云启年货集|年度硬核报告:AI+开源+商业化=?

连续三年,看开源+AI的新趋势
2023年,AI领域迎来了预训练大模型技术的大爆发,开源生态在其中起到极大的推动作用,众多开源模型、AI开源项目开始积极寻求商业化,但因特殊的产品属性,其商业模式与传统的开源软件有诸多差异。
本篇**「云启研选」**摘自《2023中国开源年度报告·商业化篇》,希望能通过分析差异背后的原因,来梳理清新生态下可能的新路径。在即将迎来农历春节的最后一周,分享给您一份「硬核」年货(文末有彩蛋🎉)。
这是我们与开源社持续合作、共同出品《中国开源年度报告》并撰写「商业化篇」的第三年。过去两年,报告在内地、台湾、新加坡等地,广泛地获得了开源从业者的关注。
作为领域内最早关注并持续耕耘开源的机构,我们长期深入追踪AI与开源的进展,曾在早期成功发掘并投资了 PingCAP、Zilliz、Jina AI、RisingWave Lab、TabbyML 等开源企业,持续参与共建开源生态。
2023年,在继续出品「中国开源年会· 商业化论坛」外,我们还联合开源社举办了系列闭门讨论 Meetup,和微软、谷歌、Apple、Meta、华为、百度等国内外大厂,斯坦福大学、上海交通大学、中科大、UCSD 等高校研究机构,以及国内外大量第一线的创业者们,深入探讨开源生态的发展方向,交流中的精华内容也被收录进本篇报告,感谢各位创业者与行业专家们的不吝分享。
本篇报告重点探讨的内容包括:
➤ 开源生态正如何与AI互助共生、快速发展?
➤ 开源目前正在面临哪些安全挑战?
➤ 开源项目在全球/国内的融资情况分别如何?
**以下是我们精编的报告中部分内容,为保证研究思路的完整展现,全部章节目录都会在正文放出,完整版请在后台回复「开源2023」获得。**关于相对前沿、仍在变化快速中的主题,我们在报告中做了较多的开放式探讨,也欢迎各位开源创业者随时与我们交流。
一、开源生态助力AI快速发展
1. 预训练大模型迅速发展
开源功不可没
预训练大模型的发展已成为人工智能领域的一个重要标志,开源生态的力量在其中发挥了重要作用。同时,开源基座大模型的性能快速发展,逐渐比肩闭源。
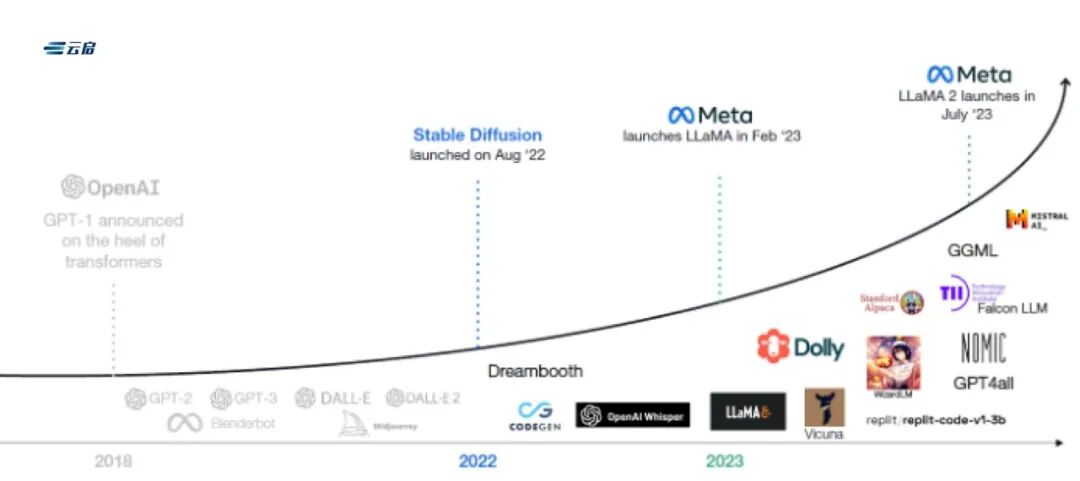
不断涌现的开源大模型
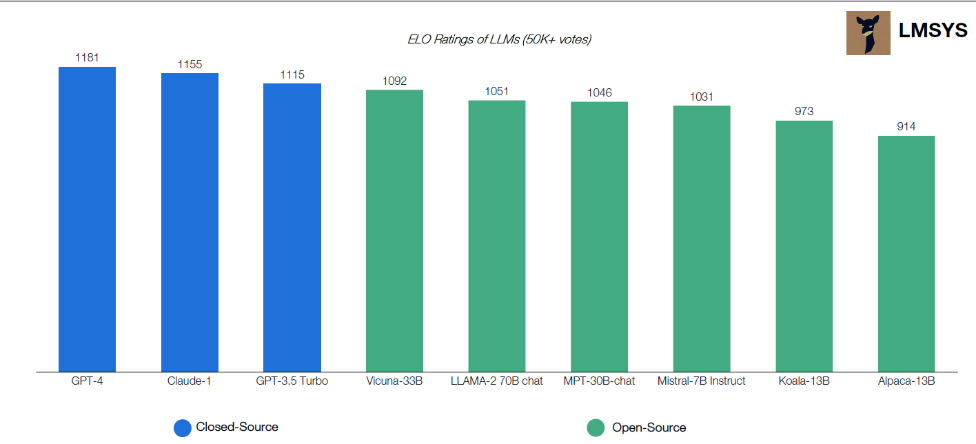
ELO基于用户反馈对于大模型的评级,4-9位均为开源大模型 图源LMSYS,云启整理
