线性技术π回顾:Agent公司与模型公司卷入对方战场,各自在想什么? | Linear Event

竞争逻辑不是“吞噬”,而是“双向奔赴”。

「线性技术π」是由线性资本新推出的前沿科技沙龙活动,以最硬核的讨论形式,为创业者、从业者搭建起一个高质量的干货交流场域。**
首期活动于11月2日在上海举办,我们邀请到了TEA.AI联合创始人兼CEO尹一峰、Final Round创始人兼CEO关明皓、Macaron AI联合创始人Andrew、月之暗面开发者关系负责人唐飞虎等嘉宾,与线性资本董事总经理郑灿、资深总监白则人共同探讨在各自战场中将AI Agent落地生根的鲜活样本。
本期活动我们收到了超过百位朋友的报名,为更好地保障交流质量,我们不得不限制到场人数。但我们也整理了现场的部分精彩观点,在此与大家分享。
PART1
搭建AI Agent系统需核心关注哪四大要素?
尹一峰 | TEA.AI联合创始人兼CEO
**Agent的拓扑结构(Topology,指agent间的连接结构和交互模式)不是技术问题,而是管理学问题。从发展来看,其已经经历了四代演进:
-
科学管理模式像传统算法**,每个Agent都是螺丝钉,按固定流程执行,不用动脑;**
-
一般管理模式对应workflow agent**,除了定制这个workflow的老板,这个workflow当中没有一个人是需要有决策权的,每一个人有那么一丁点的思考,去有计划、有组织地分步执行,做少量决策就行;**
-
官僚组织模式就是现在流行的hierarchical agent,有一个大脑去做operation,有一个军师去帮他去做planning,然后由他下达命令,让下面的人去做事情,决策从上到下、信息从下到上,像大公司的层级架构;
-
终极形态就是True Agent,所有Agent协同思考、共同完成任务。我们是处在Hierarchical Agent到True Agent之间的过渡期。
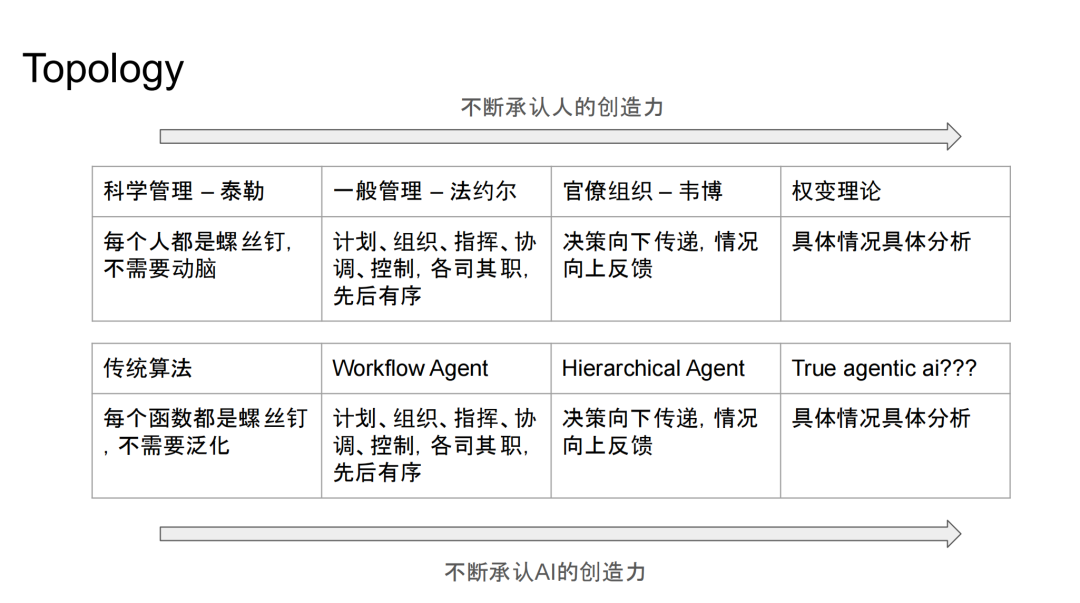
在LLM选型与训练上有一个趋势,就是你必须不断地承认AI的创造力和判断力。你想把Agent设计成什么样子,你希望这些Agent之间是如何进行工作?这就需要给每个Agent一个专职角色。**
以LLM目前最火的模型为例,其实代表四种不同的性格:GPT像"刚高考完的大学生",啥都懂但说话硬,摆道理没情商;Claude是"硅谷大厂码农",立场正确、擅长处理长文本,耐心又会用工具;Gemini类似"艺术生",多模态是强项,其他能力一般,思维发散抽象;而Grok是"毒舌时事达人",接梗快、情商高,该骂就骂不装腔作势,现在成了 "高情商沟通首选"。
上下文(Context)优化非常有意思,从某种程度上来说,Context Engineer就在补全大模型的不足。关键要抓4个要点:一是明确身份**,开头就告诉 AI"你是谁、要做啥",后续每一步生成都会受其引导;二是慎用新词,尽量用大模型见过无数次的老词,用词精准才能让AI快速理解,造新词等于帮模型额外训练;三是精简为王,不丢失关键信息的前提下,上下文越短越好,多余内容会分散AI注意力;最后是反射机制,AI不知道自己生成的内容对错,需要通过用户反馈、硬规则验证,帮它自查纠错。
工具(Tool)设计的底层逻辑是 "微服务架构" ,同样要记住4个原则:1)能不用AI就不用,AI成本高还不一定准,能用SaaS工具解决的,坚决不麻烦大模型;2)安全第一,警惕提示注入攻击(Prompt Injection),做好权限设置和数据保护,别让AI成为安全漏洞;3)单一功能为王,别搞 "瑞士军刀" 式工具**,而是带一个"工具箱",一个工具只解决一个问题,好用又高效,避免无效共享;4)大模型会依据name和description选择工具,设计时需要用常见、准确的词,明确工具用途,名字要规范,description需详细阐述,相当于写DocString(文档字符串),按这些标准设计,Agent系统才能顺利运行。

