Bolt观点|如何衡量(通用)人工智能?

Zapier的创始人之一Mike Knoop最近在著名的AI竞赛社区Kaggle上发起了一项名为ARC Prize的挑战。在挑战的主页上,写下了这样的话:"通用人工智能(AGI)的进展已经停滞。我们需要新的想法。"
Zapier的创始人之一Mike Knoop最近在著名的AI竞赛社区Kaggle上发起了一项名为ARC Prize的挑战。在挑战的主页上,写下了这样的话:"通用人工智能(AGI)的进展已经停滞。我们需要新的想法。"
在这个AI和大模型如火如荼的时间,这样的话听起来很奇怪。但要讨论这个命题,我们需要先讨论一个更基本的问题:什么是智能,以及如何度量智能?
先从ARC Prize的发起人来解释它具体是什么。ARC Prize来源于2019年发表的一篇文章"On measuring intelligence",作者是Francois Collet——他是最广为人知的机器学习框架之一Keras的作者、也是这次挑战的共同发起人。在这篇文章里,Francois Collet总结了过去对智能的定义和度量标准,给出了自己的视角:
仅评估技能本身并不能让我们在追求智能的道路上前进。因此我们需要新的评估标准。这个标准需要严格限制先验知识,经验和泛化难度。
前半句可以从之前被诟病无法泛化的深度学习看到影子。但重点是今天依然如此(即使评估的是如同写作,绘画这样的综合技能)。我们总可以针对技能相关的问题空间采样,从而训练智能系统。我们可以在这样的评估体系下优化,但得到的系统无法泛化。
这篇文章给出了一个完整的框架,来量化评估针对特定先验知识,经验和泛化难度任务下的智能。文章也在最后给出了一个评估标准(benchmark),称之为ARC。如作者所说,这个标准提供了高度抽象的任务,仅给出少量的例子(也无法通过机器生成更多的例子),从而测量泛化性。另外,这个测试当中,仅仅记住训练集对于测试结果毫无帮助。而这一次的ARC Prize其实就是基于这个评估标准。
下图是一个ARC问题的示例:
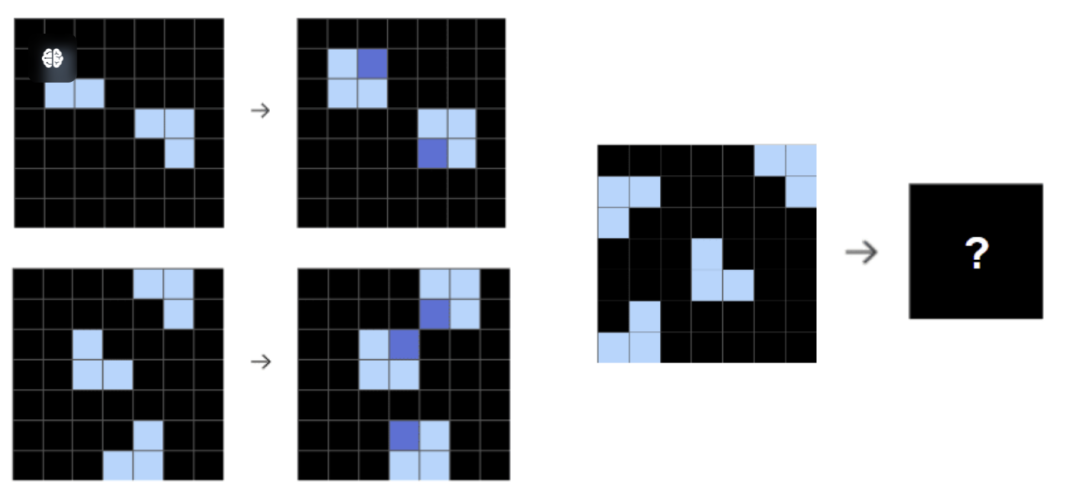
一个ARC示例,根据左边两个例子,完成右边带问号的图案
可以看到ARC由人类完成并不难。事实上,普通人在公开的训练集的准确率大概在85%(用来评估的测试集比训练集难,通常得分会低10%,所以虽然没有统计,可以估计普通人大概可以达到 75%)。但 ARC 对于AI却绝对谈不上容易。Francois 在四年前就发起过一次ARC挑战。那次的比赛中,获得第一名的算法在测试集上得到的正确率是21%。按照主办者的说法,到这次挑战之前AI的最好成绩是34%。我看了看目前挑战中的排行榜,榜上最高分是39%。
我们很自然地会问,今天的大模型在这项挑战上表现如何?遗憾的是,标准的ARC挑战不能使用互联网,这和Kaggle竞赛的形式有关,因为要确保保密的私有测试集不被流出。但最近Redwood Research的一位研究者Ryan Greenblat在公开测试集(难度大概等于私有测试集)上利用GPT-4o达到了50%的准确率,也是目前AI的最高水平。也是因为这个结果,虽然无法去私有测试集上测试,竞赛主办方额外准备了一套从未出现过的半公开测试集,这个算法的准确率达到了43%。
作者专门写了Blog来介绍他的方法。说起来并不复杂。大概分几步:
1、让GPT-4o为每道题提供5000套不同的python代码提供解法
2、在第一步的答案中挑出12个最好的候选代码,然后再让GPT-4o做一遍优化,提供3、3000套不同的优化后的代码。
最后在测试集上,让所有在训练集上答对的解法提供答案,选择得票最高的答案提交。
当然这个方案中还有许多细节,作者做了很开放的讨论,在这里就不一一搬运,有兴趣的朋友们可以去看原文(点击文末阅读原文)。
这个结果告诉我们什么?