得益于开源模型的开源特性,使用者可以更方便地对大模型进行微调以适应不同的垂直应用场景。经过微调的大模型更加具有行业特性,相比于通用大模型也更加适合特定行业的应用,这是闭源模型所不具有的优点。
2. 开源是助推基座模型发展的第二动力
1. 供给侧:集中力量,促进研发
➤ 节省开发人员数量,集中研发能力
根据工信部发布的相关数据,人工智能不同技术方向岗位的人才供需比均低于0.4。
➤ 节省算力,避免重复造轮子

➤ 探索更广泛的技术可能性
Transformer模型是否为最优解,目前没有答案;下一个更好的方向是否是RNN也依然存在疑问。但正是开源的生态,使得开发者可以在这棵AI大树的不同枝干上进行尝试,保证了技术发展的多样性,不拘泥于局部最优解,真正推动AI技术的向各个方向不断发展的可能性。
2. 需求侧:降低门槛,抢占市场
➤ 开源模型显著降低模型使用者的成本
调用OpenAI API和AWS云上部署开源模型的成本对比,云启整理
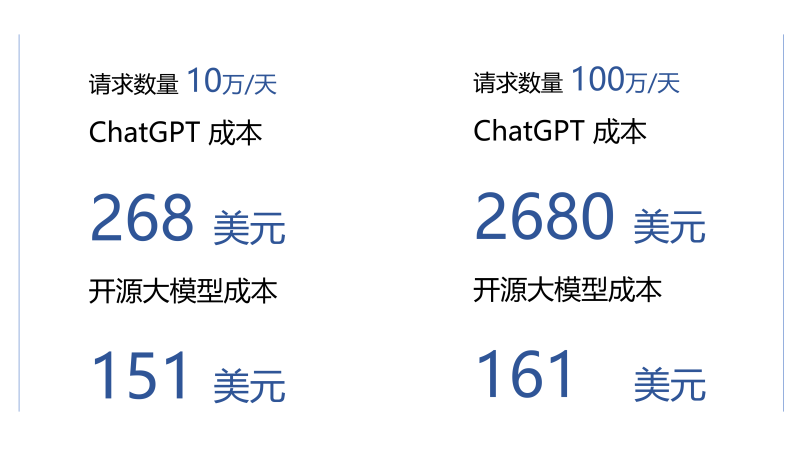
以直接调用OpenAI的API和公有云上部署Flan UL2模型对比为例:
根据OpenAI官网最新数据,使用ChatGPT4模型,输入为0.03美元/1000tokens,输出为0.06美元/1000tokens,考虑输入与输出的关系,假定平均成本为0.04美元/1000tokens。每个token约为一个英文单词的 3/4,一条请求内的token数量等于提示词+所生成的输出token的。假设一个文本块为500个单词,即约670个token,那么一个文本块的成本为670×0.004/1000=0.00268美元。
而如果基于AWS云端部署开源模型,以AWS发布的相关教程中提到的200亿参数的Flan UL2模型为例,其成本共分为三个部分:
1)使用AWS SageMaker将模型部署为端点的固定成本,每小时约5-6美元,一天约150美元
2)将SageMaker端点接入 AWS Lambda:假定5s内向用户返回响应,使用128MB内存,每条请求的价格为:5000×0.0000000021(128MB每毫秒单价)=0.00001美元
3)通过 API Gateway将此Lambda函数开放为API:Gateway的价格约为1美元/100万条请求,即0.000001美元/每条请求。
基于以上数据,可以计算出:
➤ 开源提高模型的可解释性和透明度,降低技术采纳的门槛
➤ 企业用户可以通过开源基座模型实现特定需求
