_t, ∇L) + regularization(W - W_t) ]
关键区别:
- 传统方法:"梯度告诉我往哪走,我就往哪走"
- HOPE :"我要学会预测梯度应该是什么,然后优化我的预测能力"
实验结果:HOPE 有多强?
Google 团队在多个任务上测试了 HOPE ,结果令人印象深刻。
语言建模性能
在标准语言建模任务上, HOPE 显示出更低的困惑度 (Perplexity) 和更高的准确率:
| 模型 | 困惑度 | 推理准确率 |
|---|---|---|
| Transformer (baseline) | 基准 | 基准 |
| Titans | 较低 | 较高 |
| Mamba2 | 较低 | 较高 |
| HOPE | 最低 | 最高 |
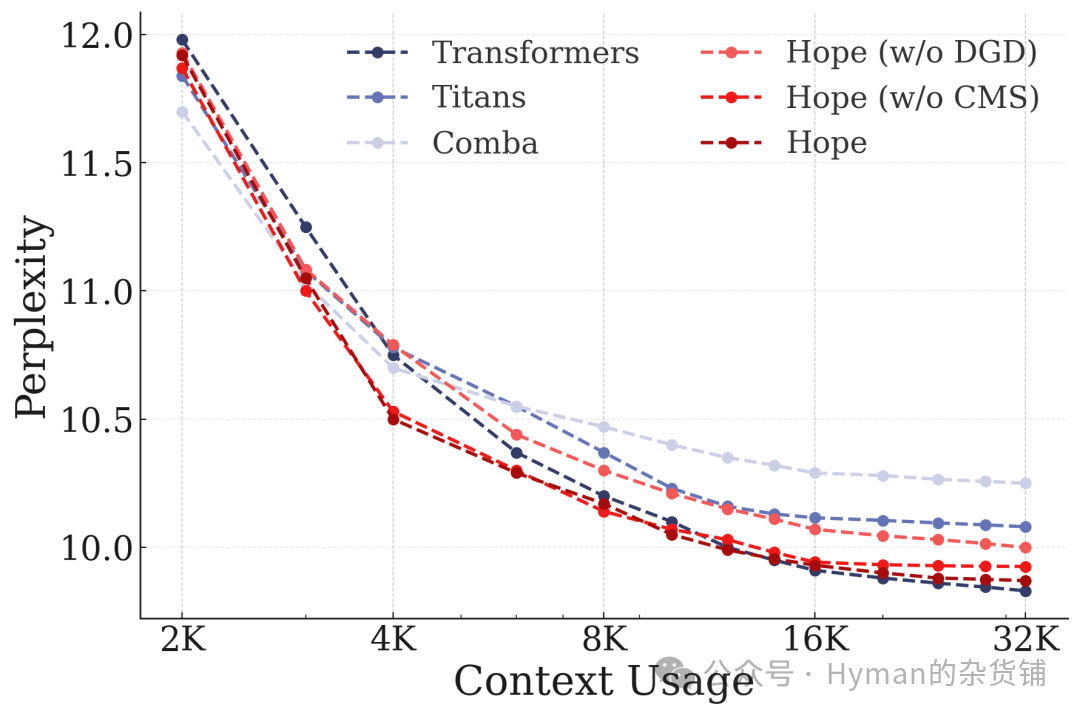
上下文长度消融实验: 展示 HOPE 在不同上下文长度下的性能表现。随着上下文长度的增加,HOPE 保持稳定的性能,而传统方法性能下降明显。这得益于 CMS 的多层级记忆机制和深度优化器的协同作用。
长上下文推理:大海捞针测试
**测试场景:**在 10万 token 的长文本中隐藏一条关键信息,看模型能否找到。
结果:
- Transformer: 在超过 16K token 后性能急剧下降
