2026年了,我们还在用爱迪生试灯丝的方式评估World Model

一场关于World Model的严肃讨论。
上个月,五源信号站5Hz 第一期活动还在讨论Sora的"死亡"意味着什么。而在今天,多模态几乎从AI热点方向的语境中消失,World model成为最受关注的下一个战场:不仅是学术界在密集发论文,工业界也在真机上做验证,投资人则在追问:这条赛道到底有没有Scaling Law?
World Model的三种"未来"——生成派、JEPA 派、空间智能派,押的不是同一个 AGI。它们的终局,可能是一场关于压缩比的效率竞争。
在五源信号站5Hz第二期活动中,我们邀请了来自具身智能、自动驾驶、视觉表征、Agent、AI Infra 等多个方向的研究者和创业者,围绕 World model 的界定、技术路线、benchmark和落地场景,进行了一场深度讨论,今天这篇文章,是我们对这场讨论的提炼整理。欢迎报名我们的下一场讨论,分享你的前沿观点。
五源信号站 | 5Hz 由五源资本发起的小规模闭门研讨,聚焦技术与商业的实战应用。——"在共识形成之前,看见它。"
Highlights:
- World Model不是Video generation,核心区别在action条件下的状态预测与多步因果推理能力;
- 三条技术路线各有所长、也各有未解之题(生成派缺逻辑、JEPA 派缺落地、空间智能派缺时间),它们未必在同一赛道竞争,而是押注不同的 AGI 路径;
- "JEPA是所有人都认为正确,但没有一个人能做出来的一场幻梦";
- 世界模型本质上是一场效率竞争:谁的压缩比更高,谁就能占据优势位置;
- 评估world model比评估LLM难一个数量级,游戏化的难度梯度可能是破局思路;
- 具身进展由数据驱动而非模型驱动,Ego-View可能是通往泛化的关键一步。
讨论嘉宾 | 5Y社群、ResearchAI+社群
整理 | 刘一鸣
Insight 01
如何严肃界定World Model
1. World model 这个词在具身领域存在大量混用。一种比较严格的区分方式是看它是不是真的 action-conditioned(动作条件化):如果只是把 video prediction(视频预测)作为一个辅助 loss,加到 action 学习里面,让模型在预测 action 的同时,顺带预测接下来一段时间的视频画面,那它的输入并不是真正的 action-conditioned,只是在用video prediction增强表征能力。
另一种更原教旨主义的定义是:world model一定要能输入action——比如机器人接下来往左动、往上移,这个世界会怎么变化;或者游戏里键盘的W/A/S/D指令会让世界怎么变化。只有接受action输入并预测状态变化的,才应该叫action-conditioned world model。

2. 但与其争论"到底什么是 world model",不如先回答一个更根本的问题:**你希望用world model去做什么样的事情?**目的倒过来定义了模型,倒过来定义了技术路线,也最终决定了benchmark。
在具身场景中,最核心的追求是希望world model能够直接出决策、直接在现实世界中行动。它和VLA这类直接行动范式的区别在于:行动前多了一层关于世界的想象——我这么动了之后,世界会发生什么变化?这种 multi-step reasoning ability(多步推理能力),才是world model 真正区别于其他模型的核心。
3. World model并不只属于具身智能。如果把视角拉远,AlphaGo里面的 value network(价值网络),本质上也是一种world model,你有一个 action 进来,它对棋盘状态产生disturbance(扰动),然后predict下一步会怎么样,再给你打分。
生物领域的虚拟细胞也是world model,你给了一种药,它对人体细胞层面会产生什么影响?自动驾驶里的仿真系统也是,它是deterministic(确定性的)的、不是generative(生成式)的,但它就是对那个世界的prediction。区别只在于,传统仿真系统的泛化能力太有限,它能做的事情是设计者想到了所有东西才能设计出来的prediction。
而今天我们希望world model真正能capture world,而不是只被设计者自己脑中的思考边界所限制。从这个视角来看,world model实际上是从 "确定性"走向 "概率性" 的一个跃迁,我们希望它能建模那些连设计者自己都没预想到的未来。