企业在调用闭源大模型时,闭源模型始终部署在诸如OpenAI等公司服务器上。开源大模型本地部署的能力极大地保护了企业的隐私。
➤ 开源模型有利于客户的长久体验
在开源社区研发力量的加持下,开源模型的更新速度很快。LLaMA2本身欠缺中文语料,导致在中文理解方面令人不甚满意;但是仅在LLaMA2开源次日,社区就出现了首个能下载、能运行的开源中文LLaMA2模型"Chinese LLaMA27B"。
➤ 开源有助于抢占市场先机
开源模型由于进入门槛低的特点,用户更易接触,可以迅速拓展市场。Stable Diffusion,一款开源的图像生成模型,凭借其庞大的开发者社区和多元化的应用场景,已成为闭源文生图模型MidJourney的重要竞争对手。
3. 生态侧:汇聚多元,长久增长
➤ 开源有利于大模型公司迅速抢占生态资源

Github上的关键词项目数量
➤ 开源有利于大模型厂商撬动市场,获取商业同盟
LLaMA2商用开源后,Meta迅速与微软、高通达成合作。Meta表示微软Azure云服务的用户,在云上就可以直接微调部署Llama 2,微软表示,Llama 2已经针对Windows进行优化,直接可以在Windows本地运行。二者的结合充分彰显了开源大模型与云厂商具有天然的合作基础。
Meta与高通的合作也预示着其在手机领域的扩展。开源大模型由于其受众面广,可以本地部署等优势,手机成为未来便捷使用大模型的重要载体。这也吸引着手机芯片厂商与开源模型厂商进行合作。
➤ 开源可以调集广大的社区力量,汇聚多元的开发力量
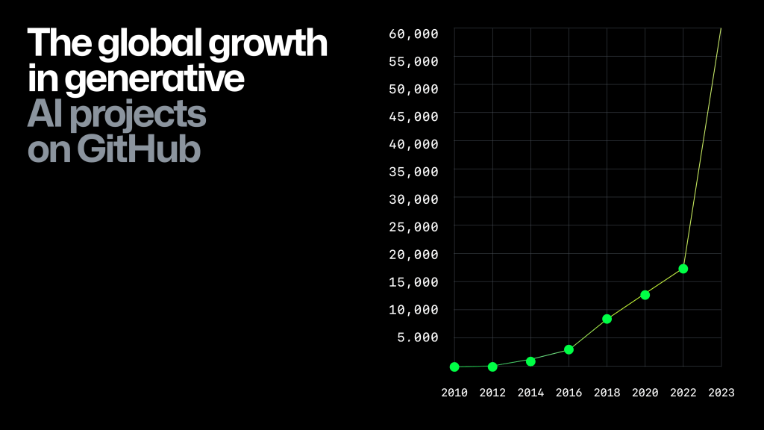
开源社区Github上生成式AI相关项目的数量变化(信息源:Github,云启整理)
开源大模型会收到来自不同地区、不同文化、不同技术背景开发者的贡献。他们的加入将使得开源大模型更能适应于不同地区的风土人情:例如对应语言的微调、对应产业的微调、不同使用习惯的微调,从而提高了开源大模型的受众面。
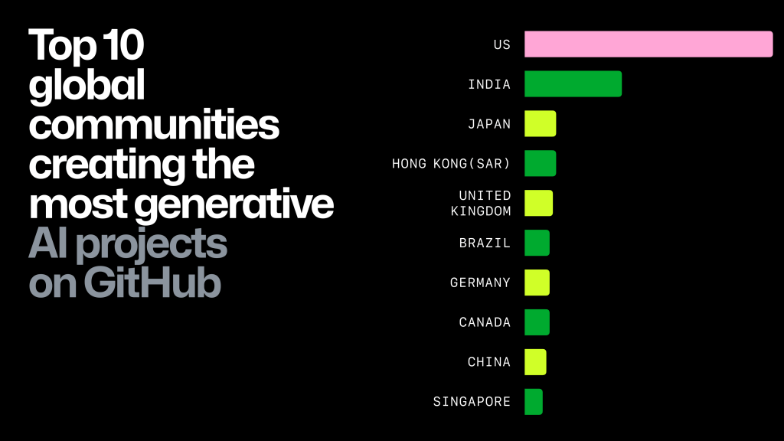
生成式AI贡献者的地域分布TOP10(信息源:Github,云启整理)
4. 开源大模型的商业化实现路径
本段落基于与从业者的交流、案例调研,尝试归纳出现阶段的一些商业化探索方向:
➤ 提供支持服务
➤ 提供云托管服务
➤ 基于基座模型开发商业应用
➤"模型即服务"的商业模式
➤ 大模型商业模式需要勇于探索与尝试