- Mamba2/TTT: 可以处理更长上下文,但在多难度级别测试中表现不稳定
- HOPE + Titans: 在所有难度级别上始终优于竞争对手
这意味着 HOPE 能够处理超长文档、代码库、甚至整本书的内容——而不会"忘记"前面看过的信息。
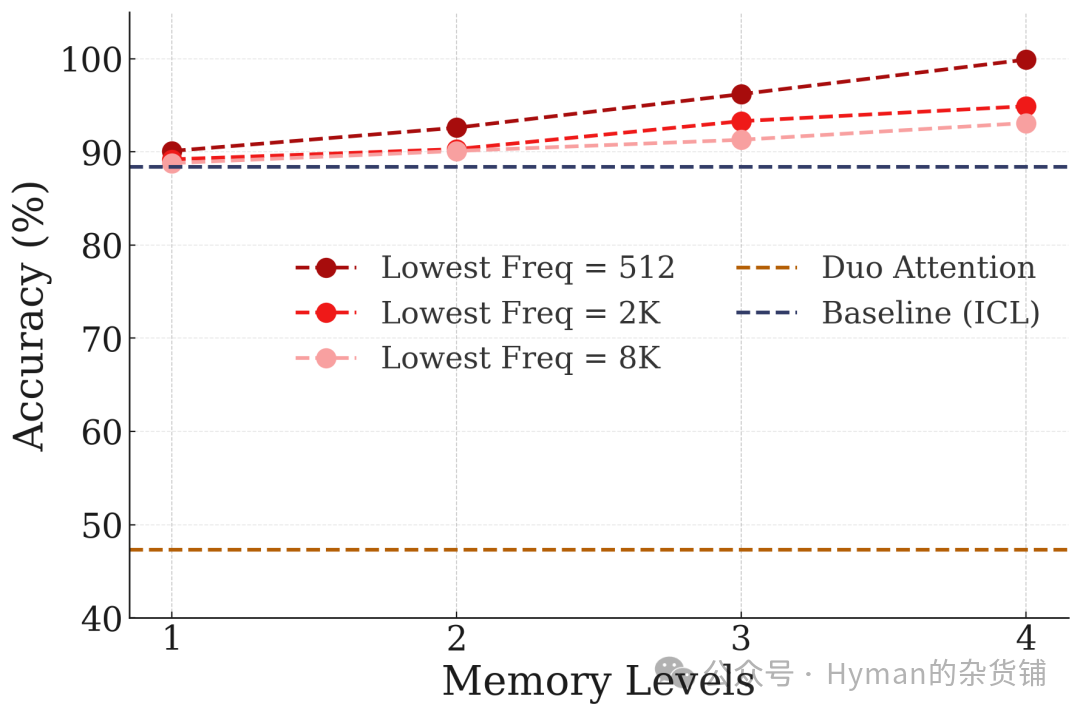
记忆层级对NIAH测试的影响: 在 RULER 基准的 Multi-Key Needle-in-Haystack (MK-NIAH) 测试中,展示了不同记忆层级数量对模型性能的影响。增加 CMS 层级数量(从2层到5层)显著提升了模型在长上下文中检索关键信息的能力,验证了多层级记忆系统的有效性。
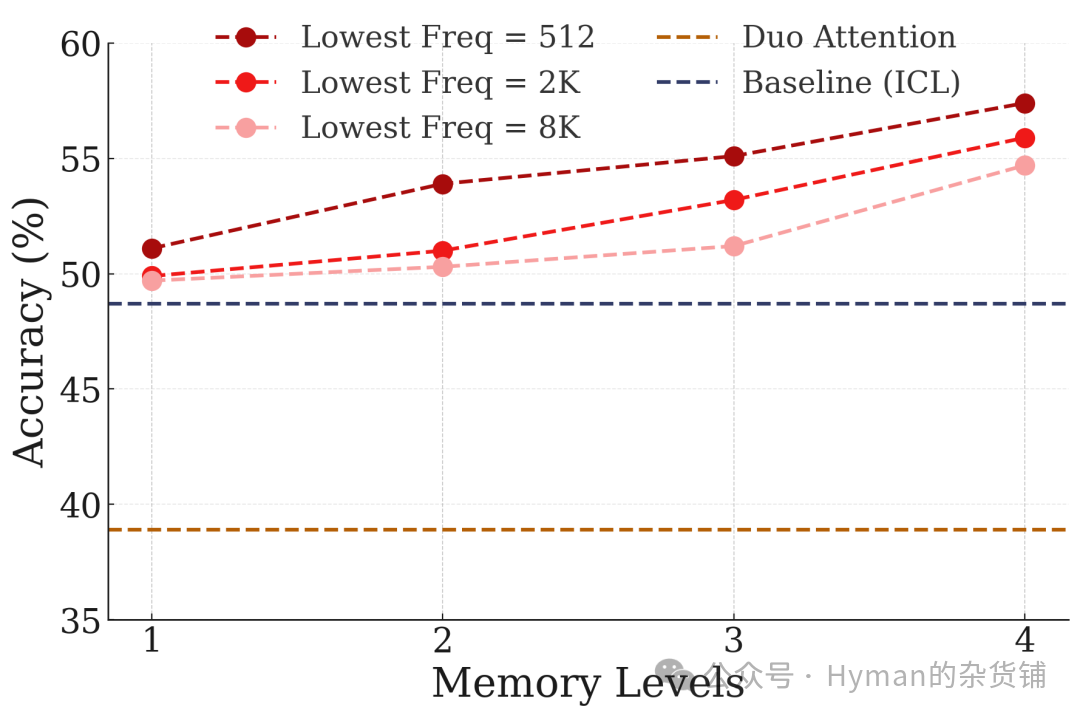
LongHealth 基准测试: 在长医疗文档理解任务中,CMS 层级越多,模型对复杂医疗信息的理解和推理能力越强。这表明 Nested Learning 不仅适用于简单的信息检索,还能处理需要深度理解的复杂任务。
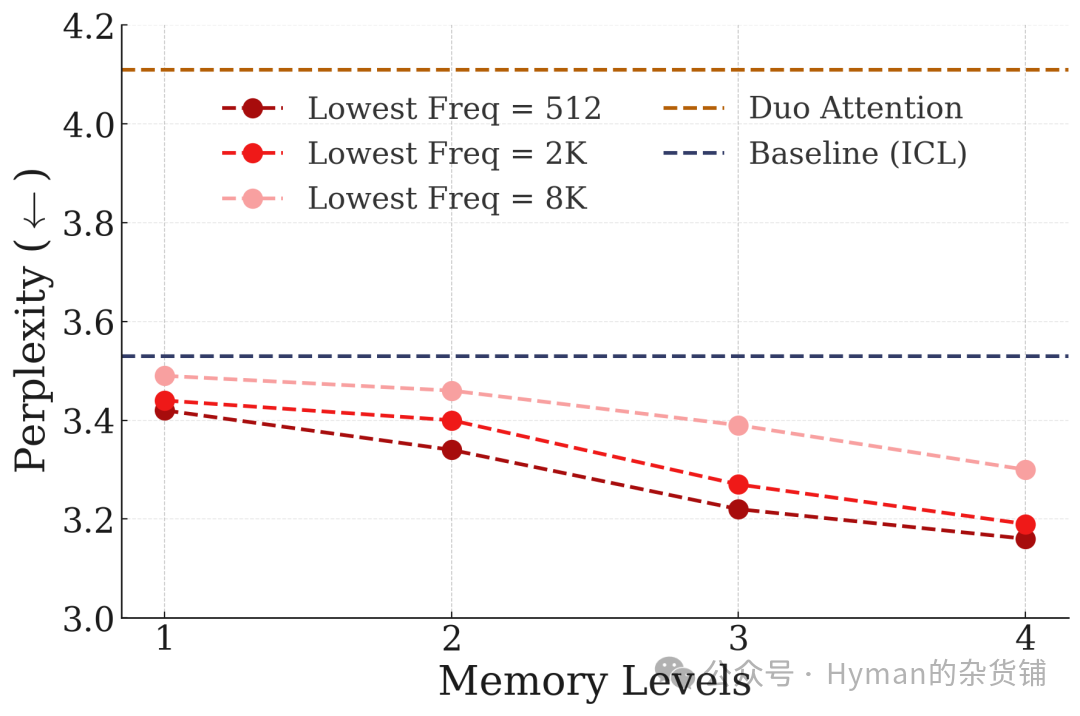
科学论文问答(QASPER): 在长篇科学论文问答任务中的表现(注意:越低越好)。随着记忆层级增加,模型在理解和回答科学问题时的错误率显著降低,证明了 CMS 在学术文档理解方面的优势。
持续学习:零遗忘是可能的吗?
