Coconut by Meta AI:利用连续思维链做更好的LLM推理|Bolt荐阅

更好的推理,更少的Token消耗

Meta研究团队最近发布了一篇论文,阐述他们创新性的提出了一种名为Coconut(Chain of Continuous Thought,连续思维链)的方法,让LLM的思考过程在潜在空间进行,摆脱基于词语推理的约束。实验表明,Coconut方法显著增强了LLM的推理能力,其次,潜在空间推理能够减少token消耗,还可以使模型在规划密集型任务上能够做出更好表现。这为自然语言处理(NLP)领域带来了更多可能的新方向。 AI Papers Academy提炼了论文的重点信息,涵盖Coconut的研究背景、训练方法、实验结果等介绍,我们做了翻译和整理。AI Paper Academy的原文可以通过点击「阅读原文」链接进行查阅。
原论文PDF链接:https://arxiv.org/pdf/2412.06769
大语言模型(LLM)展现出了令人惊叹的推理能力,正在渗透到我们生活中越来越多的领域。这些模型通过在大量人类语言上进行预训练来获得这种能力。从这些模型中提取最准确响应的一种常见且强大的方法被称为思维链(Chain-of-Thought,CoT),我们通过这种方法鼓励模型逐步生成解决方案,为得出最终答案提供推理过程。然而,LLM的推理必须以词语的形式生成,这对模型施加了一个基本约束。
神经影像研究表明,在推理任务期间,人类大脑负责语言理解和产生的区域大部分保持不活跃。这表明语言是为交流而优化的,不一定适合复杂的问题解决。如果人类在推理过程中并不总是将思维转化为词语,为什么人工智能要这样做呢?
在这篇文章中,我们将深入探讨Meta这篇论文,标题为:"Training Large Language Models to Reason in a Continuous Latent Space"。该论文旨在通过使用一种称为Coconut(Chain of Continuous Thought,连续思维链)的新方法,让LLM摆脱基于词语推理的约束。
 图|Paper authors and title
图|Paper authors and title
Part.01
CoT与连续思维链(Coconut)的对比
下面这张来自论文中的图片对比了思维链(CoT)方法与连续思维链(Coconut)方法。我们可以通过这张图深入了解连续思维链方法的工作原理。
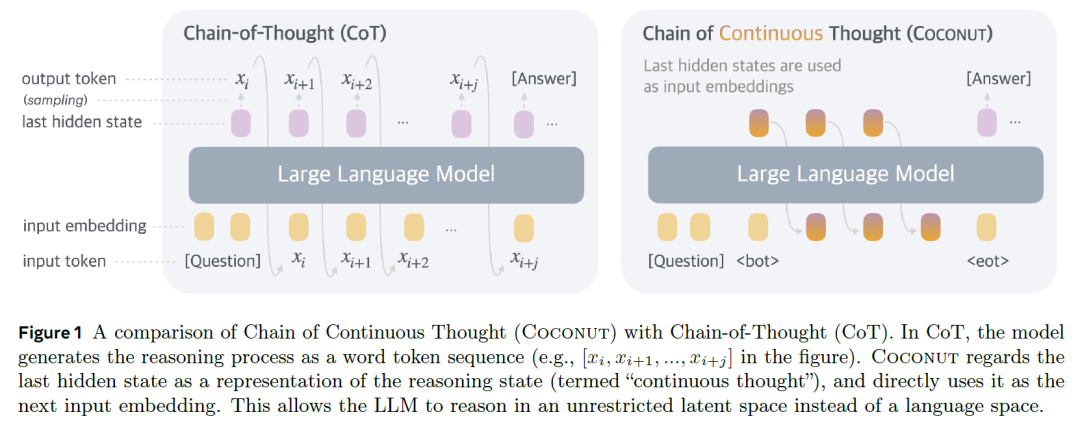 图|CoT与Coconut方法工作原理的对比
图|CoT与Coconut方法工作原理的对比
思维链(CoT)方法 在上图左侧,我们可以看到思维链方法的工作原理示意图。该方法的工作流程可以分为以下几个关键步骤:
-