大量公司都在积极探索不同的商业模式,而不拘泥于单一的定价策略。到目前为止,我们还未看到一种能有效覆盖高昂训练成本的商业模式。开源大模型的兴起和发展标志着一个新的业态的诞生,各个参与者(包括研究机构、企业、开发者和用户)都在积极探索,试图找到能够平衡技术创新与经济回报的模式。这个业态具有其独特的价值和潜力,为各种行业提供了前所未有的技术支持和创新可能性。
2. AI 开发者工具开源
已成为行业阶段性共识
1. 开发者工具在AI产业链中发挥着重要作用
开发工具(Develop Tools)层,是AI大模型开发链条中重要的一环。如下图所示,开发工具层起到承上启下、链接中层的作用:
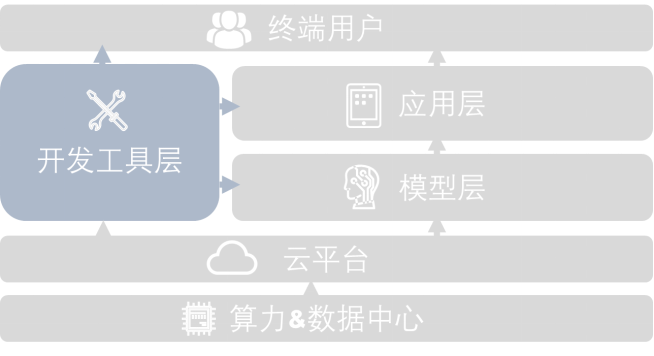
开发者工具在AI大模型产业链中的位置
越来越多的AI大模型开发者

大量开发工具覆盖大模型开发的不同层面
开发者工具开源有重要意义
供给侧效益
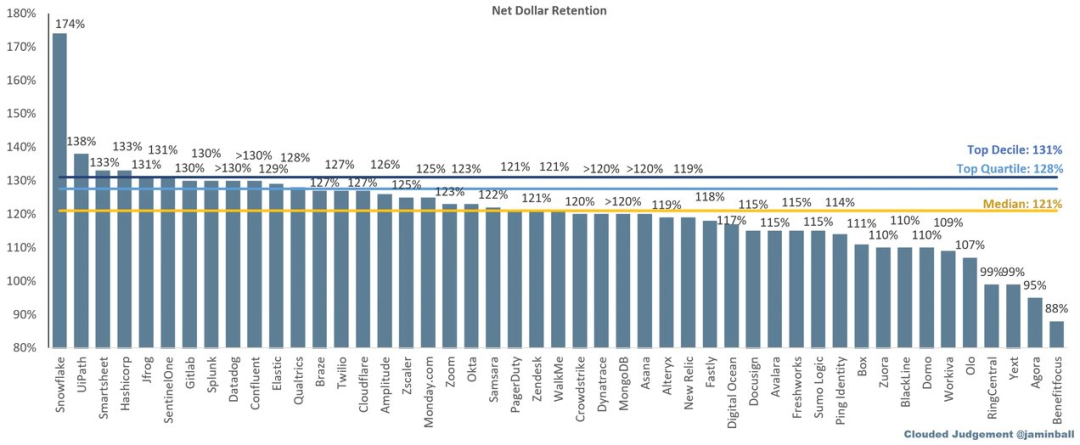
开源开发工具用户粘性高,图源Clouded Judgement,云启整理
图为各大SaaS产品净收入留存率。开发者产品粘性普遍高于中位数,Snowflake174%位居榜首,Hashicorp、Gitlab、Confluent等也超过120%。在高粘性的背景下,越快的获客速率代表着未来更高的收入。开源降低了尝试和采纳新工具的门槛,对于建立品牌知名度和用户基础至关重要。
需求侧效益
由于开源开发工具的生态效应,技术迭代速度通常超过了闭源工具。实验室的最新研究成果能迅速被集成和共享,保证了技术的快速更新和传播。
开发者工具开源需重视生态搭建
做好开发者工具开源,需要维持社区生态稳定的技术支持
开源开发者工具需要与云厂商优势互补,扩大市场覆盖和用户基础
以MongoDB为例,MongoDB很早便进行云转型,推出了SaaS服务Atlas,尽管在2017年MongoDB上市时Atlas的收入只占总收入的1%,MongoDB依然花费大量资源打造SaaS相关产品和营销体系,而在之后Atlas的收入便以超过40%的年复合增长率飞快增长。
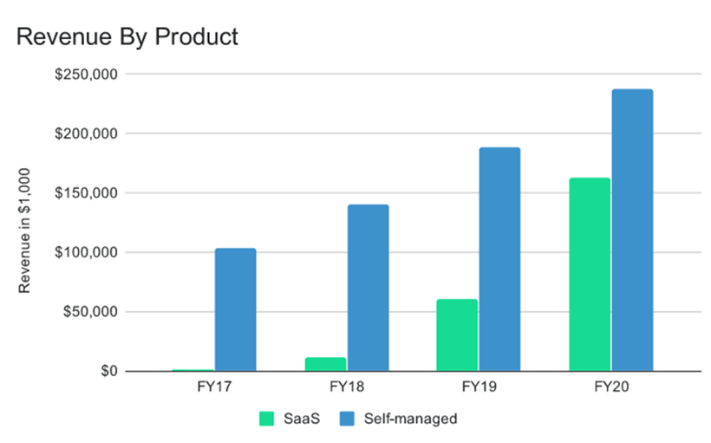
MongoDB 各产品销售收入
建立生态有利于构建开源行业标准
MongoDB借助社区力量形成了 NoSQL RDMS 的行业标准。这个活跃的社区不仅为MongoDB早期的商业版带来了高质低价的许可证,也成为日后Atlas (managed service)的基础。Milvus基于开源社区协作,推出了Vector DB Bench(可以通过测量关键指标来衡量向量数据库的性能,使得向量数据库发挥出最大的潜能),从而逐渐建立起向量数据库的行业标准,方便用户针对性地选择适合需求的向量数据库。