4. 最终,world model的严肃界定,可以收敛到一个公式:一个predictor(预测器),预测状态S到S' 在action条件下的变化。
剩下的一切分歧,本质上是三个问题的不同回答:什么是 state?predictor怎么设计?action怎么表达?State可以是像素、可以是latent、可以是3D几何、可以是细胞里的一组分子状态。Action可以是机器人末端的位姿、可以是键盘的WASD、可以latent action、甚至可以是一句自然语言指令。
这三者的不同组合方式,就决定了不同的技术路线和应用场景。
Language model站在了碳基生命的肩膀上——碳基生命完成的任务是抽象、表征、理解,language model 建立在这个之上。如果 language model 是"有了语言之后的智能",那world model要做的,是代替整个生命完成对世界中声、光、电这些信号的总结。
5. World model的终极形态可能是一种world intelligence:它跟语言推理、下棋、搜索是不同类型的智能。人类把触觉、听觉、嗅觉、视觉最终都变成了文字,文字对人类来说是好的 state,但对机器人来说未必。一个真正具备world intelligence的系统,需要为五感信号找到更好的representation space(表征空间,即模型对世界的内部抽象),而不是把一切都转化为文字。这也是为什么representation(表征)可能是world model今天最难、最核心的问题。
Insight 02
三条技术路线,各押不同的AGI
6. 当前 world model 可以粗略地分为四条技术路线。它们背后押注的核心假设不同,擅长的东西不同,命门也不同。
- 第一派是生成模型,以 Sora 或类 Sora 为代表,也包括 Genie 和 Decart。这一派的前身是 Midjourney、Stable Diffusion 这类图像生成产品,从image自然延伸到video。但早期video generation model本质上更像是image的线性外推,生成出来的东西可能是一个人做一些轻微动作,画面很漂亮,但缺乏长程逻辑。它们的需求是画质和美学,是text following(文本跟随)能力,这和今天world model需要的抽象与逻辑是完全不同的需求层面。Genie和Decart尝试给其中融入了autoregressive成分,让秒与秒之间有串联,但从效果来看,当时间尺度从秒级拉到小时级的时候,这些模型依旧很弱。
- 第二派是JEPA(Joint Embedding Predictive Architecture),由 Yann LeCun 提出并推动。JEPA 的核心方法论是在 latent space(隐空间)做压缩和抽象:它不试图去预测每一个像素,而是预测一个更高层次的表征representation,在这个representation里面摒弃掉无关紧要的噪音,只保留对理解世界变化真正重要的信息。从方法论层面来说,这个目标非常值得欣赏。但具体的 method,对比学习和mask model(掩码模型)的融合,在实践中的效果尚不令人满意。从Meta和 LeCun自己出来讲的时候对这个具体路线的着墨来看,他们内部可能也在重新思考这条路。LeCun已离开Meta创立AMI Labs,拿了10亿美金想要去做这个方向的scaling,但结果如何还需要时间验证。
- 第三派是空间智能,以 World Labs 为代表,从 3D 几何出发。这一派的思路是先做好 XYZ,先把三维空间建模做好,也许未来再加入时间 T 变成 XYZt。但今天还没有把时间引入,这使得它在时间建模上处于最初级的阶段。而 world model 有一个不变的核心,它总是在建模时间上的transition(状态转移)。不管输入是什么、action 在输入还是输出,时间 t 是那个最底层的维度。其他路线已经在做 XYT(视频)或 XYD(带深度信息的视频),World Labs 还在 XYZ,所以它必须思考 T 怎么引入。当然,这一派在落地上可能有优势,比如做 mesh(三维网格) 生成、做 3D 资产,这些不需要时间维度也能产生价值。
7. 真正在车上验证过的是第一派,第二派(JEPA latent rollout)在理论上有上限优势,但还没做出来。在一段式端到端的自动驾驶范式下,第一条路线,即生成式 co-training(协同训练),已经被验证是work 的:训练阶段把video prediction 加进去做co-training,来增强backbone(主干网络) 的表征能力,但推理阶段把video generation 部分砍掉,以满足实时性要求。JEPA 的latent rollout(在隐空间做推演)在理论上限上可能更好,如果能把所有表征都拉到隐空间做长程rollout,对长程任务有非常大的潜力。但在实践中,还没有人做出跟第一条路线一样好或更好的效果。