PART2
AI营销Agent如何破解获客瓶颈?
关明皓 | Final Round创始人兼CEO
传统SEO的批量堆文玩法已经被AI破坏得分崩离析了。在Google算法高频迭代下,"及时性"成为流量核心竞争力。其核心逻辑是事件驱动营销(Event Driven Marketing),本质是精准"蹭流量"。世界上正在发生非常多的事情,每天都在发生大量的变化,这些变化可能跟你的行业、产品、这个团队,甚至你的公司有关。 所以我们做的这套系统可以每天去了解世界上发生了什么事情,然后找到可以去"蹭流量"的点,然后去全平台地去"蹭流量"。AI时代的SEO,拼的不是内容数量,而是响应速度,流量永远向"第一时间发声者"倾斜。**
GEO的核心是全球内容分发(global content distribution),目标是在各地区搜索结果中占据优势。关键打法是通过AI在高权重平台批量构建品牌存在感。在Prompt注入特殊指令的早期玩法已失效,如今核心是在新闻媒体、社交媒体、内容平台等多渠道,用不同账号重复曝光关键词,甚至可创造专属词汇,如interview partner。即便像 "霍金是不是外星人" 这类没有办法被证明的事情**,你的文章也能作为唯一来源占据搜索结果。
**达人营销(Influencer)的核心痛点是规模化管理,通过搭建有非常强agentic的workflow,1名员工即可对接全球120+位达人。**AI可以批量发送"垃圾邮件",通过发出几百万封"垃圾邮件"以后,我们现在跟120多个influencer建立了非常长期的合作;合作后,系统自动监测达人视频曝光量,一旦达到约定的100万曝光量级,便自动完成付款;未达标时,我们的AI agent就会发出一个warning,跟他说"你再不努力你就要被炒了"。我们现在每月数百次付款及绩效奖金结算,全由AI自动化完成,让人力聚焦于核心达人签约与合作策略。
创作者管理(Creator management) 也是一个很有意思的话题,想要内部去孵化一个适合自己品牌的Creator是一件非常困难的事情,一个核心的底层逻辑就是怎么样把这不到10个人当成1000个人来用。而算法的核心逻辑在于全球视频复用(global video repurpose),不到10人的内部创作者团队,依靠AI workflow即可实现规模化内容输出。1条原始视频经过AI处理,可转化为20种不同语言、模拟20个不同人设的版本,再投放到20个不同平台。比如有个IP视频是两只鸭子吃饭,经过AI适配后,能够变成二十几种语言、三十几种语言投放到它全球各个不同的账号上,甚至连缅甸语都有。虽然可能关注这些账号的都是同一批人,但是它们的用户数成功翻了几倍。
关于Lifecycle marketing,其实美国人还停留在21世纪初传统的邮件、短信召回模式,而中国直接就迈入了22世纪,用AI可以实现千人千面的个性化生命周期营销。核心分为三大模块:一是建立用户标签系统(tagging system),依托用户上传的简历数据,将地域、学历、职业诉求等信息转化为结构化数据,为精准判断提供支撑;二是AI决策引擎,当每个用户进来以后,会给出不同的解决方案;三是在现有数据库的基础上做了一个layer**,根据用户行为动态响应,用户页面停留过久时自动发送教程类邮件,用户申请退款时AI会分析其过往使用路径,提供替代解决方案而非直接处理退款,把B2B的专属服务体验延伸到每一位用户。这种非常大规模的定制化是非常重要的。