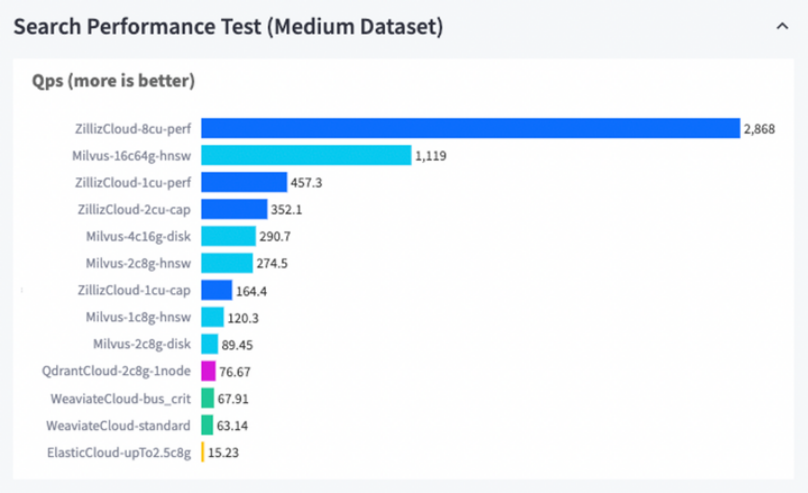
向量数据库评价结果
开源开发者工具商业化路径探索
AI开发者工具,与传统软件开发者工具在商业化维度上有可借鉴性,整体商业化还处于早期探索阶段,基于对目前已经尝试商业化的开发者工具开源项目的研究分析,发现目前有以下几种商业路径:
云上托管服务(Cloud Hosting Managed Service)- 按量计费
云上托管服务(Cloud Hosting Managed Service)- 分级订阅计费
私有云/专有云/定制化部署
开发者工具侧开源的成功案例
Zilliz是研发面向人工智能的新一代数据处理和分析平台,其主要是为应用型企业提供底层技术,已被全球1,000多个企业使用。

Zilliz 全球用户
Zilliz的主要产品是向量数据库,是开发者工具中的关键一环,这种专门用于存储、索引和查询嵌入向量的数据库系统,可以让大模型更高效率的存储和读取知识库,并且以更低的成本进行模型微调,还将进一步在AI Native应用的演进中扮演重要作用。Zilliz的商业化产品为Zilliz Cloud,采用月度订阅模式,采用SaaS的部署方式,基于向量数量、向量维度、计算单元(CU)类型、数据平均长度确定每月的订阅费用。Zilliz同时也提供基于PaaS的专有部署服务,适用于高度注重数据隐私和合规的场景,这一部分为定制化计价。
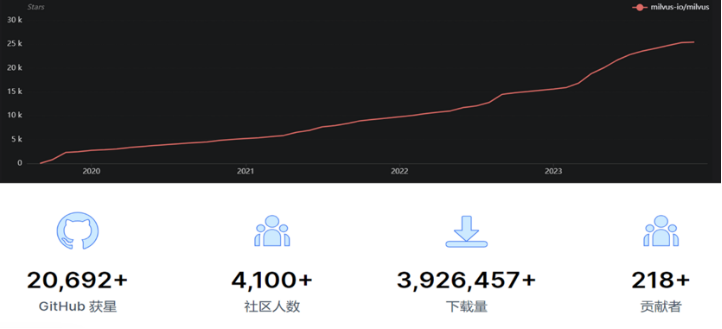
Zilliz Github 社区运营情况
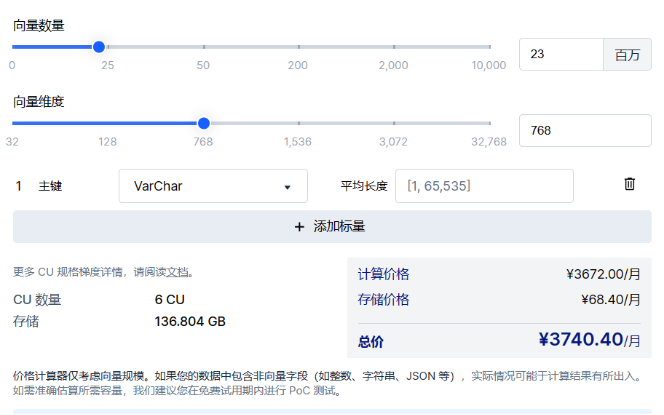
Zilliz 价格计算器示例
AI应用层开源工具百花齐放
应用层开源工具百花齐放

百花齐放的AI应用层产品(信息源:Sequoia)
应用测开源工具图谱(仅以各领域部分产品举例)
大模型应用层开源的市场现状
互联网巨头与初创企业共同发力
B、C端的竞争格局不同
1)B端市场:面向企业的应用通常专注于提高效率、降低成本和增强决策能力。2)C端市场:面向消费者的应用则更注重用户体验、交互性和易用性。
大量子场景尚属于蓝海市场,未出现明显头部
基于大模型新的能力,期待创新性的应用出现