8. 有一位研究员说了一个比较激进的观点:"JEPA 是所有人都认为正确、但没有一个人能做出来的一场幻梦。"V-JEPA World Model 最新发布的最好的 paper,最终只做到了 Push-T这种用MLP就能跑通的小任务。而Veo 3的团队,被问到是怎么做出这么好的效果时,回答只有两个字:diffusion(扩散模型)加scaling。
与此同时,视频生成领域也在发生架构变动:据讨论中提及的非公开传闻,Veo 3的多模态联合生成团队,可能已经拆分并入了Omni team,Sora 2 也在公开尝试把AR和diffusion 混在一起。但这些都更像是multi-modal generation model(多模态生成模型),距离真正的world model还有很大距离。
再精美的画面,it doesn't mean anything。我们真正想要的是:我把杯子推倒,它会倒到我身上,我会跳起来、会破防,所以从结果来倒推,我不能做这么没素质的事。这种长程因果推理,才是world model和video generation的本质分水岭。
9. 如果把三条路线放在一起看,world model本质上是一场效率的比较。假设我们有无限大的模型、无限多的数据、全地球的电力都用来跑world model,那任何一条路线都能scaling出一个无敌的世界模型,但问题是我们没有这么多资源。
在机器人层面,末端最多部署一个7B的模型,延迟要求50-100毫秒。在这个约束下,架构范式的核心问题就是:谁的压缩比更高?谁能用更少的参数、更少的计算量,压进更多关于物理世界的知识?符合Bitter Lesson的那条路线,最终会在这场效率竞争中胜出。
世界模型的推理成本目前确实很高。据The Information报道,Odyssey运行其世界模型每用户需要一整张 H200 芯片,成本为数美元/小时,而运行一个 70B 文本模型只需几美分/小时。MoE Capital 的综述同样指出,Genie 3 的运行成本大约在 100 美元/小时。这些数字让"压缩比"这个问题变得格外紧迫。
10. 这几条路线未必是在同一个赛道里竞争。更可能的情况是它们在应用场景上逐渐分化:3D路线最后可能去做游戏引擎和数字资产;生成式模型可能更适合做内容创作;而对物理世界表达要求最严格的机器人场景,可能需要一种特殊的混合架构——比如一个20B的encoder(编码器) 加上一个 5B 的predictor。
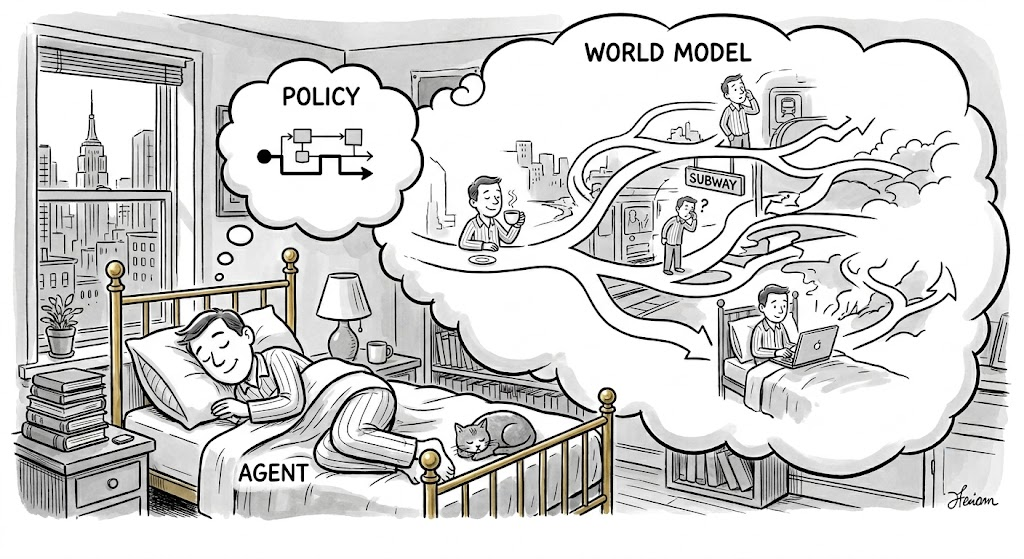
一种更本质的理解方式是:world model是梦境,policy是策略,agent是做梦的人。做梦的人行动,梦境回应;梦境回应,做梦的人再行动。而 action 是绕过传统仿真计算成本的"作弊码",在传统引擎中,模拟成本会随物体数量和互动复杂度急剧上升,场景越复杂引擎越慢;但 world model 在训练时,就把世界的运行模式吸收进了权重里,推理变成一次固定成本的前向传播,场景再复杂也不会让 engine 急剧变慢。(Not Boring × General Intuition, World Models: Computing the Uncomputable)
Insight 03 Benchmark:评估世界模型为什么比评估LLM难得多
11. 语言模型的benchmark形态相对单一,做好next token prediction,few-shot的事就解决了。但world model的任务形态天然更复杂:state 是多模态的、action 是异构的、时间尺度跨越从毫秒到分钟,这使得 few-shot在world model里比在language model里要难走得多,评估它的benchmark也相应地复杂很多。
12. 当前具身benchmark的设计存在两个典型问题:要么任务设计"反人类":比如让机器人用单臂去踢足球,这并不反映任何真实操作需求;要么一旦任务设计得真实(比如让机器人在家庭场景里完成长时序指令),所有前沿模型的成功率最高也只有22%左右,包括Dreamer Zero和π0.5。在这种"大家都一塌糊涂"的情况下,benchmark失去了区分优劣的能力。一个好的benchmark(比如Mandarin)应该偏向人类常见操作,而不是为了为难机器人而设计,也不应该为了拍好看的demo而只做最简单的pick and place。