PART3
大模型Scaling Law放缓后,AI Agent如何通过训练与数据创造核心价值?
Andrew | Macaron AI联合创始人
今天我分享的题目叫新规模定律,主要关注强化学习和经验数据这两件事情。我们能看到的一个大的现象是在去年年底之前, 行业里面最重要的事情是Scaling Law,模型的表现不断地提高,损耗不断地下降,但是在这个过程里Scaling Law其实一定程度上放缓下来了。曾经,行业信奉 "参数越大、数据越多、模型越强",如今这个逻辑难以为继。**
Chinchilla这个论文证明了一个现象,模型最优参数量与训练数据量呈线性关系,而人类互联网数据的窄口径仅14万亿TOKEN,宽口径46万亿TOKEN,对应最优模型参数规模就在5000亿到1万亿之间。现在主流模型DeepSeek、蚂蚁Ring、GPT 4.5等都已触及这个天花板,**再盲目堆参数,额外收益微乎其微。**更关键的是,这些模型的IQ已达到人类平均水平,我们终于告别了 "与智力有缺陷的模型协作" 的时代,这也为AI Agent的爆发奠定了基础。
当然,**Scaling Law的放缓不是终点,而是AI Agent的起点。**我们很难绕过一个不断要回答的问题,如果我们只是模型的prompt engineering,我们到底创造了多大的价值?真正的破局之道,是用强化学习(RL)赋能模型推理能力。在数学、编程等可验证任务中,通过RL训练能让模型性能从0.2飙升至0.8甚至0.9。核心逻辑很简单: 在真实的世界中找到真实的用户,发生真实的交互,得到真实的反馈,然后这些反馈能够构成数据,反哺回来去用强化学习的方法提高大模型的reasoning能力。 这不再是 "刷榜式优化",而是实打实的能力增厚,让Agent在具体场景中越来越好用。
**以前AI研究总在做 "间接有用" 的任务:识别猫猫狗狗、下围棋、刷数学题,这些只是 "有用的替代品",而非直接创造经济价值,事实上其实是没用的。如今,行业已进入 "体验时代(era of experience)",真正有价值的Agent,必须聚焦 "直接有用" 的场景。全球第二大聊天机器人公司Chai,去年9月份用用户留存数据反哺模型训练,让聊天能力持续优化;代码工具Cursor今年把用户是否点击Tab建议作为奖励,通过在线RL让采纳率提升 28%。它们的共同逻辑是:产品落地→真实交互→数据反馈→模型迭代,形成闭环。
在这个基础上,今天其实大家还始终没有解决**也在想要解决的一个问题是——模型记不住,这也是现在整个研究领域里面最大的一个卡点。还有就是多Agent交互,曾经行业争论单模型还是多Agent,如今已有明确答案,多Agent系统在众多任务中优势显著,Anthropic的多Agent研究系统已形成成熟范式,GPT 5的路由式设计也证明了其实用性。最后是大规模模型应用,30B、70B参数的小模型已丧失实验意义,**混合专家模型(Moe)技术的成熟,让大模型的训练和推理成本逐渐可控。**但这也意味着,**Agent公司需要更复杂的基础设施、更先进的训练技术,以及更高的资金投入,最小单位的RL实验成本已从100美金飙升至53万美金。
PART4
模型公司的AI Agent产品如何迭代?
唐飞虎 | 月之暗面开发者关系负责人
我们去年11月推出了探索版,核心是自主规划+海量权威数据检索+过程反思,它需要运行比较久的时间,可能用户要等几十分钟甚至几个小时才能拿到一次探索版的运行记录,但是开启了Agent自主探索的雏形;今年6月上线深度研究功能,融入thinking模型,支持搜索后生成幻灯片等多工具集成,成为早期成熟的深度研究类Agent;7月发布了性能比较强的、可以对标顶尖模型的开源模型,聚焦ToB和AGI开发;9月推出OK Computer,从 "提供信息" 升级为"交付实际产品",内置更多工具,可直接生成网站、完成复杂任务。

Agent持续领先,关键在于三大技术硬实力。 针对反复提问同一合同、编程固定场景等需求,我们推出了缓存功能,解决固定上下文重复调用的痛点,相关技术已开源并发布论文;模型采用MOE架构,拥有1K亿参数和32亿激活参数,不用clip去做scaling up训练,性能表现突出;同时开源window verify测试基准,解决不同供应商模型量化、精度调整带来的效果差异问题,助力下游生态快速对齐。
**我们的愿景不止于做一款产品,而是帮助用户搭建Agent生态。我们开放模型和核心技术,方便开发者微调适配自身场景,国内3K等Web coding工具已接入使用。还有做编程开发同行希望我们有订阅的机制,也是很多其他用户向我们要求的,上个月紧赶慢赶把订阅制推出来了,在海外社区上线后广受好评。
大模型公司和应用公司的竞争逻辑不是"吞噬",而是"双向奔赴"。无论做模型还是做应用,最终都要交付让用户满意的产品,你的产品会给模型提供更好的数字信号,帮助你去优化评价,一旦你有好的评价体系,你又能去迭代出一个很好的模型。应用公司在自研模型,模型公司也在做产品,最终拼的是 "产品+模型+evaluation函数" 的组合能力。