大模型开源商业化面临的挑战
技术高速发展,开源项目需要持续迭代以保持竞争力
抄袭/借鉴范围难以界定
社区参与者难以对模型迭代提供直接贡献
开源技术发展快,后期更新成本高
开源安全挑战
安全问题是决定一款开源产品能否顺利商业化的重要因素。根据Synopsys数据,截至2022年末,84%的代码库包含至少一个已知的开源漏洞,48%包含高风险漏洞,34%的受访者还表示,他们在过去12个月内经历过"利用开源软件已知漏洞发起的攻击。只有做好安全保障,开源软件才能在商业化的道路上走得更远。
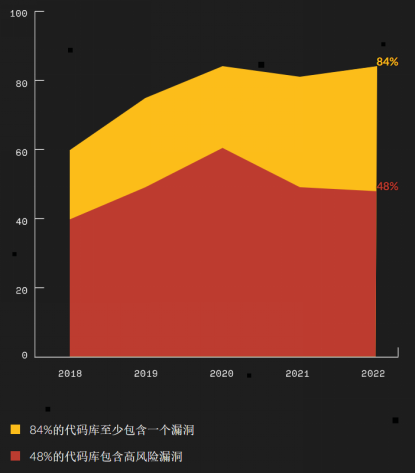
开源代码库漏洞(数据源:Synopsys)
开源软件网络安全
开源软件网络安全问题相对普遍
开源软件本身安全漏洞较多
根据"2022年奇安信开源项目检测计划"结果显示,连续三年缺陷密度和高位缺陷密度数量不断增长,且有加速的趋势。开源软件自身安全问题相当严峻。
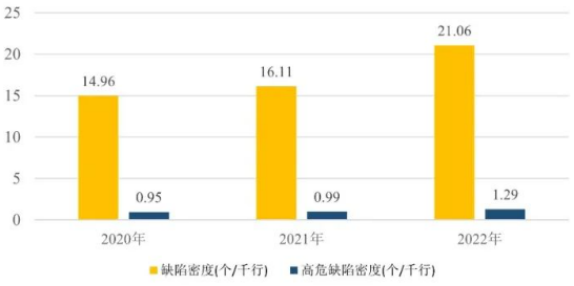
开源软件平均缺陷密度三年对比(数据来源:2023中国软件供应链安全分析报告)
活跃度过低/过高的开源项目更易存在安全风险
部分用户使用过于老旧的软件,使用版本混乱
开源软件漏洞风险的应对策略
定期的安全审计和代码检查
使用SCA(软件成分分析)工具
增强教育和培训
开源许可证的可控
开源许可证是一种针对开源资源使用者的约束,类别丰富
开源许可证是一种针对开源资源(包括但不限于软件、代码、网页使用者)的约束。
开源许可证根据授权的限制程度整体分为三类:Permissive、Weak Copyleft、Strong Copyleft
开源许可证分类
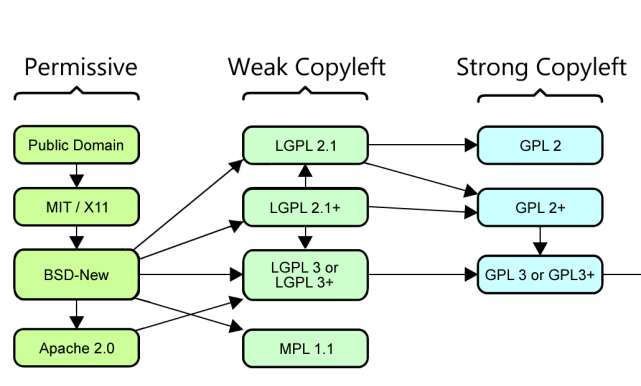
在这些大类之下,具体的许可证和许可证族都会有独特的限制、权限,附加参数也会有具体差异,许可证整体的逻辑关系整理如下:
许可证逻辑关系,图源Github
开源社还提供了开源许可证选择器,为更快更好的了解最佳的许可证选择提供了很好的帮助,强烈推荐给有需求的同学:https://kaiyuanshe.cn/tool/license-filter
2
使用开源资源不遵守许可证会产生侵权风险
- 开源许可证侵权
- 许可证互惠性要求导致开源版权问题范围扩大
- 开源许可证侵权可能会导致严重后果
3
开源大模型许可证很大程度上区别于传统许可证