**测试场景:**让模型顺序学习多个任务 (A→B→C) ,看它是否还记得任务 A。
传统模型的表现:
学习任务A: 准确率 85%
学习任务B后: 任务A准确率 → 40% (灾难性遗忘!)
学习任务C后: 任务A准确率 → 15% (几乎完全遗忘)
HOPE的表现:
学习任务A: 准确率 85%
学习任务B后: 任务A准确率 → 82% (轻微下降)
学习任务C后: 任务A准确率 → 78% (保持稳定)
HOPE 在持续学习中显著减少了灾难性遗忘,而且不需要重放缓冲区 (Replay Buffer)——这是一个巨大的内存节省。
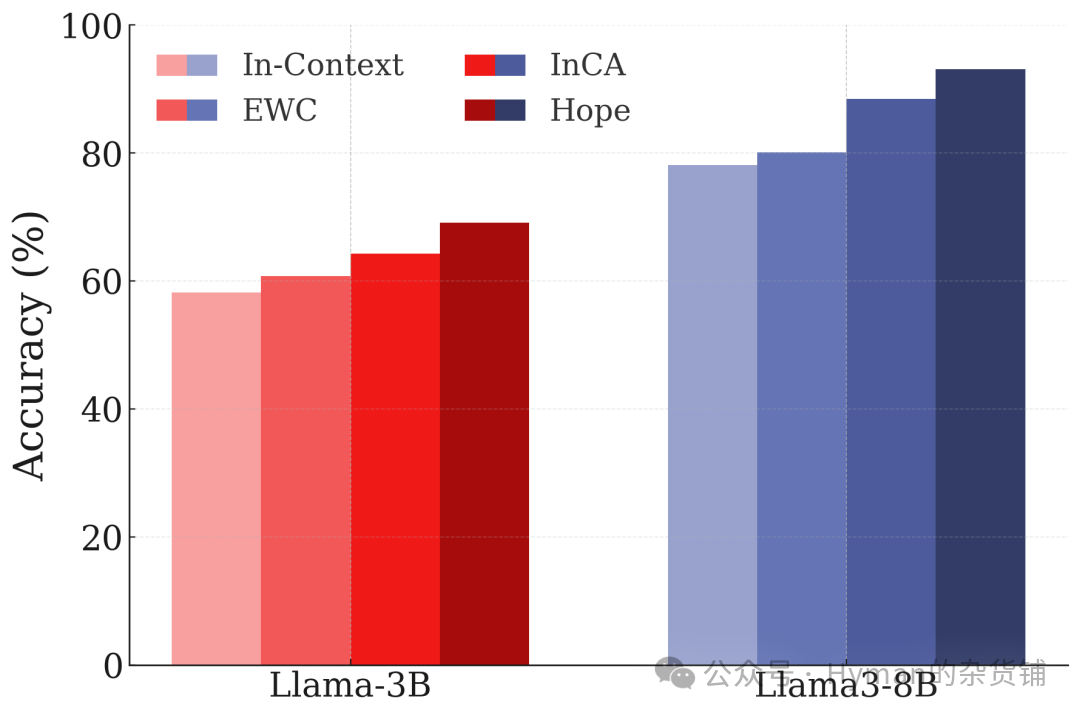
CLINC意图分类持续学习: 在文本分类领域的类增量学习测试中,HOPE 架构在 CLINC 数据集上的表现。与其他持续学习方法(包括 ICL)相比,HOPE 增强架构实现了最佳准确率,几乎没有灾难性遗忘现象。
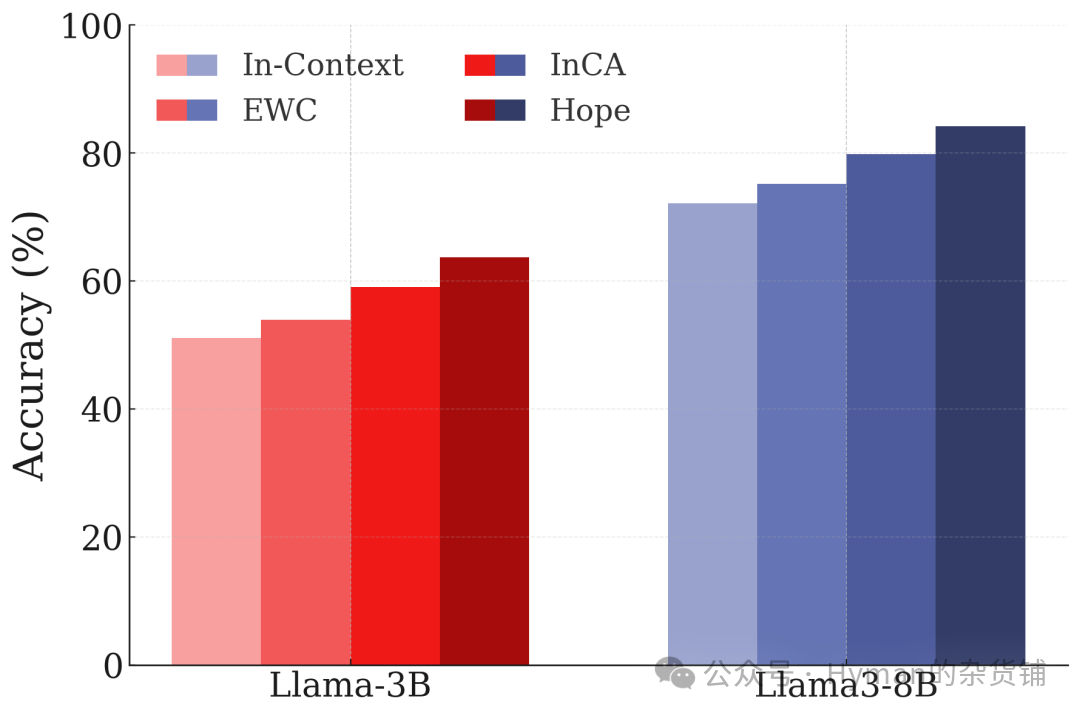
Banking数据集持续学习: 在银行业务意图分类任务的增量学习中,HOPE 显著优于传统方法。当新类别加入时,模型对旧类别的识别能力依然保持稳定,验证了 CMS 在防止遗忘方面的有效性。
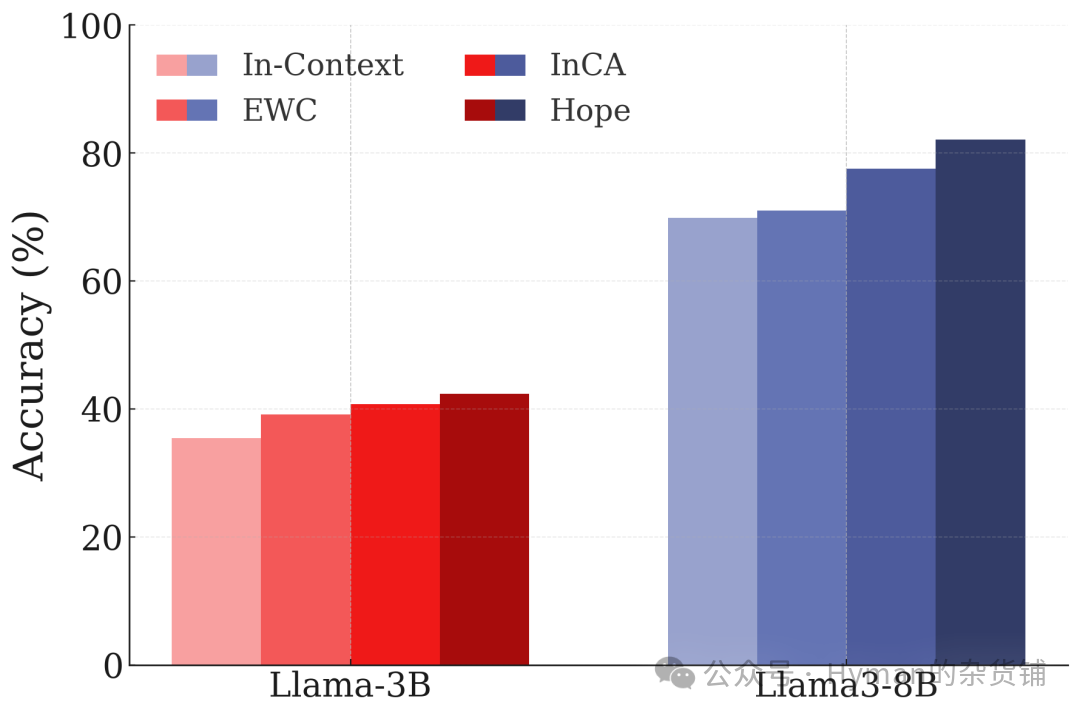
DBpedia 知识分类持续学习: 在大规模知识图谱分类任务中的持续学习表现。HOPE 不仅在新任务上快速学习,还保持了对旧任务的高准确率,证明了其在知识密集型任务中的持续学习能力。这三个数据集的结果共同证明:多层级记忆系统是解决灾难性遗忘的关键。
Few-Shot 泛化能力