- 首先,ARC的确是个非常有意思的衡量标准。 考虑到这篇文章的发表比ChatGPT还要早三年,使之显得更加具有穿越时间的价值。在我看来,和很多其他标准相比,ARC充分找到了AI和"智能"之间的最大差距。一方面,五年以来依然没有一个AI能够及格。更不用提和人类相比。另一方面,这个标准几乎不需要任何先验知识。比起同样不容易的编程(e.g. SWE-Bench),ARC更纯粹地考查智能,而不需要技能。
- 先来回答第一个定性的问题:**LLM到底有没有智能?**我们可以假设LLM没有对ARC的先验知识(这也是ARC的美妙之处),因此这个问题可以接近等价地转换为"LLM有没有从提示词(示例和指令)当中学到什么"?答案是肯定的。虽然最后答案是从海量投票当中得到的结果,但如果所有候选算法都没有任何的贡献,最后当然不可能得到这样的优秀成绩。这个答案远不是看起来那样理所当然。我猜测大模型是我们第一次能通过AI而非符号化算法来解决ARC问题。
- 下一个问题则更加具体:**LLM的学习能力到底有多强?**这比前一个问题复杂得多。显然LLM还不够强,不然我们不需要海量候选算法和投票了。如果要更加定量的回答,我们还有一些能寻找的蛛丝马迹。Ryan像一个很典型的Kaggle参赛选手,具体描述了他如何逐步扩大他的解法池,和每一步扩展达到的结果。最值得我们参考的是最开始仅使用1000个候选算法的时候,算法能够达到25%的正确率。大致上我们可以认为这是1000个GPT集思广益达到的结果。
如果仅使用一个 GPT 会是什么结果?主办方很贴心,在公布办公开测试集的时候同时测试了直接用主流大模型解题的结果。结果见图:Claude 3.5得分14%,一骑绝尘;GPT-4o和Gemini 1.5分别在5%和4.5%。这个结果可以参考作为今天模型的智能(用来和普通人在公开测试集可能的得分75%得分)。我没有看主办方的测试程序,但猜测一定还有提升的空间,比如更好的输入方式和更详细的指令。按Ryan的说法,他的解题提示词大概达到了30K token。
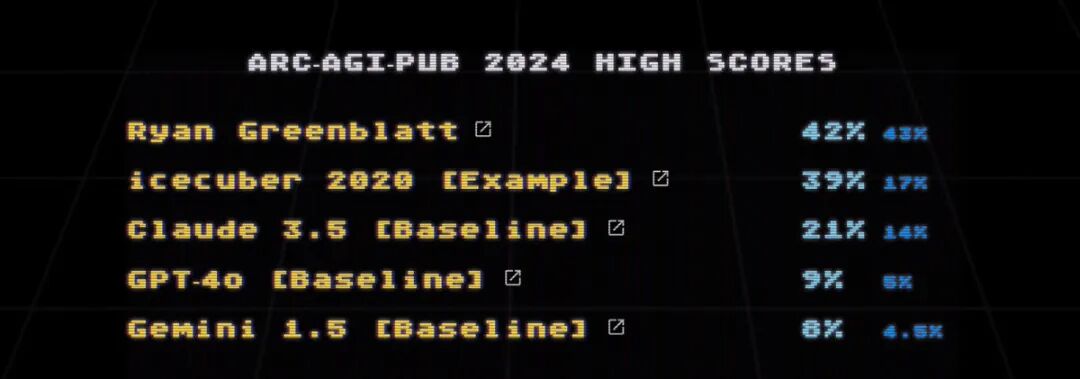
半公开测试集的排行榜(包括主流大模型)
所以,如果用ARC衡量大模型的智力,大概可以认为在这两条线之间。比如GPT-4o就在5%到25%之间。最后,从这个榜看,Claude 3.5的成绩简直惊艳。
- 另外一个给我们的启示:智力可以来源于系统,而不仅仅是模型。事实上,因为有MoE和其他技术的存在,模型和系统之间本来也没有一道清晰的鸿沟。参加过Kaggle 竞赛的朋友们都知道组合模型(Ensemble)的价值,但Ryan的方案再一次提醒我们,可以通过聪明地组合海量的大模型来获得"智能"。事实上,在他逐步扩大采样量的过程中,得分和采样量呈现几乎完美的指数关系。假如在更高分数的范围内这个指数关系依然适用,如果不考虑成本,只要200万的候选算法,机器就能达到70%的准确率,大概和人类接近。要知道在探索智能前沿的道路上,成本永远是我们最后考虑的问题。这个解法也可以用在其他需要真正智能,可以忽略成本的场景(比如军事?)