由于开源大模型还在发展和迭代,本年度两个影响力极大的开源大模型:LLaMA2和Falcon,都因为开源许可证条款的调整而被人质疑是否是真正的"开源"。二者均未使用市面上通用的许可证协议,而是分别自拟协议"LLAMA 2 COMMUNITY LICENSE AGREEMENT"以及"TII Falcon LLM License";同时二者都对其商业用途进行了额外约束。
- 开源大模型的开源目的与传统软件开源不同
以LLaMA2为例,其许可证本质上是一个指导框架,它主要面向那些打算在遵循Meta既定规范和标准的前提下,开发和部署AI系统的企业。此框架的目的是确保这些企业在开发和部署AI技术时,能够符合Meta设定的特定规则和标准。这样的做法有助于Meta管理其AI技术的应用范围和方式,进而维护其商业利益和品牌形象。
对于那些计划在Meta平台上进行AI开发的企业而言,LLaMa2许可证可能构成了一项必须遵守的合规要求。这意味着这些企业在使用Meta提供的工具和资源来开发和部署AI模型时,必须遵循Meta的特定规范和要求。在此过程中,这些企业可能需要向Meta申请相应的授权,而LLaMa2许可证便是这种授权的一环。
4
保障许可证可控的方式
- 记录开源组件的使用情况
- 谨慎使用辅助编码工具
- 并购过程中进行充分的代码审计
3. 开源AI安全
随着大模型的火热,在上文提到的大模型许可证问题外, 更多的AI安全可控问题也逐步进入人们的视野。由于技术较新,没有明确的定义和规范,因此本段基于案头研究列举了当下相关从业人员较为关心的话题,希望引发读者思考,欢迎探讨与反馈。
1
开源AI对数据安全提出新的要求
数据集的质量、数据集是否包含恶意数据等问题对于AI大模型尤其是开源大模型尤为重要,因为开源大模型的数据集很多都是企业内部提供数据,清洗、监控、合规等无法做得像专业闭源大模型厂商那样专业。
- 训练数据集处理不恰当会引发一系列偏差
- 选择开源底座大模型时应将训练数据源纳入考量范围
2
开源AI大模型的大量使用引发对于社会伦理的思考
- 大模型幻觉问题可能导致严重后果
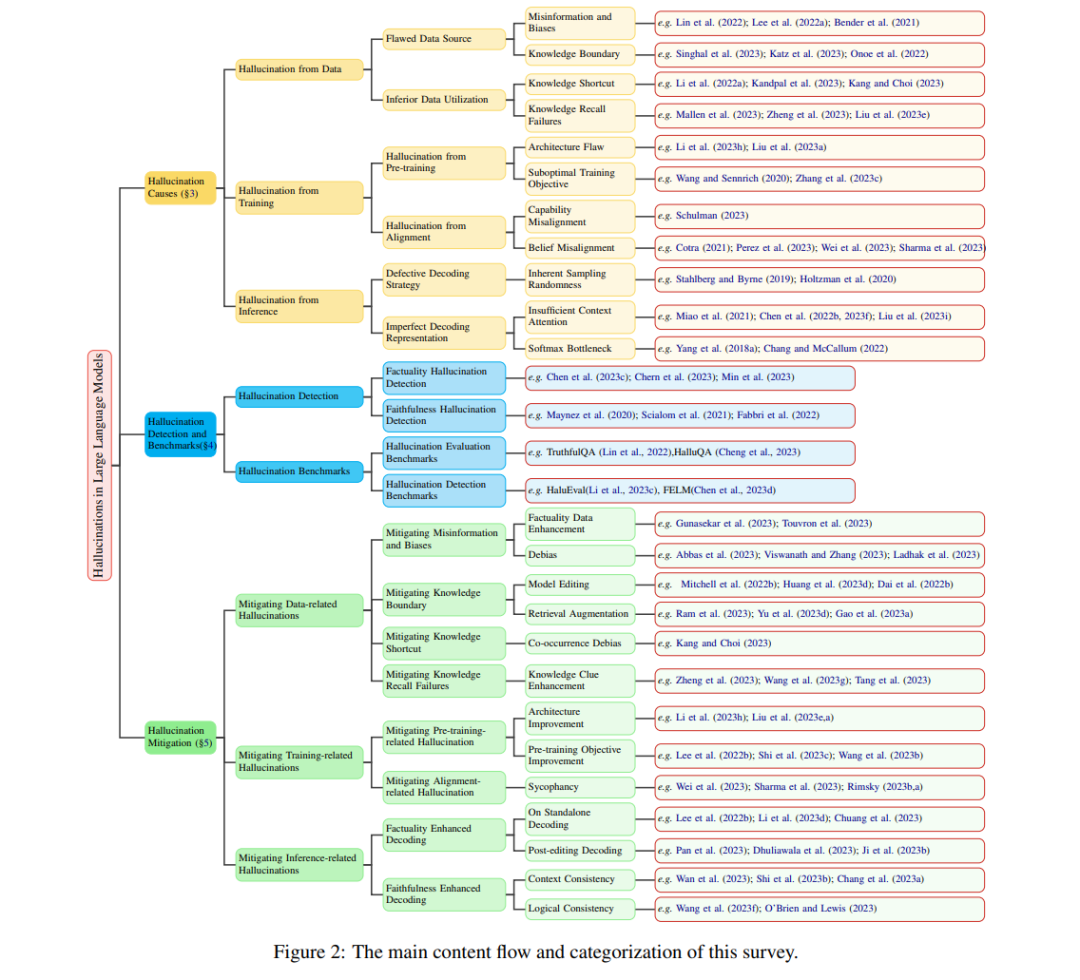
哈尔滨工业大学对于幻觉的分类
-
大模型的输出可能会输出违反道德法律的内容 1)如何加强大模型的信息过滤机制——技术层面 2)如何界定大模型输出内容是否侵权、违法——法律层面
-
大模型可能会加剧社会割裂 1)加强公众的教育,大模型并非万能,需审慎看待——社会宣传层面 2)如何保证大模型训练数据集的质量,降低其偏见性——技术层面