初始输入处理:系统首先接收问题输入,并将其转换为input token输入到大规模语言模型(LLM)中。
-
推理过程启动:模型生成响应中的第一个token,这标志着推理过程的开始。这个token来自模型的最后一个隐藏状态(hidden state),即主干Transformer网络(backbone Transformer)最后一层的输出。隐藏状态包含了模型对输入信息的高维表示,为后续推理提供基础。
-
迭代推理过程:系统进行多次前向传递(forward pass),每次都将问题和当前已累积的推理过程token作为输入。这种迭代方式使模型能够逐步构建完整的推理链,每一步都基于之前的推理结果。
-
生成最终答案:一旦模型完成了完整的推理过程,系统继续进行前向传递以生成最终答案。
CoT方法的关键特点是它通过显式的语言token序列来表达推理过程,每个推理步骤都被转化为可解释的语言形式。这种方法虽然直观且易于理解,但也受限于语言表达的离散性质,这正是后续Coconut方法试图突破的限制的地方。
连续思维链(Coconut)方法 Coconut方法的核心创新在于引入了双模式运作机制,使模型能够在语言模式(language mode)和潜在思维模式(latent thought mode)之间灵活切换。这种设计突破了传统方法仅依赖语言token进行推理的限制。
模型在两种模式下的工作方式如下:
-
语言模式:在此模式下,模型作为标准语言模型运行,按照常规方式生成下一个token。这种模式主要用于输出最终结果。
-
潜在思维模式:在此模式下,模型利用隐藏状态(hidden state)直接在连续潜空间中进行推理。这种方式避免了将思维过程转换为离散token的限制,使推理更加灵活和高效。
Coconut 方法的具体工作流程:
-
初始化阶段:输入问题并附加特殊的起始token
标记潜在思维模式的开始,模型处理输入并生成隐藏状态表示。 -
潜在思维模式阶段:不同于CoT生成具体的token序列,Coconut直接使用模型的last hidden state(最后隐藏状态)作为思维表示,这些隐藏状态被直接用作下一步的输入embedding,形成一个连续的思维链,在潜在空间中进行推理。
-
转换阶段:使用特殊的结束token
标记潜在思维模式结束,系统切换回语言模式,开始生成最终答案。
Coconut方法的主要创新点在于它允许模型在连续潜空间中进行推理,这种方式相比传统的离散token序列能更自然地表达复杂思维过程、减少了语言表达带来的信息损失,为模型提供了更灵活的推理空间。
Part.02
Coconut 训练过程
现在让我们来介绍连续思维链方法的训练过程。这个过程旨在教会大语言模型如何在连续潜空间中进行推理。我们将使用论文中的下图,该图展示了训练过程的各个阶段。