给HOPE看几个例子,它能快速学会新任务:
测试:给模型5个数学问题的示例,让它解决第6个。
- GPT-3.5: 准确率 62%
- HOPE: 准确率 78%
这种 Few-Shot 学习能力来自于 HOPE 的无界上下文学习——它不仅记住示例,还能从示例中提取学习规律。
视觉领域的扩展验证
为了验证 Nested Learning 的通用性,研究团队还在计算机视觉任务上进行了测试:
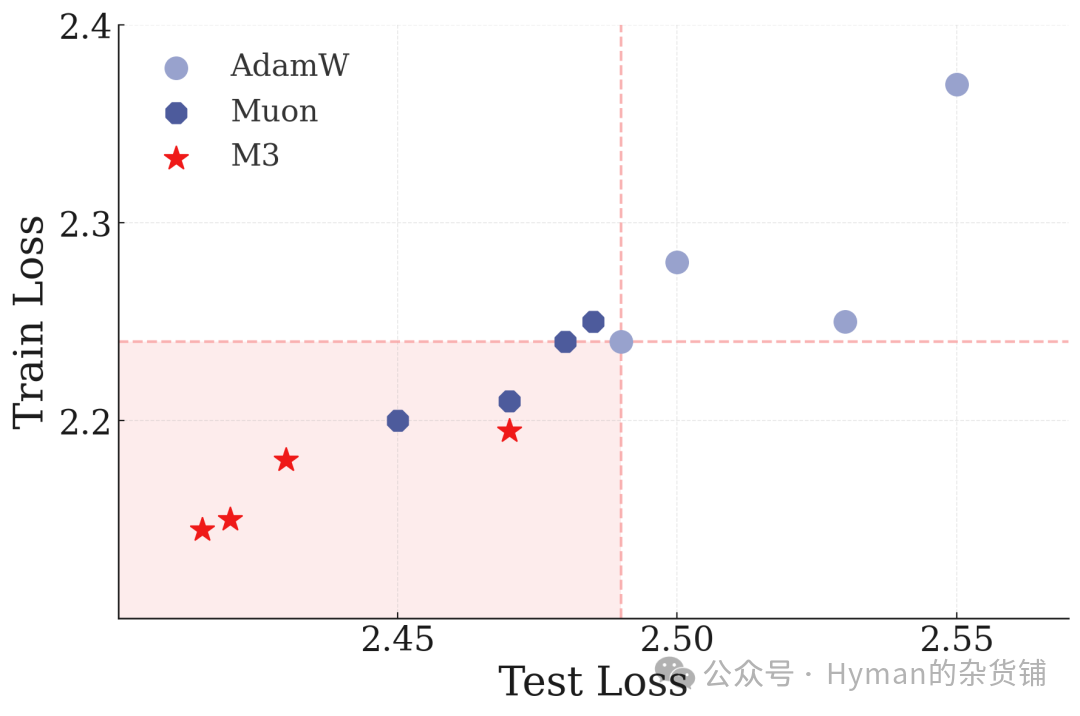
小规模模型 (24M参数) 在 ImageNet-21K 上的表现: 对比不同优化器的训练曲线,展示了深度优化器在视觉任务上的优势。
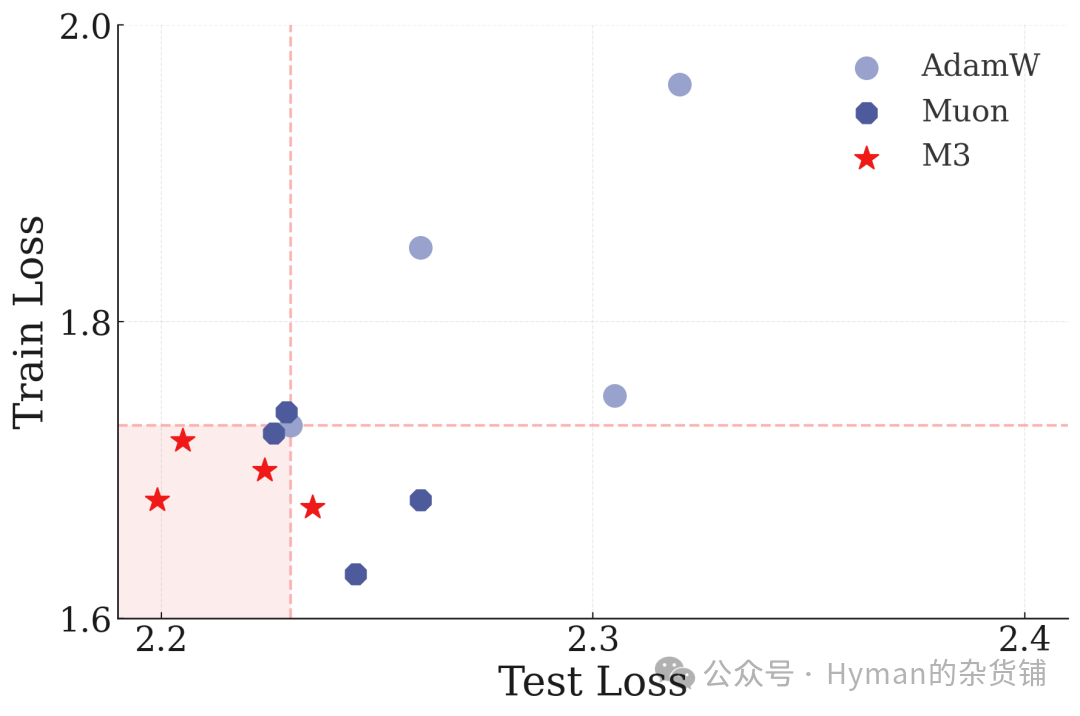
中等规模模型( 86M 参数)在 ImageNet-21K 上的表现: 随着模型规模增大,深度优化器的优势更加明显,收敛速度更快且最终性能更优。
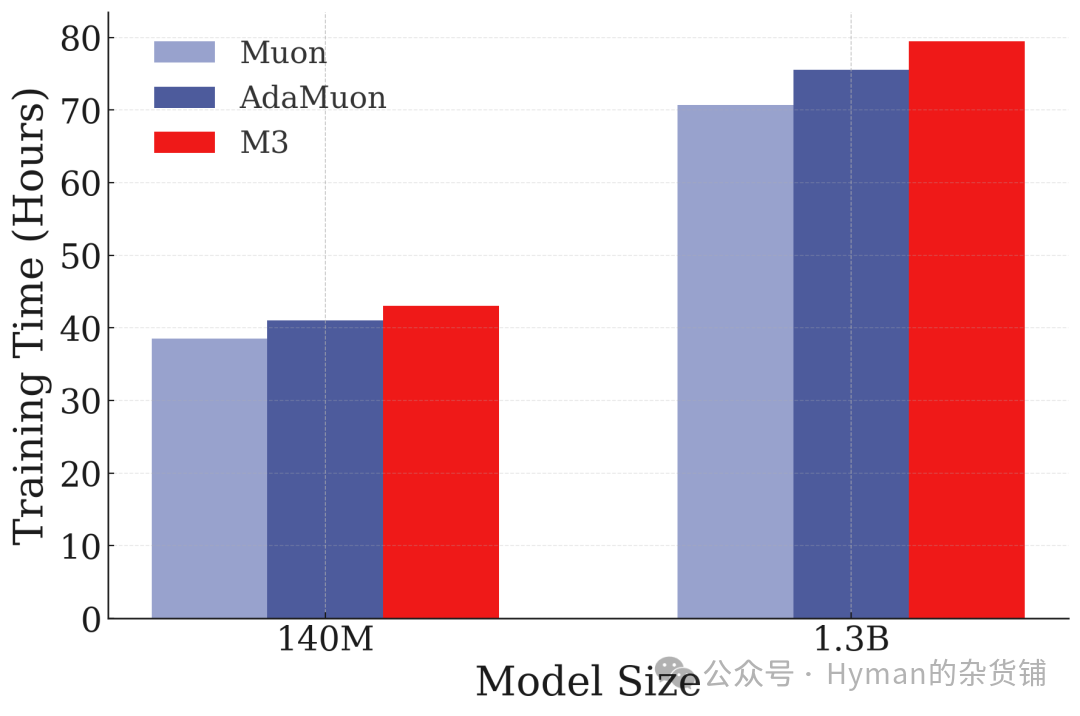
优化器训练时间效率对比: 虽然深度优化器的单步计算略高,但由于收敛速度快,总体训练时间反而更少,且达到了更好的性能。这证明了 Nested Learning 不仅在 NLP 领域有效,在视觉任务上也具有普适性。
与现有方法的深度对比
为了更好理解 HOPE 的突破性,让我们对比几种现有的持续学习方法:
| 方法 | 核心思路 | 优点 | 缺点 | HOPE的改进 |
|---|---|---|---|---|
| 经验回放(Replay) | 保存旧数据重新训练 | 有效防止遗忘 | 需要大量存储;隐私问题 | 无需存储数据,零Replay Buffer |