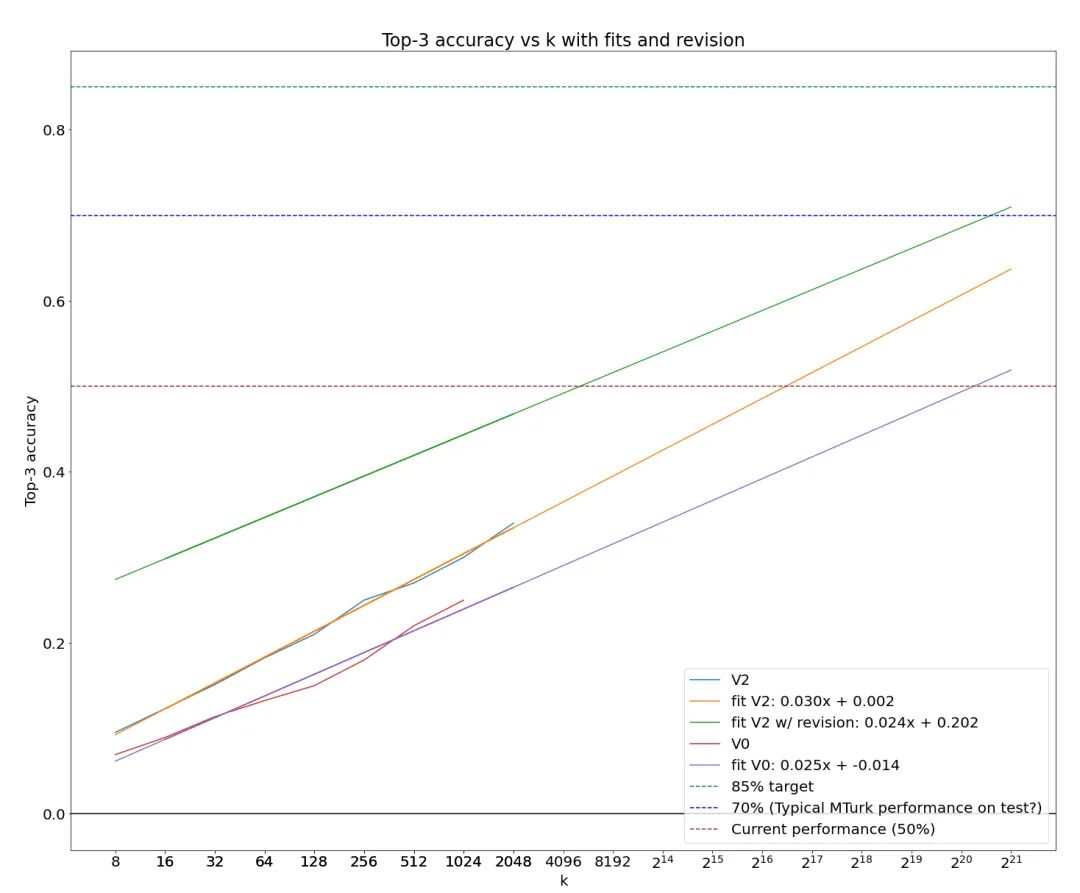
采样数量和得分的完美指数关系
写在最后
当然,ARC不是一个通用智能(AGI)测试。在ARC上达到或者超过人类水平,并不代表我们已经到达AGI。**但它是一个很好的探索,寻找AI和人类之间最明显的差距。**如果解不了ARC,我们肯定还没达到AGI。从这个角度,对衡量智能感兴趣的朋友都值得去看看Francois 2019年的这篇文章。
另外,我们确确实实在通往通用智能的道路上不断前进着。 即使今天看起来依然差距很远,但至少我们看到了一点亮光,这种不停止的进步让人感觉激动而紧张。从历史看,比起从0到1,1到100 的发展速度不仅要快得多,也往往远超我们的预测。随着我们在这条路上的不断探索,未来一定会有更好的衡量标准涌现出来,从而大大加快系统能力的进步。如果你对通用智能,或是如何衡量通用智能感兴趣,欢迎和我们讨论(我的微信:Can_Zheng)。
Bolt Community
如果你是认同Bolt观点的AI浪潮的探索者,希望和志同道合的小伙伴一起讨论,欢迎通过扫描下面的二维码向我们简单介绍一下你自己,审核过后会邀请加入讨论。
PS:封面图片由 ChatGPT 生成
Linear Bolt Bolt 是线性资本为早期阶段、面向全球市场 AI 应用专门设立的投资项目。它秉持线性投资的理念和哲学,专注在技术驱动带来变革的项目,希望帮助创始人找到实现目标的最短路径,不管是行动速度,还是投资方式,Bolt 的承诺是更轻,更快,更灵活。