13. 从评测技术的角度来看,当前评估世界模型有三个主要方向,每个方向都有自己的 gap:让 VLM 直接做理解(但 VLM 观察不到细节形变和微妙的物理量变化),用潜空间模型(如 JEPA)做latent距离计算即"surprise 值"(但 latent 本身没有解释性),用像素级追踪(如 CoTracker)做运动分析(但会被视角变化和光线干扰严重影响)。这三种方式单独拿出来都不够,需要组合成一个 Agent 系统来综合评测。但这样的系统目前还不存在。
14. 长时间rollout不崩溃是一个关键的评估维度。如果世界模型能支撑分钟级的自主rollout而不崩溃,它就可以充当一个安全的 simulation(仿真) 环境,替代真机 RL。这意味着可以像大语言模型做 RL 那样,大规模并行地在 world model 里跑强化学习,用 compute 换 simulation。但这又是一个鸡生蛋的问题:要让 world model 不崩溃,你需要大量 corner case(长尾边角情况) 的数据(比如杯子掉地上碎了之后怎么办、桌子被撞烂了会怎样),这种数据在正常操作中极其稀少。
要收集这种数据,可能需要大量机器人先被部署到现实世界中去 rollout,但大规模部署在商业上又不现实。在自动驾驶领域,这类长尾数据的采集要容易得多,量产车天然就是数据采集器,影子模式已经玩得很成熟。但对人形机器人或轮式机器人来说,这个矛盾短期内很难解开。
在本场讨论中,有一个尖锐的类比:明明我们在试图scaling出AGI level的super-intelligent,但我们在用300年前爱迪生造灯泡的方法去evaluate——每天换一种灯丝,换了三年终于发现钨最好。训模型的时候总共就三个事情:什么是 data、做什么模型、最后就是怎么benchmark。而 benchmark 的效能直接决定了迭代速度的上限。
15. 一个可能的破局思路是游戏化benchmark。益智游戏天然具有数学性的难度梯度——迷宫的复杂度随层级指数上升,汉诺塔可以解到 5 层、10 层、1 亿层,你永远有无限的OOD(out-of-distribution)样本。这种设计不依赖准确率(你不需要 99.9% 的成功率来标定一个模型),而是通过"你能闯到多少关"来衡量能力等级,就像语言模型里数学题所扮演的角色一样:一个有天然梯度的黄金 playground。如果 world model 的 benchmark 可以从准确率转向闯关式的能力等级衡量,那模型迭代的效率会被大幅加速。
16. 从test-time scaling(推理时算力扩展)的角度来看,world model是否存在类似语言模型o1那样的"多想一会就做得更准"的特性?一种直觉是:如果给模型更多 test-time compute,比如 rollout 100 次再选最优结果,效果应该会提升。实际实验也验证了这一点:用 video generation model 加多模态大模型做 generation 100 次,然后选质量最好的,效果确实有提升。但关键瓶颈在 critic model(评判模型) 上:你 test-time scaling 完之后,怎么判断哪个 rollout 是最好的?前置条件还不成熟,我们能生成一个人平静地走 10 分钟的视频,但还做不到让这个人走在路上遇到突发情况、发生一系列连锁反应的多变化节点生成。
17. 不过,从具身的角度来看,有一种隐性的 test-time scaling 已经在发生。机器人有一个跟语言模型本质不同的特性:无论你在某一步输出的 action 是对还是错,真实世界都会给你返回一个一定是真实的观测(因为你有摄像头)。这意味着机器人 context 里存的所有 history 都是这个世界真实发生过的事情。
带 memory/history 的模型可以利用这一点来补充 partial observation(部分观测) 的信息量。一个经典的例子是开冰箱:如果用不带 memory 的 VLA,它每次都会去试开右边的门,因为它不知道自己上次已经试过了打不开。但如果模型有 history,它知道"OK,我开右边的门打不开了",就会去试左边。这种通过行动探索来补充信息量的过程,本质上就是一种 test-time scaling,你多花了一些时间去探索,但你解决了 partial observation 的问题。很多时候 VLA 做不到的事情,不是因为模型能力不够,而是因为信息量不够。Memory 模式正在成为缓解这个问题的关键范式。