| 正则化(EWC等) | 限制重要参数变化 | 无需存储数据 | 需要精确估计参数重要性;效果有限 | 通过多频率更新自然保护重要知识 |
| 动态架构 | 为新任务增加模块 | 完全避免遗忘 | 模型持续增大;不可扩展 | 固定架构,通过CMS实现扩展性 |
| Meta-Learning | 学习如何快速学习 | 适应速度快 | 需要特殊训练流程 | 自然涌现的元学习能力 |
HOPE 的独特优势:
- **零成本记忆管理:**不需要额外存储或计算来维护旧知识
- **统一框架:**将架构设计和优化算法统一到同一个范式
- **自然扩展:**通过调整 CMS 层级数量,可以在记忆容量和计算成本间平衡
应用前景:通往AGI的关键一步?
Nested Learning 不只是学术突破,它可能改变AI的应用方式。
场景1:个人AI助手的"长期记忆"
当前问题:你的 AI 助手每次对话都是"失忆"的。今天教它你喜欢什么咖啡,明天又要重新告诉它。
HOPE 的解决方案:
- **高频记忆:**记住本次对话的上下文
- **中频记忆:**记住你最近一周的偏好变化
- **低频记忆:**记住你的核心习惯和价值观
这就像一个真正了解你的私人助理,而不是每天早上都要重新介绍自己。
场景2:工业智能系统的在线学习
制造业案例:
- 问题:生产线的 AI 质检系统,需要定期停机重新训练,成本高昂
- **HOPE 方案:**系统在生产过程中持续学习新的缺陷模式,无需停机
自动驾驶案例:
- 问题:新道路规则、新交通标志需要 OTA 更新,覆盖不全面
- **HOPE 方案:**车辆在行驶中学习新规则,快速适应本地交通环境
场景3:科研助手的知识积累
当前困境:
- 科学家每次使用 AI 工具,都要重新输入背景知识
- AI 无法跟踪研究项目的长期进展
HOPE的潜力:
- 自动积累领域知识
- 记住研究假设的演变历程
- 提供基于长期上下文的科学洞察
商业价值评估
根据行业分析, Nested Learning 的商业部署预计分为三个阶段:
阶段 时间线 应用场景 Phase 12025-2026 研究原型 (HOPE) Phase 22026-2027 产品集成(如 Gemini 辅助功能) Phase 32027+ 大规模部署 (Gemini 4/5旗舰模型)
业界预测,如果 Nested Learning 成功产品化, Google 可能在下一代 Gemini 模型中全面采用,这将是继 Attention 机制 (2017) 之后最重要的架构革新。
理论突破的深远意义
Nested Learning 不仅是工程上的改进,更是机器学习理论的范式转变:
1. 统一视角:
- 传统观点:架构 ≠ 优化算法
- Nested Learning:架构 = 多层嵌套的优化问题
这个统一视角让我们重新理解经典方法:
- **Transformer的注意力机制:**可以看作一层关联记忆的优化
- **Adam优化器:**是一个一阶的嵌套学习系统
- **残差连接(ResNet):**实际上创造了隐式的多层级学习
2. 设计新维度:
- 以前只能调整层数、宽度、激活函数
- 现在可以设计:更新频率、嵌套深度、上下文流
3. 计算深度的新定义:
- 传统深度:模型有多少层
- NL 深度:优化问题嵌套了多少层
这意味着一个"浅"的物理网络可以有"深"的计算深度——只要它的优化过程嵌套够深。
🤔 挑战与思考:完美了吗?