 图|连续思维链多阶段训练过程
图|连续思维链多阶段训练过程
研究人员利用了现有的语言思维链作为模型的训练数据,类似于 Chain of Thought(CoT)的格式,其中每个样本包含一个问题(Question)、推理步骤(Step 1, Step 2, ...)和最终答案(Answer)。
训练过程分为多个阶段(Stage 0, Stage 1, Stage 2, ...),每个阶段逐步引入更多的连续思考([Thought]),并移除一个具体的推理步骤(Step)。在 Stage 0 阶段,训练数据没有引入任何连续思考,直接用原始的推理步骤和答案训练模型。在随后的阶段中,每个阶段都会从样本中移除一个推理步骤,并替换成连续思考 [Thought]。最终阶段,所有推理步骤都被替换为连续思考 [Thought],只保留答案部分用于计算损失。
Coconut的训练目标是在语言推理任务中逐步引入 [Thought],从而让模型获得 "连续思考"(Continuous Thought)的能力。其中分阶段的训练方式能够让模型能够逐步适应更复杂的推理任务,避免直接学习完整推理链条的困难。
Part.03
从潜在思维模式到语言模式的切换
模型如何确定何时从潜在思维模式切换到语言模式?研究人员探索了两种策略:
-
使用二元分类器对潜在思维进行判断来决定
-
使用固定数量的潜在思维
由于这两种策略都提供了相似的结果,研究人员出于简单性考虑,最终选择了使用固定数量的潜在思维进行实验。
Part.04
实验结果
现在让我们回顾论文中下表(Table 1)展示的一些结果,该表比较了Coconut方法与几个基准方法在三个数据集上的表现:GSM8K(数学问题)、ProntoQA(逻辑推理)和ProsQA(该数据集是为Coconut方法评估构建的,用于判断模型的规划能力)。
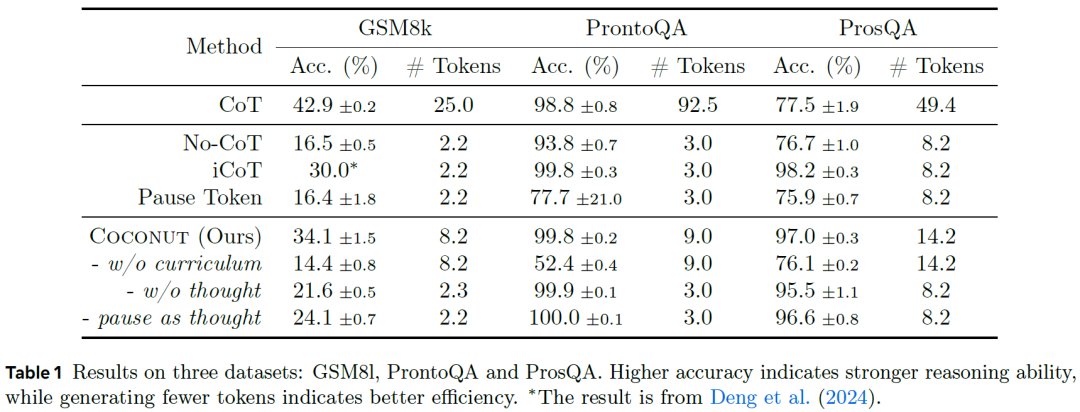 图|连续思维链实验结果
图|连续思维链实验结果
首先,将Coconut结果与No-CoT(一个直接生成答案而不进行思维链推理的LLM版本)进行比较,我们可以看到模型在潜空间进行连续思维显著提升了推理能力,因为Coconut在所有三个数据集上的表现都明显更好。
与CoT相比,我们发现CoT在数学问题上表现更好,但Coconut在需要强规划能力的ProsQA上明显更优(我们稍后会深入讨论这一点)。值得一提的是,与Coconut相比,CoT需要生成更多的token ,这使得Coconut更加高效。
另一个基准方法i-CoT也试图以不同方式内部化推理过程。我们可以看到,Coconut在数学问题上取得了更好的准确率,同时在其他两个数据集上表现相当。