Insight 04 数据而非模型,驱动具身进展
18. 什么事情发生了,关于world model 的讨论就可以结束?一个比较明确的答案是:真正的zero-shot(零样本)或few-shot 机器人。今天所有自称"通用机器人模型"的系统,大概率都是overfit(过拟合)的:你要在一个具体的本体上,完成一个具体任务,一定需要这个本体特有的数据和场景。如果有一天,来了一个全新的本体,只需要做几个few-shot示范,模型就能自动推导出,在这个本体上应该怎么操作、完成unseen task(未见过的新任务),那就是机器人的 GPT-3 moment。GPT-3 的paper标题就是 "Language Models as Few-Shot Learners",不需要再训练、不需要 fine-tune(微调),直接在unseen task上做few-shot,这是语言模型最关键的能力跃迁。
今天在world model领域,已经观察到了一些few-shot的性质,但这些 few-shot性质所覆盖的任务,还未必是最具价值的那些。而且world model的few-shot,比语言模型的few-shot天然更难,语言模型的task只有文本一种形态,做好next token prediction就行;world model需要同时泛化到predict next state、predict next action、以及state-action 的各种组合,task形态天然更复杂。
19. 回顾具身智能的进展历史,每一次跃进几乎都是由数据驱动的,而非模型驱动的。从通过遥操收集数据训练large behavior model,到 RT-X 等项目汇聚多构型机器人数据,到Physical Intelligence大规模采集真实数据推动π0.5的出现,到UMI等无本体采集方式让数据量级提升10-100倍,再到Ego-View异构数据的兴起,英伟达EgoScale等工作验证了关键的Scaling Law,证明第一视角的人类活动数据可以大幅扩充具身的数据量。每一次跃进的背后,都是数据范式的突破而非模型架构的创新。
20. Ego-View可能是通往真正泛化的关键一步,甚至可能是唯一一条可行的路。逻辑很简单:把人当成另一种类型的机器人,在人身上装传感器,大规模采集人类在真实环境中与物理世界互动的数据。但目前最大的 Ego-View 数据集也只有10 万小时量级,距离百万、千万、上亿小时还有很远的距离。如果Ego-View 这条路走不通,很难想象具身还有什么别的路可以通往真正的泛化。
LeCun曾指出过一个类似的矛盾:我们的 AI 在某些方向上已经和通过律师资格考试的律师一样聪明,但它做不到一只猫能做的事。语言模型的成功建立在碳基生命已经完成了"抽象"这个任务的基础上,而world model要从零开始学习物理世界的运行规律,这个任务的难度要大得多。
21. 今年大概率还不会出现world model的分水岭。异构数据的采集仍需要时间,而且diversity比quantity更重要,单纯堆量而缺乏场景和人类 pattern 的多样性,意义有限。但趋势是积极的:除了 VLA 之外,机器人领域正在出现更多的技术路线可以选择走,world model就是其中一条。当不同路线在不同场景中逐渐分化、各自找到自己的位置,world model这个看似模糊的大概念,才会真正落地为一组具体的、可迭代的、有Scaling Law 的工程实践。
22. 讨论的最后,有朋友抛出了一个刘慈欣"朝闻道"式的问题:如果有上帝能回答你一个问题,你最想知道什么?有人说,想知道 world model 到底能不能真正反映物理意义上的交互,比如不同力度去抓不同软硬度的物体,它能不能预测出对应的形变?如果做不到,那world model做simulator和传统物理引擎做仿真相比,到底谁更接近真实物理?也有人说,想知道 Ego-View数据scale到上亿小时之后,具身是不是真的能涌现出泛化能力,如果这条路走不通,可能就没有别的路了。
"如果有'上帝'能回答你一个问题,你最想知道什么?"——这个问题本身就是这场讨论最好的注脚。World model 今天还远没有标准答案。
我们离让机器真正理解这个世界,还差几个数量级的数据、几个数量级的压缩比、以及几个我们现在还无法想象的范式级突破。但至少,路已经不止一条了。


五源寻找、支持、激励孤独的创业者,为其提供从精神到所有经营运作的支持。我们相信,如果别人眼中疯狂的你,开始被相信,世界将会别开生面。
BEIJING·SHANGHAI·SHENZHEN·HONGKONG