尽管 HOPE 令人兴奋,但仍有几个关键问题需要解决:
1. 计算成本
多层级优化增加了计算复杂度:
- 训练成本: HOPE 需要维护多个频率的参数更新,计算量比 Transformer 高30-50%
- **推理成本:**自修改机制需要额外计算,可能影响实时性
未来方向:
- 模型量化和剪枝
- 更高效的硬件加速(如 Google TPU v6 )
2. 记忆容量的上限
即使是连续记忆系统,也有存储上限:
- 低频记忆层最终会饱和
- 如何决定哪些知识"值得永久保留"?
可能的解决方案:
- 引入记忆重要性评分机制
- 周期性记忆压缩和归档
3. 安全性和可控性
自修改系统带来新的风险:
- 模型可能学习到有害模式并长期保留
- 如何确保持续学习不偏离预期行为?
必要措施:
- 安全护栏:限制低频层的更新范围
- 记忆审计:定期检查模型学到了什么
4. 可解释性
多层嵌套优化让模型更难理解:
- 为什么模型做出某个决策?
- 这个决策来自哪一层的记忆?
这是一个开放的研究问题,需要新的可解释性工具。
💬 社区反响:技术圈怎么看?
Nested Learning 和 HOPE 架构在 Twitter 和 Reddit 等技术社区引发了热烈讨论。
主要观点汇总
积极反馈:
- 多位AI研究者认为这是" LLM 遗忘时代终结"的关键突破,将持续学习从理论变为现实
- 社区普遍认同这是继 Attention 机制后最重要的架构创新
- 开发者对 HOPE 仅用 1.3B 参数就能击败更大模型印象深刻,证明了"架构优于规模"
- 企业技术团队看到了构建真正适应性 AI 系统的可能性
实践挑战:
- 99% 的开发者仍在使用 Transformer 生态系统,迁移成本巨大
- 现有工具链(PyTorch、TensorFlow)针对 Transformer 优化,需要重新构建基础设施
- 计算开销和工程实践之间的平衡尚未得到验证
核心分歧:
- 产品化时间线:乐观派认为 2026-2027 年可见商用,保守派认为需要3-5年
- 与 Transformer 关系:替代派 vs 共存派
- 应用场景:通用架构 vs 特定领域(如持续学习场景)
最热议的三个问题
- 技术迁移路径:如何从 Transformer 平滑过渡到 Nested Learning ?社区讨论了混合架构、渐进式替换、工具抽象等方案
- 多模态扩展: HOPE 能否在视觉-语言大模型中发挥作用?论文验证了视觉任务,但完整多模态融合仍需探索
- 自修改安全性:模型可以修改自己的学习算法,如何确保不会学习到有害模式?这需要全新的 AI 安全框架
- 全球 AI 社区(包括中日研究者)普遍对这一技术持谨慎乐观态度,既看到了理论突破的价值,也清醒认识到工程落地的挑战。
🌟 总结:AI进化的新纪元
Nested Learning 代表了深度学习范式的根本性转变:
从"静态训练"到"动态进化":
- 传统模型:预训练 → 部署 → 固化
- Nested Learning:持续学习 → 自我改进 → 终身适应
从"遗忘陷阱"到"知识积累":
- 传统方法需要 Replay Buffer、正则化等"补丁"
- Nested Learning 从架构层面原生支持持续学习
从"工具"到"伙伴":