这项研究中有一个有趣的结果是标记为"w/o curriculum"的实验,这个版本的模型仅使用训练的最后阶段(Stage N)的样本进行训练,这些样本只包含问题和答案,模型需要完全使用连续思维来解决整个问题,结果发现这个版本的实验得分明显较低。通过它,我们可以更加了解多阶段训练的重要性。
Part.05
BFS 式推理
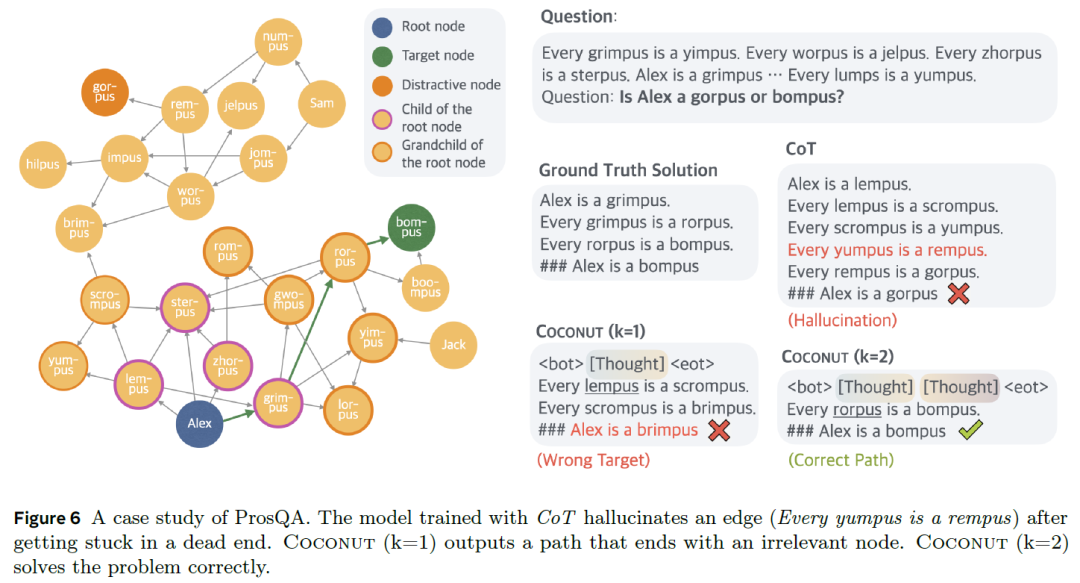
图|展示Coconut的BFS式推理能力的示例
在实验结果中,一个有趣的观察是潜在推理对规划密集型任务的益处。所有使用某种形式潜在推理的模型版本在ProsQA数据集上的表现都优于CoT,这个数据集相比其他两个数据集需要更复杂的规划。
让我们通过一个来自ProsQA数据集的案例研究来理解这一点。在图示中,我们可以看到:
- 右上方 [Question] 展示了如何建立各种内在关系,并询问可以从这些关系中推导出的连接
- 左侧显示了一个由问题定义的关系构建的图
论文中作者设计的问题是让模型确定Alex是gorpus还是bompus。测试结果表明,模型需要两步推理才能得出正确答案bompus。具体方法是通过从Alex节点进行图搜索,在两步内到达目标节点bompus,从而推导出正确答案。
使用标准思维链推理时,模型生成了关系网中一个不存在的内容,导致了错误的答案。我们还观察到,使用一个 [Thought] 的Coconut方法也得出了错误的结果,但使用两个 [Thought] 时,模型得到了正确答案。一个可能的解释是,Coconut允许模型在确定具体路径之前探索多个可能的分支,这种能力在某种程度上类似于广度优先搜索(Breadth-First Search,BFS)。
Part.06
结论与未来研究方向
让我们总结一下主要发现并探讨几个可能的未来研究方向。首先,Coconut方法显著增强了LLM的推理能力。我们在将结果与No-CoT版本比较时看到了这一点。其次,潜在空间推理使模型能够发展出类似BFS的推理模式,这帮助它在规划密集型任务上表现更好。
展望未来,有几个有趣的研究方向。一个可能的方向是使用连续思维对大语言模型进行预训练,而不是从标准预训练模型开始。另一个方向是优化Coconut的效率,以更好地处理多次前向传递的顺序性质。最后,将潜在思维与标准思维链结合,而不是替代它,可能允许同时获得两种方法的优势。尽管这需要更多的推理步骤。
📮 更多阅读



Linear Bolt Bolt 是线性资本为早期阶段、面向全球市场 AI 应用专门设立的投资项目。它秉持线性投资的理念和哲学,专注在技术驱动带来变革的项目,希望帮助创始人找到实现目标的最短路径,不管是行动速度,还是投资方式,Bolt 的承诺是更轻,更快,更灵活。Bolt 已经在 2024 年上半年投资了 Final Round、心光、Cathoven、Xbuddy、Midreal 等 7 个 AI 应用项目。