数据即模型,聊聊最近发布的小模型

当成本固定,数据质量就决定了模型质量

大模型现在似乎处在一个微妙的时刻。领先的前沿模型能力差不多,大家对下一代模型的能力突破有诸多期望。但能力再上一个台阶的前提要么是模型架构有突破,要么是成本至少再提高一个数量级,两者都不容易,于是隐约有些该来没来的味道。几周前我们看到了一系列小模型的密集发布,背后体现的一系列数据增强的努力,或许是某种意义上另一条提升模型能力和降低成本的路径探索。
从Scaling Law说起
今天的大模型能力能够不断提升,Scaling Law功不可没。它的美妙之处在于我们几乎什么都不需要做,不需要新架构,只要有钱,有数据,模型能力就能不断提升。
但是模型能力和数据之间是幂关系,因此越往后需要的数据量也越大。先不说总会看到"大模型什么时候会用完人类所有数据"的担心,如何使得这个幂关系更加经济也是个至少百亿美金的问题。另外,并不是所有的数据对模型能力的贡献都一样,在模型架构的下一个大跃进之前,模型的数据效率(perf/token trained)很大程度上取决于数据的质量。当成本固定,数据质量就决定了模型质量。
Huggingface SmolLM
几周前,Huggingface发布了一系列小模型SmolLM,参数量均在10亿以下,只需要几G内存,就可以在手机上运行。这个系列模型的一大亮点在于其训练效率,从发布的数据看,**SmolLM 135M/360M/1.7B模型在消耗训练数据token数远少于同级别模型的情况下,表现基本上达到了同级别最强,这背后主要的原因是在训练模型所用的数据集上。**SmolLM的发布原文中详细介绍了数据集的组成,包括目前开源数据当中模型训练表现最好的FineWeb,和迄今最大的用于预训练的合成数据集Cosmopedia v2。如果仔细看每一部分数据集的构造和优化方式,其中大量使用了大模型来过滤或生成数据。
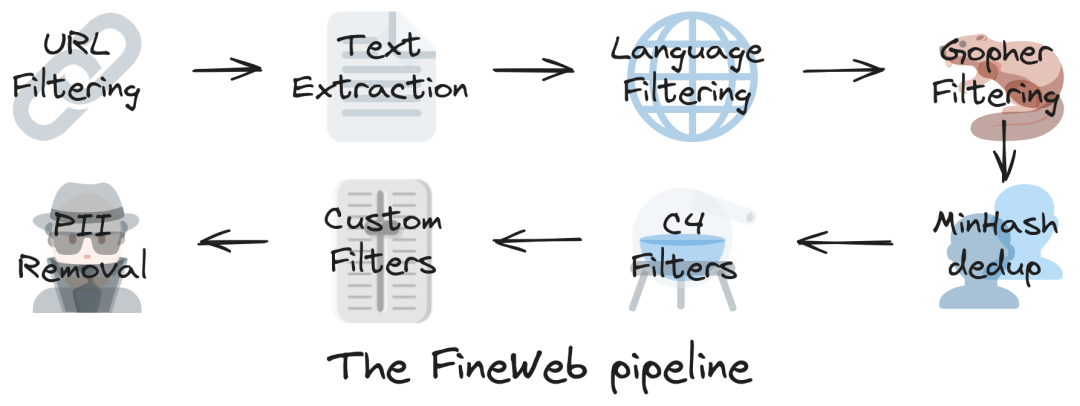
Apple DCLM
无独有偶,苹果最近发布的小模型DCLM-7B也采取了类似的视角。DCLM的工作主要是建立一个数据集优化的平台。而这次发布的DCLM-7B模型通过DCLM-Baseline数据训练而来,主要也是为了验证这个平台的效果。从训练模型的表现来看,DCLM数据集的效果非常优秀。DCLM-7B最后用了2.6T训练数据,在MMLU达到64%,和Llama 3 8B或Mistral-7B-v0.3差不多。其所用的训练数据还不到Llama 3 8B的六分之一。
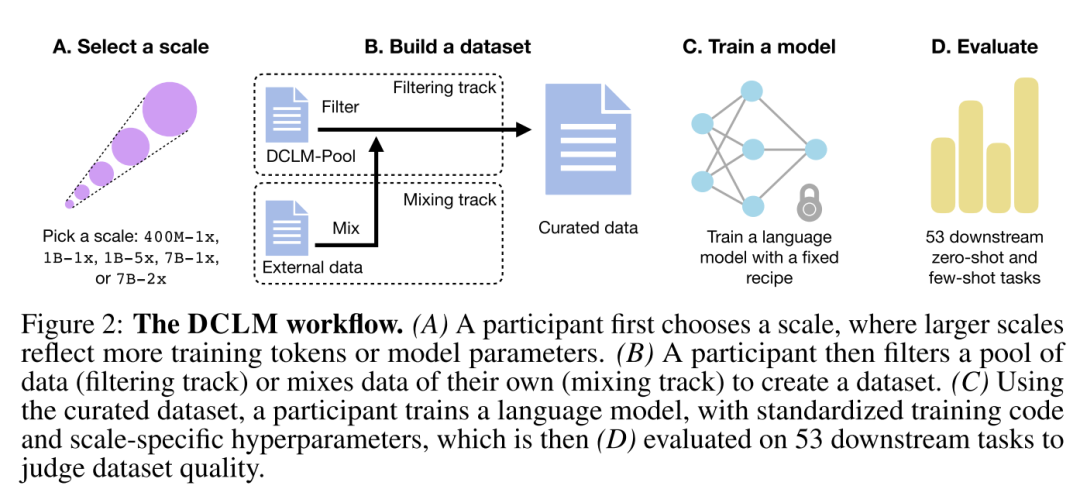
大模型+小模型:数据增强的飞轮
从SmolLM和DCLM的工作当中,我们可以看到非常清楚的想法:高质量的数据=高质量的模型。并且这背后也已经有一套严谨的数据优化方法论。