- AI 不再是一次性使用的工具
- 而是能够与用户共同成长的智能伙伴
Google 的 HOPE 只是概念验证,但它打开了一扇通往真正"永不遗忘的 AI "的大门。当 Nested Learning 与其他技术(如多模态学习、强化学习)结合,我们可能正在接近**人工通用智能(AGI)**的关键拐点。
正如 Google 研究团队所说:
"Nested Learning 提供了一个原则性的框架,将架构和优化统一为一个连贯的系统。这为设计更具表达力、更高效的学习算法开辟了新维度。"
AI 的"失忆症"时代,可能真的要结束了。
论文的核心贡献总结
Google Research 在这篇 NeurIPS 2025 论文中做出了以下关键贡献:
理论层面:
-
**Nested Learning 范式:**首次将 ML 模型表示为嵌套优化问题的集合
-
**架构-优化统一理论:**证明架构设计本质上是选择优化问题的嵌套方式
-
**上下文流概念:**每个优化层级有自己的信息流和学习目标
方法层面:
-
**深度优化器:**多层嵌套的记忆系统,用 L2 回归替代点积相似度
-
**连续记忆系统(CMS):**从二元的"短期/长期"到连续频谱的记忆
-
**自修改循环:**模型可以在推理时修改自己的学习算法
实证层面:
-
**HOPE架构:**首个完整实现 Nested Learning 的模型
-
**持续学习突破:**显著减少灾难性遗忘,无需 Replay Buffer
-
**长上下文优势:**在10万 token 的"大海捞针"测试中表现优异
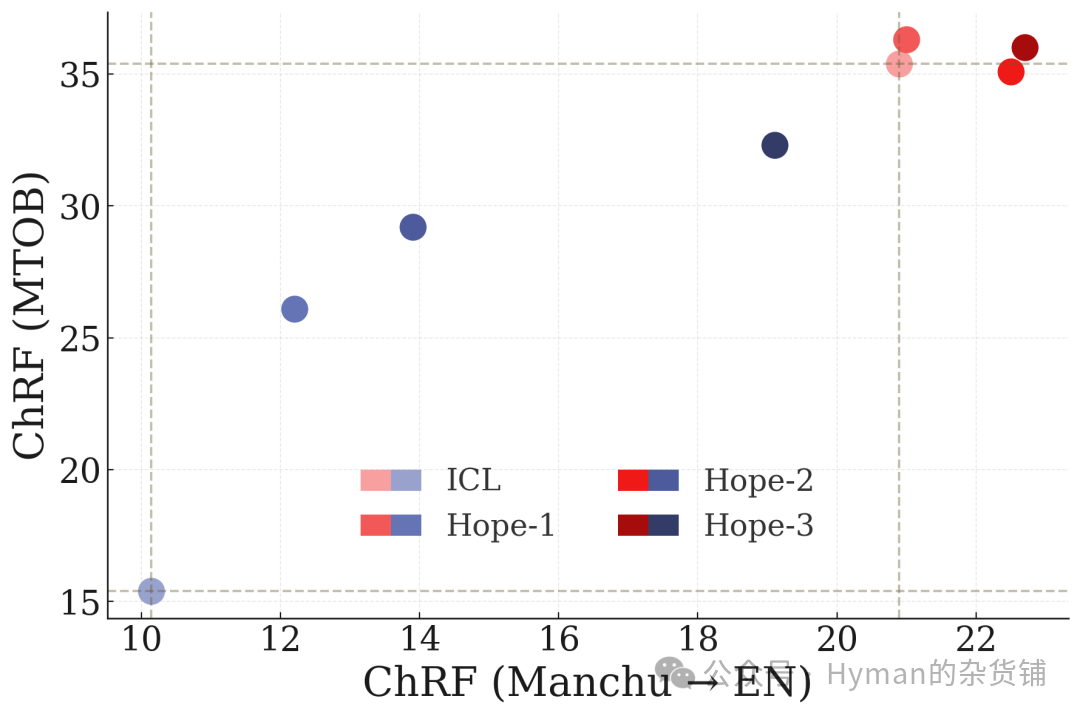
上下文学习翻译任务
RULER 基准上的上下文学习翻译任务: 展示 HOPE 在需要理解长上下文并进行复杂推理的翻译任务中的表现,验证了无界上下文学习能力。
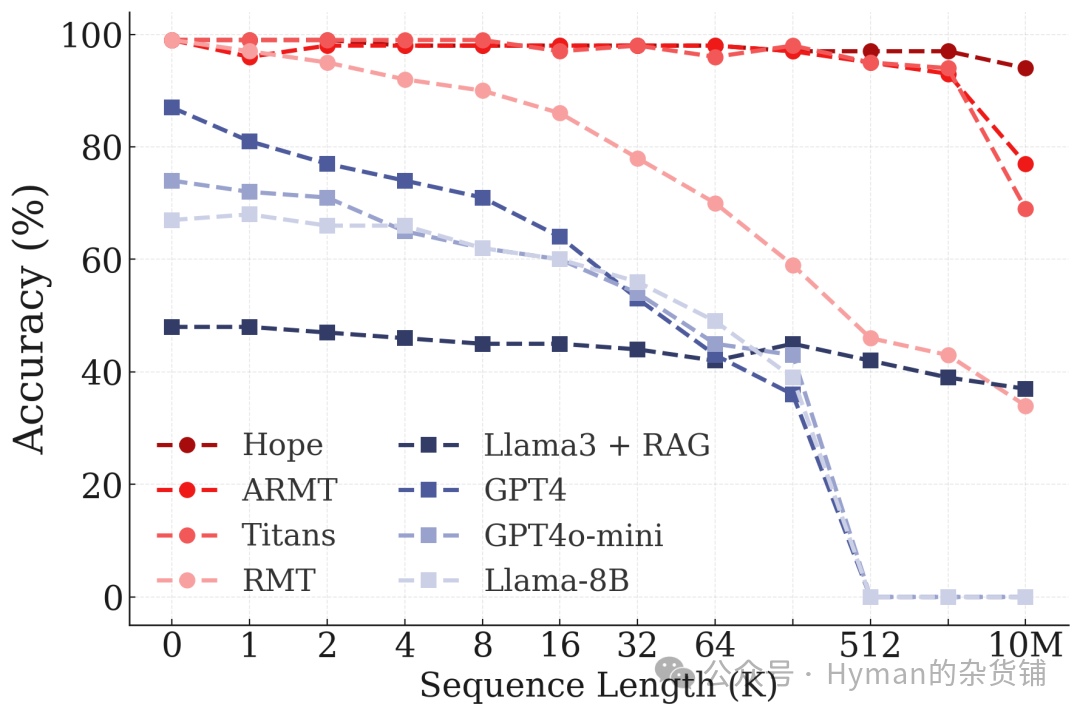
BABILong推理任务
BABILong 长序列推理: 在需要多步推理的长序列任务中,HOPE 能够保持对早期信息的记忆,并将其与后续信息结合进行推理,展示了真正的"终身学习"能力。
这些实验结果共同验证了论文的三层核心贡献:
- **理论层面:**Nested Learning 统一了架构与优化的视角
- 方法层面: 深度优化器、CMS 和自修改循环的创新设计
- 实证层面: 在语言建模、长上下文理解、持续学习等多个任务上的突破性表现
📚 更多资源
- 原始论文: https://arxiv.org/abs/2512.24695
- Google官方博客: https://research.google/blog/introducing-nested-learning-a-new-ml-paradigm-for-continual-learning/
- 社区讨论: https://www.reddit.com/r/singularity/comments/1or265r/google_introducing_nested_learning_a_new_ml/
- 问题反馈: https://github.com/kmccleary3301/nested_learning/issues