三、开源项目资本市场情况
1. 全球市场状况
1
2023全球VC投资规模减小,但AIGC是万众焦点
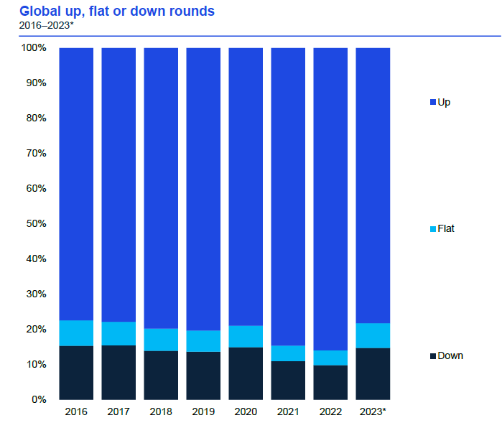
全球风险投资溢价、平价、跌价投资比例(数据源:KPMG)
然而,在大环境整体不乐观的背景下,AIGC相关融资却成为全球焦点,相关融资规模大幅增长。在北美,2023年的独角兽企业中AI相关公司最多,包括AI Agent初创公司Imbue、AI+生物技术公司TrueBinding、生成式AI公司Runway以及自然语言处理公司Cohere;在欧洲,尽管整体融资放缓,但是AI公司表现则格外突出,大量初创公司获得资金,例如法国AI平台公司Poolside;亚洲投资人对于AI的兴趣也不断攀升,但相关国家监管机构对生成式AI的监管力度也在不断加大。
预计伴随着AI技术的快速迭代,大模型、AI Agent等概念的不断火热,AI领域相关投融资会较小受到全球风投规模收缩的影响。
2
全球开源融资情况
近年来,商业开源公司的发展速度令人瞩目,这些公司的总市值从100亿美元迅速增长,突破了5000亿美元的大关。这一显著增长不仅展示了开源技术在商业领域的巨大潜力,也反映了投资者对于开源模式的高度认可和信任。根据OSS Capital的预测,商业开源公司的市值有望在未来达到惊人的3万亿美元。
在过去四年里,开源商业领域的发展表现出了稳健的增长。这一时期内,超过400家初创公司进行了大约700轮次的融资,总额达到了290亿美元。具体来看,年度融资规模从2020年的2.7亿美元增加到了2023年的125亿美元,年复合增长率为255%。
即使在2023年融资规模最低的月份,月融资额3.86亿美元也超过了2021年最高月融资额,甚至超过了2020年全年的融资总额(2.72亿美元)。这一趋势反映出资本市场对开源商业的持续关注和认可。
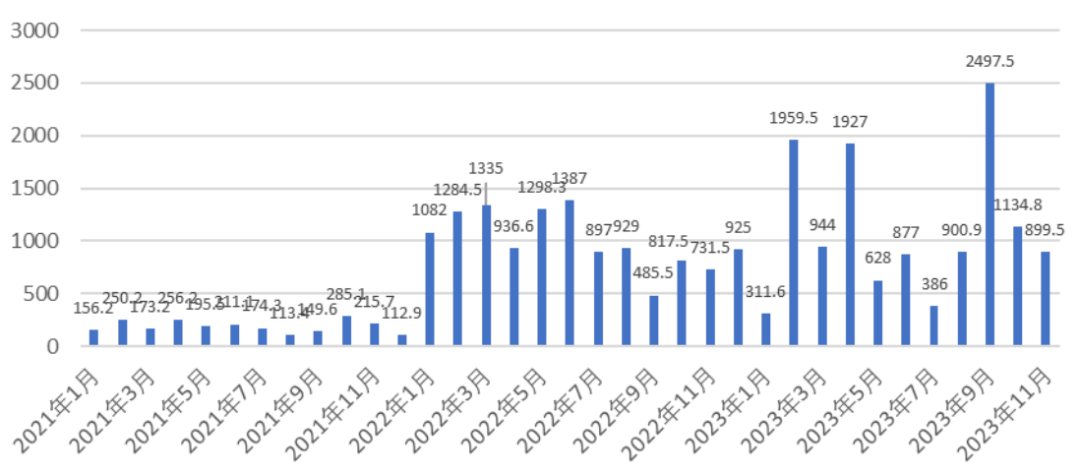
全球VC基金投资到商业化开源软件公司的资金量(数据源:OSS Capital)
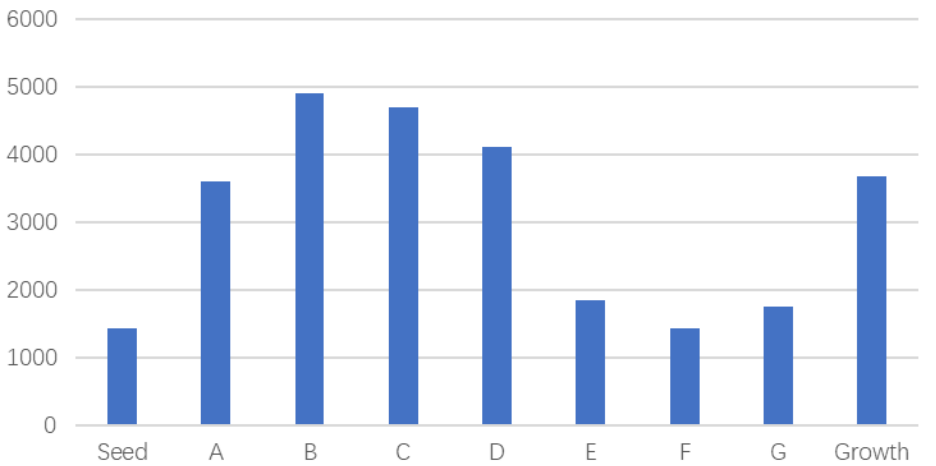
商业化开源软件公司融资轮次分布(百万美元)(数据源:OSS Capital)
商业化开源软件公司累计融资规模分布(数据源:OSS Capital)
云启年货集
关于AI+开源,您看到了哪些正在发生的新趋势? 我们将从评论区互动出选出两位,寄送《2023年度开源报告·商业化篇》实体报告!