- 通过已有的大模型提供合成数据。包括直接生成数据或者过滤数据
- 对每个环节的不同选择,在控制其他环节不变的前提下,通过采样少量数据训练小模型来做快速的对比验证。
- 需要注意的是对比小模型的时候选取合适的标准至关重要,稳定(不受少量样本影响),单调(在数据集从小到大的过程中保持性能爬升),能够全面体现数据质量,但避免数据过拟合在这些指标上。
在这个方法论中大模型和合成数据扮演了数据和能力的供应角色,小模型则提供了快速验证的手段。这种大小模型结合的方式很自然地能形成一个飞轮式的数据优化流水线。与此遥相呼应,上周Llama 3.1 405B的开源也正为这个飞轮的上限提供了个重要的里程碑。
合成数据和模型质量
在这个问题上有一个常见的担心:在训练环节大量引入合成数据,会不会很快导致数据和得到的模型质量断崖下跌。实际上有两个角度看这个问题:
-
一是随着ChatGPT和大模型在互联网上越来越普及,**我们很难摆脱合成数据对数据集的影响。**FineWeb对历史上所有的CommonCrawl数据集做了分析,今年初开始ChatGPT生成内容的比例已经明显变高。至少目前这些数据的引入看起来没有显著影响模型能力。
-
二是我们在更大规模的合成数据中,一定会需要更可控和更长尾的采样,一方面保证数据的多样性,另一方面也保证生成数据的分布符合现实。随机生成的合成数据很容易在分布上对模型产生误导,从而影响模型在相关的具体任务上的能力。要解决这些问题,我们需要对至少下面一些方向做更多的探究:
-
如何方便地控制模型采样
-
数据分布与模型输出分布之间的双向关系,
-
基于训练数据(或者少量训练)快速预测模型的表现。
金钱战争 vs. 数据战争
数据永远是模型能力的根源。对数据集性能的提升,或者对特定模型的"最优"数据集的寻求一定会继续朝着更大体量合成数据集和训练更大体量模型的道路前进。如果说一线大模型在相当一段时间还是钱的战争——毕竟以两万张卡作为门票的游戏,不是拎个手提箱就能上牌桌的——中小体量模型实质上已经成为数据的战争,或者说数据质量的战争。我们能看到可公开获取的数据今天已经大量被使用,私有的内容平台数据越来越多地对模型训练封闭,随着数据越来越难以获得,数据增强以及前面讲的更基础的工作在可见的未来会越来越重要。
我的微信 Can_Zheng,欢迎加我讨论。
Linear Bolt Bolt 是线性资本为早期阶段、面向全球市场 AI 应用专门设立的投资项目。它秉持线性投资的理念和哲学,专注在技术驱动带来变革的项目,希望帮助创始人找到实现目标的最短路径,不管是行动速度,还是投资方式,Bolt 的承诺是更轻,更快,更灵活。Bolt 已经在 2024 年上半年投资了 Final Round、心光、Cathoven、Xbuddy、Midreal 等 7 个 AI 应用项目。